Musí být k dispozici mnoho výkonných nástrojů pro zálohování a obnovu PostgreSQL obecně; Barman, PgBackRest, BART jsou v této souvislosti alespoň některé. Co nás zaujalo, bylo, že Barman je nástroj, který rychle dohání produkční nasazení a trendy na trhu.
Ať už se jedná o nasazení založené na dockeru, potřebu ukládat zálohu do jiného cloudového úložiště nebo vysoce přizpůsobitelnou architekturu obnovy po havárii – Barman je ve všech těchto případech velmi silným soupeřem.
Tento blog zkoumá Barman s několika předpoklady ohledně nasazení, ale v žádném případě by to nemělo být považováno pouze za možnou sadu funkcí. Barman je daleko za tím, co můžeme zachytit v tomto blogu, a musí být prozkoumán dále, pokud se uvažuje o „zálohování a obnově instance PostgreSQL“.
Předpoklad připravenosti nasazení DR
RPO=0 obvykle něco stojí – synchronní nasazení serveru v pohotovostním režimu by to často splnilo, ale pak to má poměrně často dopad na TPS primárního serveru.
Stejně jako PostgreSQL nabízí Barman četné možnosti nasazení, které splní vaše potřeby, pokud jde o RPO vs výkon. Myslete na jednoduchost nasazení, RPO=0 nebo téměř nulový dopad na výkon; Barman se hodí ke všemu.
Zvažovali jsme následující nasazení, abychom vytvořili řešení pro obnovu po havárii pro naši architekturu zálohování a obnovy.
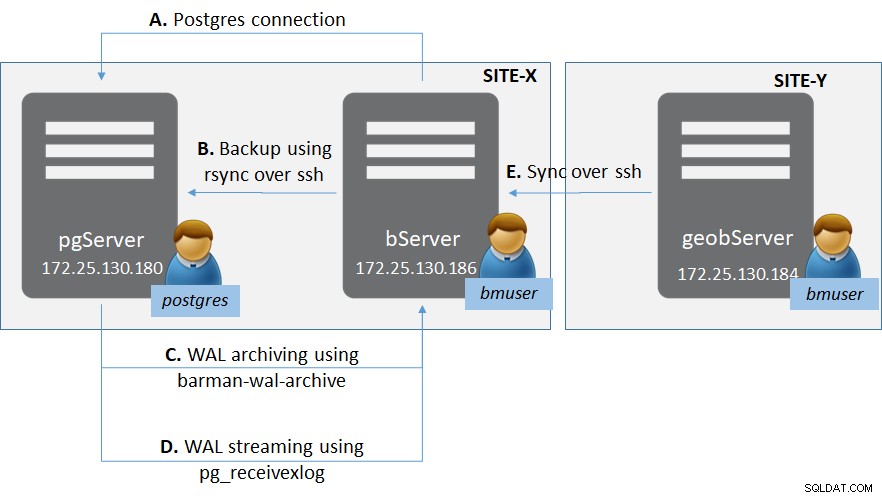 Obrázek 1:Nasazení PostgreSQL s Barman
Obrázek 1:Nasazení PostgreSQL s BarmanExistují dva weby (jako obecně pro místa obnovy po havárii) - Site-X a Site-Y.
V Site-X je:
- Jeden server ‚pgServer‘ hostující instanci serveru PostgreSQL pgServer a jeden uživatel OS ‚postgres‘
- Instance PostgreSQL také pro hostování role superuživatele ‚bmuser‘
- Jeden server ‚bServer‘ hostující binární soubory Barman a uživatel OS ‚bmuser‘
V Site-Y je:
- Jeden server ‚geobServer‘ hostující binární soubory Barman a uživatel OS ‚bmuser‘
Toto nastavení zahrnuje několik typů připojení.
- Mezi ‚bServer‘ a ‚pgServer‘:
- Konektivita na úrovni řízení od Barmana k instanci PostgreSQL
- připojení rsync k provedení skutečného základního zálohování z Barmana do instance PostgreSQL
- Archivace WAL pomocí archivu barman-wal-archive z PostgreSQL Instance to Barman
- Streamování WAL pomocí pg_receivexlog na Barman
- Mezi „bServer“ a „geobserver“:
- Synchronizace mezi servery Barman pro zajištění geografické replikace
Připojení jako první
Primární konektivita mezi servery je přes ssh. Aby to bylo možné, používají se ssh klíče bez hesla. Pojďme vytvořit ssh klíče a vyměnit je.
Na pgServeru:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Na bServeru:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Na geobServeru:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Konfigurace instance PostgreSQL
Jsou dvě hlavní věci, které potřebujeme k opětovnému vytvoření postgresové instance – základní adresář a poté vygenerované protokoly WAL / Transactions. Barman server je inteligentně sleduje. Co potřebujeme, je zajistit, aby byly pro Barmana generovány správné zdroje pro sběr těchto artefaktů.
Přidejte následující řádky do postgresql.conf:
listen_addresses = '172.25.130.180' #as per above deployment assumption
wal_level = replica #or higher
archive_mode = on
archive_command = 'barman-wal-archive -U bmuser bserver pgserver %p'Příkaz Archive zajišťuje, že když má být WAL archivována instancí postgres, nástroj barman-wal-archive jej odešle na Barman Server. Je třeba poznamenat, že balíček barman-cli by proto měl být zpřístupněn na ‚pgServeru‘. Pokud nechceme používat nástroj barman-wal-archive, existuje další možnost použití rsync.
Přidat následující do pg_hba.conf:
host all all 172.25.130.186/32 md5
host replication all 172.25.130.186/32 md5V podstatě umožňuje replikaci a normální připojení z ‚bmserveru‘ k této postgresové instanci.
Nyní stačí restartovat instanci a vytvořit roli superuživatele s názvem bmuser:
example@sqldat.com$ pg_ctl restart
example@sqldat.com$ createuser -s -P bmuser V případě potřeby se můžeme vyhnout použití bmuser jako superuživatele; to by vyžadovalo oprávnění přiřazená tomuto uživateli. Pro výše uvedený příklad jsme také použili bmuser jako heslo. Ale to je v podstatě vše, pokud je vyžadována konfigurace instance PostgreSQL.
Konfigurace barmana
Barman má ve své konfiguraci tři základní komponenty:
- Globální konfigurace
- Konfigurace na úrovni serveru
- Uživatel, který bude provozovat barmana
V našem případě, protože Barman je nainstalován pomocí rpm, máme naše globální konfigurační soubory uložené na adrese:
/etc/barman.confChtěli jsme uložit konfiguraci na úrovni serveru do domovského adresáře bmuser, proto měl náš globální konfigurační soubor následující obsah:
[barman]
barman_user = bmuser
configuration_files_directory = /home/bmuser/barman.d
barman_home = /home/bmuser
barman_lock_directory = /home/bmuser/run
log_file = /home/bmuser/barman.log
log_level = INFOKonfigurace primárního serveru Barman
Ve výše uvedeném nasazení jsme se rozhodli ponechat primární server Barman ve stejném datovém centru / místě, kde je uchovávána instance PostgreSQL. Výhodou téhož je, že v případě potřeby dochází k menšímu zpoždění a rychlejšímu zotavení. Netřeba dodávat, že i na serveru PostgreSQL jsou vyžadovány menší nároky na výpočetní techniku a/nebo šířku pásma sítě.
Aby Barman mohl spravovat instanci PostgreSQL na pgServeru, musíme přidat konfigurační soubor (pojmenovali jsme pgserver.conf) s následujícím obsahem:
[pgserver]
description = "Example pgserver configuration"
ssh_command = ssh example@sqldat.com
conninfo = host=pgserver user=bmuser dbname=postgres
backup_method = rsync
reuse_backup = link
backup_options = concurrent_backup
parallel_jobs = 2
archiver = on
archiver_batch_size = 50
path_prefix = "/usr/pgsql-12/bin"
streaming_conninfo = host=pgserver user=bmuser dbname=postgres
streaming_archiver=on
create_slot = autoA soubor .pgpass obsahující přihlašovací údaje pro bmuser v instanci PostgreSQL:
echo 'pgserver:5432:*:bmuser:bmuser' > ~/.pgpass Chcete-li trochu více porozumět důležitým konfiguračním položkám:
- ssh_command :Používá se k navázání připojení, přes které bude provedena synchronizace
- conninfo :Připojovací řetězec, který umožní Barmanovi navázat spojení se serverem postgres
- reuse_backup :Chcete-li povolit přírůstkové zálohování s menším úložištěm
- metoda_zálohování :metoda zálohování základního adresáře
- prefix_cesty :umístění, kde jsou uloženy binární soubory pg_receivexlog
- streaming_conninfo :Připojovací řetězec používaný ke streamování WAL
- create_slot :Aby se zajistilo, že sloty byly vytvořeny instancí postgres
Konfigurace serveru pasivního barmana
Konfigurace webu pro geografickou replikaci je velmi jednoduchá. Vše, co potřebuje, jsou informace o připojení ssh, přes které bude tento pasivní uzel provádět replikaci.
Zajímavé je, že takový pasivní uzel může pracovat v mix-režimu; jinými slovy - mohou fungovat jako aktivní servery Barman pro zálohování stránek PostgreSQL a paralelně fungovat jako replikační/kaskádové stránky pro jiné servery Barman.
Protože v našem případě tato instance Barmana (na webu-Y) musí být pouze pasivním uzlem, potřebujeme pouze vytvořit soubor /home/bmuser/barman.d/pgserver.conf s následující konfigurací:
[pgserver]
description = "Geo-replication or sync for pgserver"
primary_ssh_command = ssh example@sqldat.comZa předpokladu, že došlo k výměně klíčů a globální konfigurace na tomto uzlu je provedena tak, jak bylo zmíněno výše - jsme s konfigurací téměř hotovi.
A zde je naše první zálohování a obnovení
Na bserveru se ujistěte, že byl spuštěn proces příjmu WAL na pozadí; a poté zkontrolujte konfiguraci serveru:
example@sqldat.com$ barman cron
example@sqldat.com$ barman check pgserverKontrola by měla být v pořádku u všech dílčích kroků. Pokud ne, přejděte na /home/bmuser/barman.log.
Vydejte na Barmanu záložní příkaz, abyste zajistili, že existují základní DATA, na která lze použít WAL:
example@sqldat.com$ barman backup pgserverNa ‚geobmserver‘ zajistěte, aby se replikace provedla provedením následujících příkazů:
example@sqldat.com$ barman cron
example@sqldat.com$ barman list-backup pgserverCron by měl být vložen do souboru crontab (pokud není přítomen). Pro jednoduchost jsem to zde neukázal. Poslední příkaz ukáže, že záložní složka byla vytvořena i na geobmserveru.
Nyní v instanci Postgres vytvoříme nějaká fiktivní data:
example@sqldat.com$ psql -U postgres -c "CREATE TABLE dummy_data( i INTEGER);"
example@sqldat.com$ psql -U postgres -c "insert into dummy_data values ( generate_series (1, 1000000 ));"Replikaci WAL z instance PostgreSQL lze zobrazit pomocí příkazu níže:
example@sqldat.com$ psql -U postgres -c "SELECT * from pg_stat_replication ;”Chcete-li znovu vytvořit instanci na webu-Y, nejprve se ujistěte, že jsou záznamy WAL přepnuty. nebo tento příklad pro vytvoření čisté obnovy:
example@sqldat.com$ barman switch-xlog --force --archive pgserverNa webu Site-X vyvolejte samostatnou instanci PostgreSQL, abyste zkontrolovali, zda je zálohování rozumné:
example@sqldat.com$ barman cron
barman recover --get-wal pgserver latest /tmp/dataNyní upravte soubory postgresql.conf a postgresql.auto.conf podle potřeby. Následující vysvětlí změny provedené v tomto příkladu:
- postgresql.conf :listen_addresses okomentovány jako výchozí localhost
- postgresql.auto.conf :odstraněn sudo bmuser z příkazu restore_command
Vyvolejte tato DATA v /tmp/data a zkontrolujte existenci vašich záznamů.
Závěr
Toto byla jen špička ledovce. Barman je mnohem hlubší než toto kvůli funkcím, které poskytuje - např. fungující jako synchronizovaný pohotovostní režim, hákové skripty a tak dále. Netřeba dodávat, že je třeba prozkoumat celou dokumentaci, abyste ji nakonfigurovali podle potřeb vašeho produkčního prostředí.