Téma ukládání do mezipaměti se objevilo v PostgreSQL již před 22 lety a v té době byl kladen důraz na spolehlivost databáze.
Rychle vpřed do roku 2020 jsou diskové plotny skryty ještě hlouběji ve virtualizovaných prostředích, hypervizorech a souvisejících úložných zařízeních. Kromě toho propojené, distribuované aplikace fungující v globálním měřítku volají po připojení s nízkou latencí a najednou ladění mezipaměti serveru a dotazy SQL soutěží o to, aby se výsledky vrátily klientům během milisekund. Rodí se mezipaměti na úrovni aplikace a v paměti a čtené dotazy se nyní ukládají v blízkosti aplikačních serverů. V důsledku toho jsou I/O operace omezeny pouze na zápisy a latence sítě se dramaticky zlepšila. S jedním úlovkem. Implementace jsou zodpovědné za vlastní správu mezipaměti, což někdy vede ke snížení výkonu.
Ukládání zápisů do mezipaměti je mnohem složitější záležitost, jak je vysvětleno na wiki PostgreSQL.
Tento blog je přehledem mezipaměti dotazů v paměti a nástrojů pro vyrovnávání zatížení, které se používají s PostgreSQL.
Vyrovnávání zátěže PostgreSQL
Myšlenka vyvažování zátěže vznikla ve stejné době jako ukládání do mezipaměti, v roce 1999, kdy Bruce Momjiam napsal:
[...] je možné, že budeme v blízké budoucnosti _velmi_ populární.
Základ pro implementaci vyvažování zátěže v PostgreSQL poskytuje vestavěná funkce Hot Standby. Jediným požadavkem je, aby aplikace zvládla převzetí služeb při selhání, a zde přicházejí na řadu řešení třetích stran. Na některá z těchto řešení se podíváme v dalších částech.
Dotazy s vyváženým zatížením mohou vracet konzistentní výsledky, pouze pokud je zpoždění synchronní replikace udržováno na nízké úrovni. V praxi může dokonce i nejmodernější síťová infrastruktura, jako je AWS, vykazovat zpoždění v řádu desítek milisekund:
Obvykle pozorujeme prodlevy v řádu 10 s v milisekundách. [...] Za typických podmínek je však prodleva replikace pod minutu běžná. [...]
Repliky napříč oblastmi využívající logickou replikaci budou ovlivněny rychlostí změn/použití a zpožděním v síťové komunikaci mezi konkrétními vybranými oblastmi. Mezioblastní repliky využívající Aurora Global Database budou mít typické zpoždění pod sekundu.
Jak již bylo uvedeno dříve, řešení třetích stran spoléhají na základní funkce PostgreSQL. Například vyrovnávání zátěže čtených dotazů je dosaženo pomocí více synchronních pohotovostních režimů.
Řešení
pgpool-II
pgpool-II je produkt bohatý na funkce, který poskytuje jak vyrovnávání zátěže, tak ukládání dotazů do mezipaměti. Jedná se o výměnu typu drop-in, nejsou nutné žádné změny na straně aplikace.
Jako nástroj pro vyrovnávání zátěže zkoumá pgpool-II každý SQL dotaz — aby byly SELECT dotazy vyrovnány, musí splňovat několik podmínek.
Nastavení může být jednoduché jako jeden uzel, níže je uveden cluster se dvěma uzly:
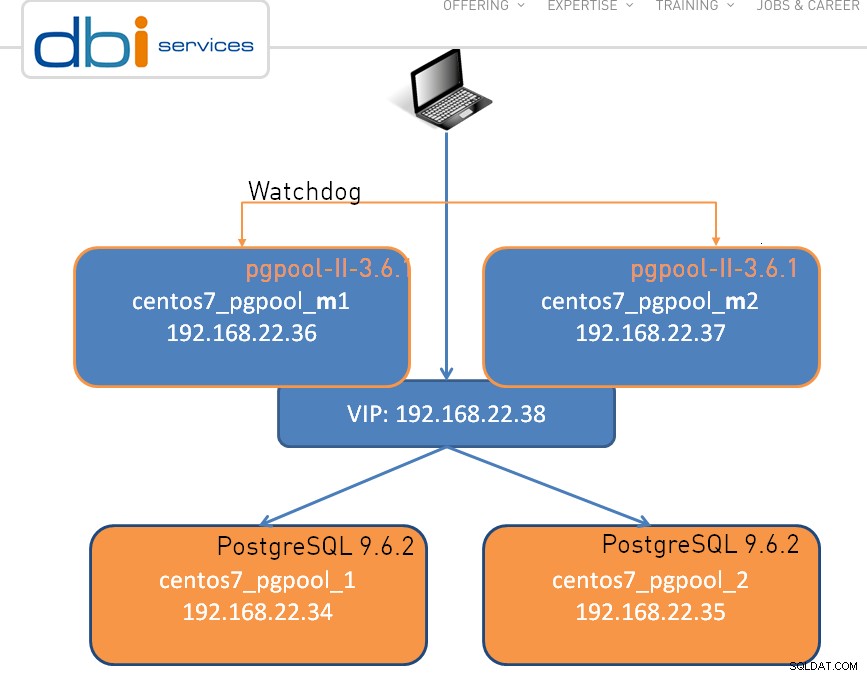
Jako u každého skvělého softwaru existují určitá omezení a pgpool-II nedělá žádnou výjimku:
- Nezpracovává dotazy s více příkazy.
- SELECT dotazy na dočasné tabulky vyžadují komentář /*NO LOAD BALANCE*/ SQL.
Aplikace běžící ve vysoce výkonných prostředích budou těžit ze smíšené konfigurace, kde pgBouncer je sdružovač připojení a pgpool-II se stará o vyrovnávání zátěže a ukládání do mezipaměti. Výsledkem je působivé čtyřnásobné zvýšení propustnosti a 40procentní snížení latence:
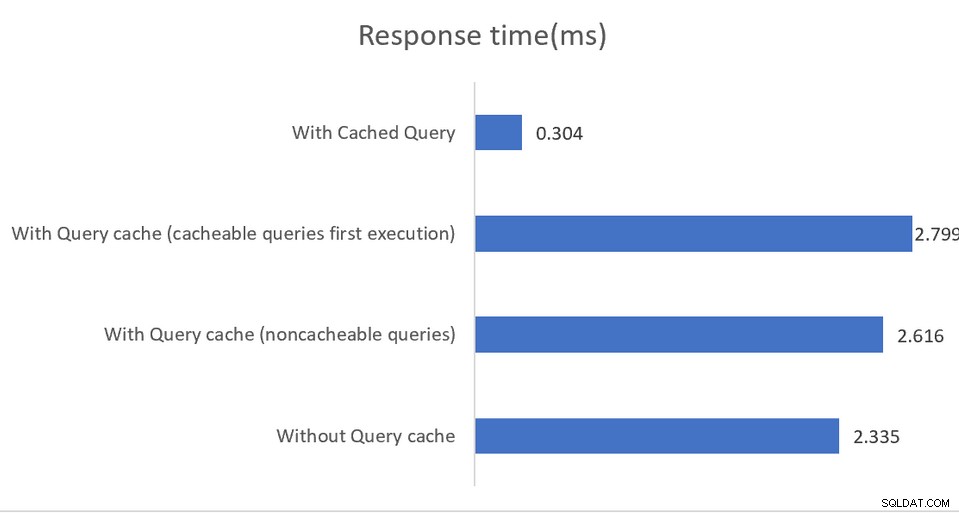
Ukládání do mezipaměti funguje opět pouze při čtení dotazů s mezipamětí data se ukládají buď do sdílené paměti nebo do externí instalace s memcached. I když dokumentace docela dobře vysvětluje různé možnosti konfigurace, nepřímo naznačuje, že implementace musí monitorovat výstup SHOW POOL CACHE, aby upozornily na poměry zásahů, které klesnou pod značku 70 %, v tomto okamžiku se zisk z mezipaměti ztratí.
Bucardo
Bucardo je replikační nástroj PostgreSQL napsaný v Perlu a PL/Perlu.
Zmínil jsem Bucardo, protože vyrovnávání zátěže je jednou z jeho funkcí, podle PostgreSQL wiki však vyhledávání na internetu nepřináší žádné relevantní výsledky. Abych to upřesnil, zamířil jsem k oficiální dokumentaci, která podrobně popisuje, jak software skutečně funguje:

Z toho je docela jasné, že Bucardo není nástroj pro vyrovnávání zatížení, stejně jako ukázali lidé z Database Soup.
HAProxy
HAProxy je nástroj pro vyrovnávání zatížení pro obecné účely, který funguje na úrovni TCP (pro účely databázových připojení). Kontroly stavu zajišťují, že dotazy jsou odesílány pouze na živé uzly.
Ve srovnání s pgpool-II musí být aplikace využívající HAProxy jako nástroj pro vyrovnávání zatížení informovány o tom, že koncové body odesílají požadavky čtecím uzlům.
Apache Ignite
Apache Ignite je mezipaměť druhé úrovně, která rozumí ANSI-99 SQL a poskytuje podporu pro transakce ACID. Apache Ignite nerozumí PostgreSQL Frontend/Backend Protocol, a proto musí aplikace používat buď perzistentní vrstvu, jako je Hibernate ORM. Jako alternativu k úpravám aplikací poskytuje Apache Ignite `integraci memcached`_, která vyžaduje rozšíření PostgreSQL memcached. Bohužel tato druhá možnost není kompatibilní s nejnovějšími verzemi PostgreSQL, protože rozšíření pgmemcache bylo naposledy aktualizováno v roce 2017.
Údaje Heimdall
Jako komerční produkt Heimdall Data zaškrtává obě políčka:vyrovnávání zátěže a ukládání do mezipaměti. Je to vyzrálý produkt, který byl představen na konferencích PostgreSQL již na PGCon 2017:

Další podrobnosti a ukázku produktu najdete na blogu Azure for PostgreSQL .
Závěr
V dnešních distribuovaných výpočtech jsou Query Caching a Load Balancing pro ladění výkonu PostgreSQL stejně důležité jako dobře známé GUC, jádro OS, úložiště a optimalizace dotazů. Zatímco pgpool-II a Heimdall Data jsou open source, respektive komerčně preferovaná řešení, existují případy, kdy lze jako stavební kameny k dosažení podobných výsledků použít účelově vyrobené nástroje.