V našich předchozích blozích jsme zdůvodnili, proč potřebujete převzetí služeb při selhání databáze, a vysvětlili jsme, jak mechanismus převzetí služeb při selhání funguje. Sdílím to v případě, že máte otázky, proč byste měli nastavit mechanismus převzetí služeb při selhání pro vaši databázi MySQL. Pokud ano, přečtěte si prosím naše předchozí příspěvky na blogu.
Jak nastavit automatické převzetí služeb při selhání
Výhodou použití MySQL nebo MariaDB pro automatickou správu vašeho převzetí služeb při selhání je, že existují dostupné nástroje, které můžete použít a implementovat ve svém prostředí. Od open source až po podniková řešení. Většina nástrojů je nejen schopná převzetí služeb při selhání, ale existují i další funkce, jako je přepínání, monitorování a pokročilé funkce, které mohou nabídnout více možností správy vašeho databázového clusteru MySQL. Níže si projdeme ty nejběžnější, které můžete použít.
Použití MHA (Master High Availability)
Toto téma jsme převzali s MHA s jeho nejčastějšími problémy a jak je opravit. Porovnali jsme také MHA s MRM nebo s MaxScale.
Nastavení pomocí MHA pro vysokou dostupnost nemusí být snadné, ale jeho použití je efektivní a flexibilní, protože existují laditelné parametry, které můžete definovat a přizpůsobit tak své převzetí služeb při selhání. MHA byl testován a používán. Ale jak technologie postupuje, MHA zaostává, protože nepodporuje GTID pro MariaDB a poslední 2 nebo 3 roky neprosazuje žádné aktualizace.
Spuštěním skriptu masterha_manager,
masterha_manager --conf=/etc/app1.cnfVzorový soubor /etc/app1.cnf by měl vypadat následovně
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parametry, jako je no_master a kandidát_master, budou klíčové, když nastavíte přidání požadovaných uzlů na seznam povolených uzlů jako cílových uzlů a uzlů, které být hlavními nechcete.
Po nastavení jste připraveni na převzetí služeb při selhání pro vaši databázi MySQL v případě, že dojde k selhání na primární nebo hlavní. Skript masterha_manager spravuje převzetí služeb při selhání (automatické nebo manuální), přijímá rozhodnutí o tom, kdy a kde se má převzít při selhání, a spravuje obnovu podřízených jednotek během povýšení kandidáta hlavního serveru pro použití protokolů rozdílového přenosu. Pokud hlavní databáze zemře, MHA Manager se zkoordinuje s agentem MHA Node, protože použije protokoly rozdílového přenosu na podřízené jednotky, které nemají nejnovější události binárního protokolu z hlavní.
Podívejte se, co dělá agent MHA Node a jaké jsou jeho skripty. V podstatě je to skript, který MHA Manager vyvolá, když dojde k převzetí služeb při selhání. Bude čekat na svůj mandát od MHA Managera, když hledá nejnovější slave zařízení, které obsahuje události binlog a kopíruje chybějící události z slave pomocí scp a aplikuje je na sebe. Jak již bylo zmíněno, použije protokoly přenosu, vyčistí protokoly přenosu nebo uloží binární protokoly.
Pokud se chcete dozvědět více o laditelných parametrech a jak si přizpůsobit správu převzetí služeb při selhání, podívejte se na wiki stránku Parametry pro MHA.
Používání nástroje Orchestrator
Orchestrator je nástroj pro správu MySQL a MariaDB s vysokou dostupností a replikací. Vydává ho Shlomi Noach za podmínek licence Apache, verze 2.0. Jedná se o software s otevřeným zdrojovým kódem a zvládá automatické převzetí služeb při selhání, ale kromě obnovy nebo automatického převzetí služeb při selhání existuje mnoho věcí, které můžete upravit nebo udělat pro správu databáze MySQL/MariaDB.
Instalace Orchestratoru může být snadná nebo přímočará. Jakmile si stáhnete konkrétní balíčky požadované pro vaše cílové prostředí, jste připraveni zaregistrovat svůj cluster a uzly, které budou monitorovány Orchestratorem. Poskytuje uživatelské rozhraní, pro které se to velmi snadno spravuje, ale má spoustu laditelných parametrů nebo sadu příkazů, které můžete použít k dosažení správy převzetí služeb při selhání.
Předpokládejme, že jste konečně nastavili a Registraci clusteru přidáním našeho primárního nebo hlavního uzlu lze provést pomocí příkazu níže,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Nyní jsme přidali náš cluster.
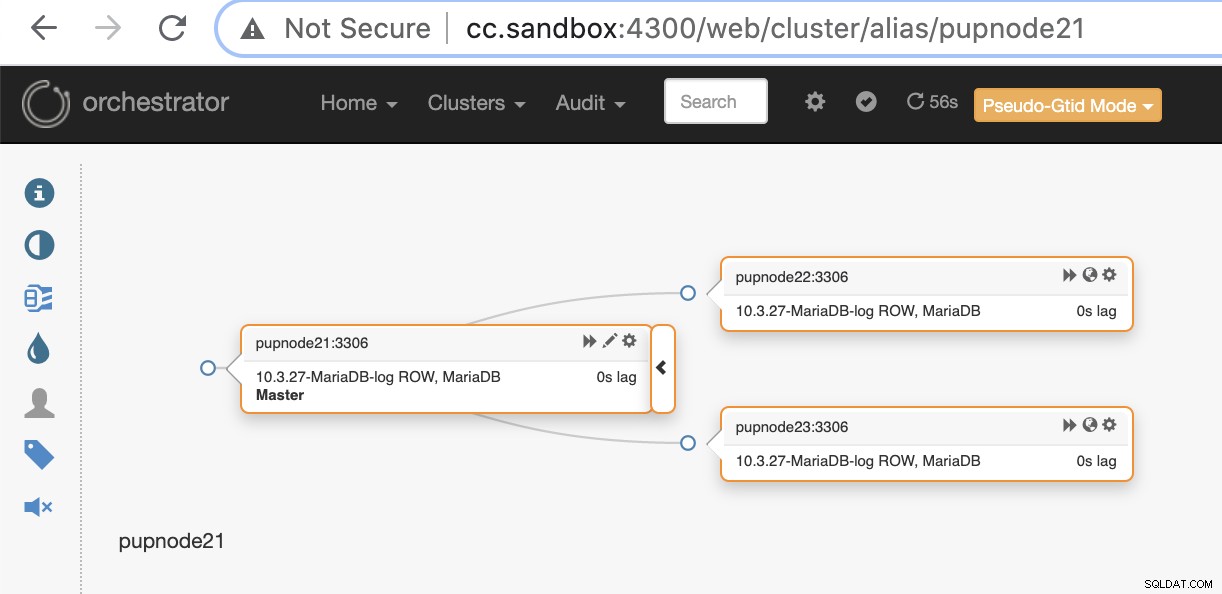
Pokud primární uzel selže (selhání hardwaru nebo došlo k havárii), Orchestrator detekovat a najít nejpokročilejší uzel, který má být povýšen jako primární nebo hlavní uzel.
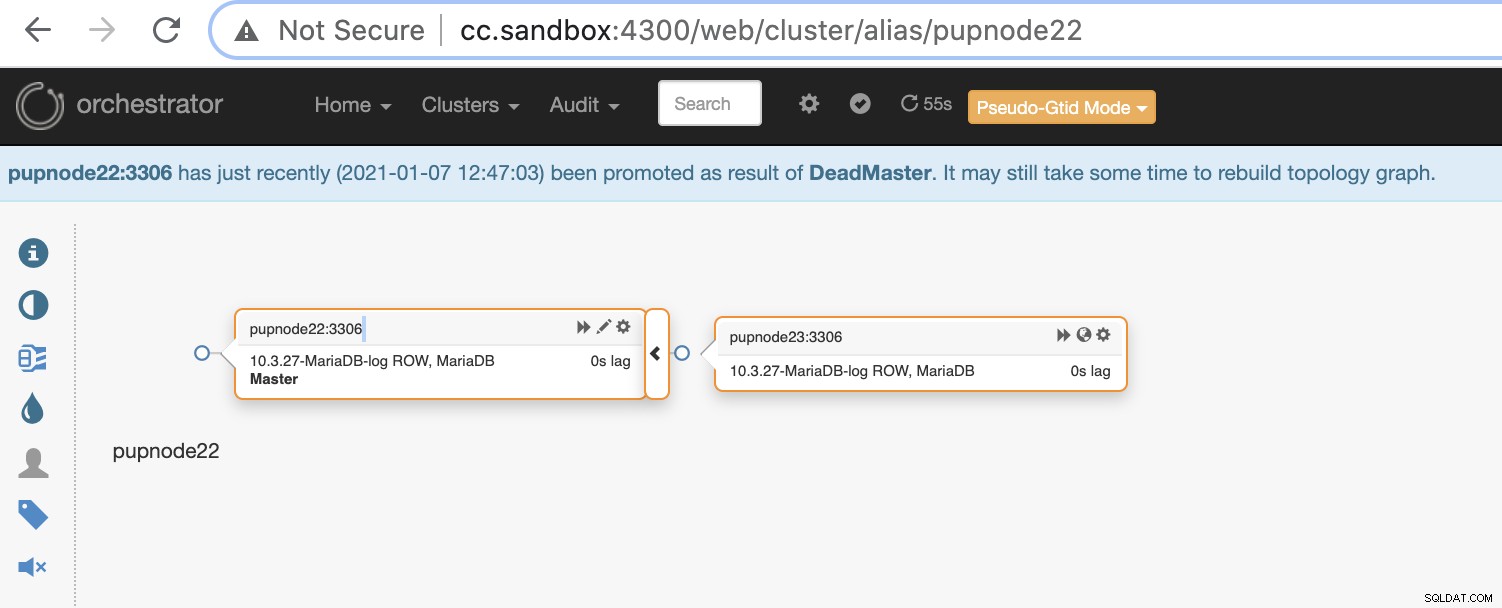
Nyní nám v clusteru zbývají dva uzly, zatímco primární je mimo provoz .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Použití MaxScale
MariaDB MaxScale byla podporována jako nástroj pro vyrovnávání zatížení databáze. V průběhu let MaxScale rostl a dozrával, rozšířil se o několik bohatých funkcí, včetně automatického převzetí služeb při selhání. Od vydání MariaDB MaxScale 2.2 přináší několik nových funkcí včetně správy převzetí služeb při selhání replikačního clusteru. Můžete si přečíst náš předchozí blog o mechanismu převzetí služeb při selhání MaxScale.
Použití MaxScale je pod BSL, ačkoli software je volně dostupný, ale vyžaduje, abyste si alespoň koupili službu s MariaDB. Nemusí to být vhodné, ale v případě, že jste získali podnikové služby MariaDB, může to být velká výhoda, pokud požadujete správu převzetí služeb při selhání a její další funkce.
Instalace MaxScale je snadná, ale nastavení požadované konfigurace a definování jejích parametrů nikoli a vyžaduje to, abyste rozuměli softwaru. Můžete se podívat do jejich konfiguračního průvodce.
Pro rychlé a rychlé nasazení můžete použít ClusterControl k instalaci MaxScale do vašeho stávajícího prostředí MySQL/MariaDB.
Po instalaci lze databázi Moodle nastavit nasměrováním vašeho hostitele na MaxScale IP nebo název hostitele a port pro čtení a zápis. Například,
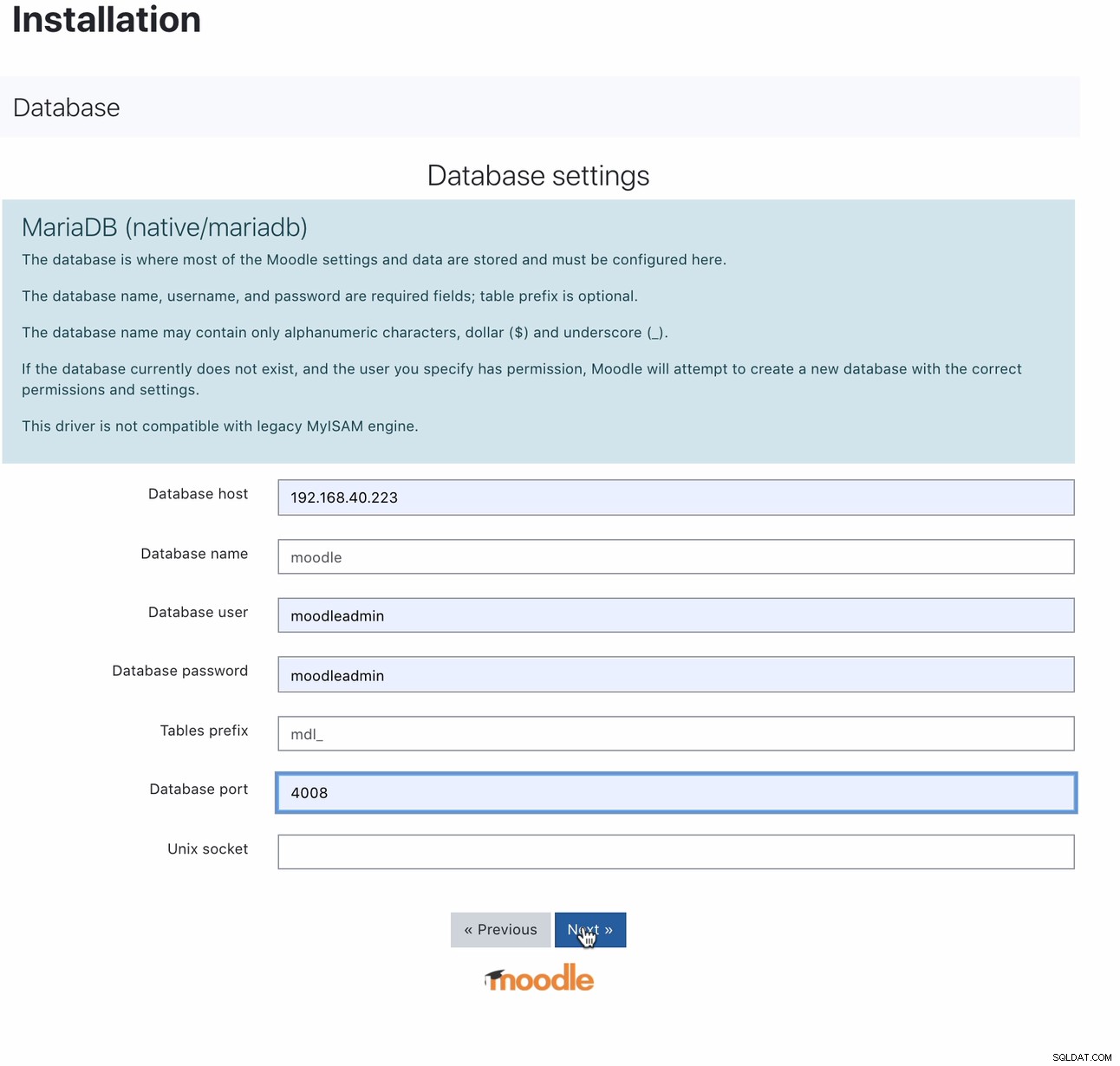
Pro který port 4008 je vaše služba pro čtení a zápis pro posluchače služeb. Zde je například následující konfigurace služby a posluchače pro můj MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falsePři konfiguraci monitoru nesmíte zapomenout povolit automatické převzetí služeb při selhání nebo také povolit automatické opětovné připojení, pokud chcete, aby se předchozí hlavní server při návratu do režimu online automaticky znovu nepřipojil. Jde to takto,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Vezměte na vědomí, že proměnné, které jsem uvedl, nejsou určeny pro produkční použití, ale pouze pro tento blogový příspěvek a testovací účely. Dobrá věc s MaxScale je, že jakmile primární nebo hlavní selže, MaxScale je dostatečně chytrý, aby propagoval ideálního nebo nejlepšího kandidáta, aby převzal roli hlavního. Není tedy třeba měnit vaši IP a port, protože jsme použili hostitele/IP našeho uzlu MaxScale a jeho port jako náš koncový bod, jakmile master selže. Například,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Uzel DB_123, který ukazuje na 192.168.40.221, je aktuální hlavní server. Ukončení uzlu DB_123 spustí MaxScale k provedení převzetí služeb při selhání a bude to vypadat takto,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Zatímco naše databáze Moodle je stále v provozu, protože naše MaxScale ukazuje na nejnovější master, který byl povýšen.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Použití ClusterControl
ClusterControl lze stáhnout zdarma a nabízí licence pro Community, Advance a Enterprise. Automatické převzetí služeb při selhání je dostupné pouze na Advance a Enterprise. Automatické převzetí služeb při selhání je zahrnuto v naší funkci automatického obnovení, která se pokouší obnovit selhání clusteru nebo selhání uzlu. Pokud chcete další podrobnosti o tom, jak to provést, podívejte se na náš předchozí příspěvek Jak ClusterControl provádí automatické obnovení databáze a převzetí služeb při selhání. Nabízí laditelné parametry, které jsou velmi pohodlné a snadno použitelné. Přečtěte si prosím náš předchozí příspěvek také o tom, jak automatizovat selhání databáze pomocí ClusterControl.
Správa vašeho automatického převzetí služeb při selhání pro vaši databázi Moodle musí vyžadovat alespoň virtuální IP (VIP) jako koncový bod pro vašeho aplikačního klienta Moodle propojujícího váš databázový backend. Chcete-li to provést, můžete nasadit Keepalived s HAProxy (nebo ProxySQL - v závislosti na vaší volbě nástroje pro vyrovnávání zatížení). V tomto případě bude koncový bod vaší databáze Moodle ukazovat na virtuální IP, kterou v podstatě přiřadí Keepalived, jakmile ji nasadíte, stejně jako jsme vám ukázali dříve při nastavování MaxScale. Můžete se také podívat na tento blog, jak to udělat.
Jak je uvedeno výše, jsou k dispozici laditelné parametry, které můžete jednoduše nastavit pomocí souboru /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- černá listina_failover_replication
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl je velmi flexibilní při správě převzetí služeb při selhání, takže můžete provádět některé úlohy před nebo po přepnutí při selhání.
Závěr
Existují další skvělé možnosti při nastavování a automatické správě vašeho převzetí služeb při selhání pro vaši databázi MySQL pro Moodle. Záleží na vašem rozpočtu a na tom, za co budete pravděpodobně muset utratit peníze. Používání open source vyžaduje odborné znalosti a vyžaduje vícenásobné testování, abyste se seznámili, protože neexistuje žádná podpora, kterou byste mohli spustit, když potřebujete pomoc, kromě komunity. S podnikovými řešeními přichází s cenou, ale nabízí vám podporu a snadnost, protože časově náročná práce může být snížena. Uvědomte si, že pokud je převzetí služeb při selhání použito omylem, může to stát poškození vaší databáze, pokud není správně zpracováno a spravováno. Zaměřte se na to, co je důležitější, a na to, jak jste schopni řešení, která používáte pro správu selhání vaší databáze Moodle.