V předchozím příspěvku na blogu jsme se zabývali základy škálování – co to je, jaké jsou typy, co musíte mít, pokud chceme škálovat. Tento blogový příspěvek se zaměří na výzvy a způsoby, jakými můžeme škálovat.
Výzva změny měřítka
Škálování databází není nejjednodušší úkol z několika důvodů. Pojďme se trochu zaměřit na výzvy související s rozšířením vaší databázové infrastruktury.
Státní služba
Rozlišujeme dva různé typy služeb:bezstavové a stavové. Bezstavové služby jsou ty, které se nespoléhají na žádný druh existujících dat. Můžete prostě pokračovat, spustit takovou službu a bude to šťastně fungovat. O stav dat ani služby se nemusíte starat. Pokud je aktivní, bude fungovat správně a můžete snadno rozložit provoz mezi více instancí služeb pouhým přidáním dalších klonů nebo kopií stávajících virtuálních počítačů, kontejnerů nebo podobných. Příkladem takové služby může být webová aplikace – nasazená z repo, má správně nakonfigurovaný webový server a taková služba se prostě spustí a bude správně fungovat.
Problém s databázemi je v tom, že databáze je všechno, jen ne bezstavová. Data musí být vložena do databáze, musí být zpracována a uchována. Obraz databáze není nic jiného než jen pár balíčků nainstalovaných přes obraz OS a bez dat a správné konfigurace je spíše k ničemu. To zvyšuje složitost škálování databáze. U bezstavových služeb je stačí nasadit a nakonfigurovat některé loadbalancery, aby do pracovní zátěže zahrnuly nové instance. Pro databáze nasazující databázi je instance pouze výchozím bodem. Dále v pruhu je správa dat - musíte přenést data ze stávající instance databáze do nové. To může být podstatná část problému a čas potřebný k tomu, aby nové instance začaly s provozem. Teprve po přenosu dat můžeme nastavit nové uzly tak, aby se staly součástí stávající topologie replikace – data je na nich třeba aktualizovat v reálném čase na základě provozu, který se dostává k jiným uzlům.
Čas potřebný pro zvětšení
Skutečnost, že databáze jsou stavové služby, je přímým důvodem pro druhou výzvu, které čelíme, když chceme škálovat databázovou infrastrukturu. Bezstavové služby – stačí je spustit a je to. Je to docela rychlý proces. U databází musíte data přenést. Jak dlouho to bude trvat, záleží na více faktorech. Jak velký je soubor dat? Jak rychlé je ukládání? Jak rychlá je síť? Jaké jsou další kroky potřebné k poskytnutí nových dat novému uzlu? Jsou data v tomto procesu komprimována/dekomprimována nebo šifrována/dešifrována? V reálném světě může poskytování dat na novém uzlu trvat minuty až několik hodin. To vážně omezuje případy, kdy můžete škálovat prostředí databáze. Náhlé, dočasné výkyvy zátěže? Ne ve skutečnosti, mohou být dávno pryč, než budete moci spustit další databázové uzly. Náhlé a trvalé zvýšení zátěže? Ano, bude možné se s tím vypořádat přidáním dalších uzlů, ale může trvat i hodiny, než je vyvoláte a necháte je převzít provoz ze stávajících databázových uzlů.
Další zátěž způsobená procesem zvětšování
Je velmi důležité mít na paměti, že čas potřebný k navýšení je pouze jednou stranou problému. Druhou stranou je zátěž způsobená procesem škálování. Jak jsme již zmínili, musíte přenést celý soubor dat do nově přidaných uzlů. To není něco, co byste mohli ignorovat, koneckonců to může být hodinový proces načítání dat z disku, jejich odesílání po síti a ukládání na nové místo. Pokud je dárce, uzel, ze kterého čtete data, přetížený, musíte zvážit, jak se bude chovat, pokud bude nucen provádět další těžké I/O aktivity? Bude váš cluster schopen převzít další pracovní zatížení, pokud je již pod velkým tlakem a je rozprostřen? Odpověď nemusí být snadné získat, protože zatížení uzlů může mít různé formy. Zatížení vázané na CPU bude nejlepším scénářem, protože I/O aktivita by měla být nízká a další diskové operace budou zvládnutelné. Na druhou stranu zátěž vázaná na I/O může výrazně zpomalit přenos dat, což má vážný dopad na schopnost clusteru škálovat.
Měřítko zápisu
Proces škálování, který jsme zmínili dříve, je do značné míry omezen na škálování čtení. Je prvořadé pochopit, že škálování zápisů je úplně jiný příběh. Čtení můžete škálovat jednoduchým přidáním více uzlů a rozložením čtení mezi více backendových uzlů. Zápisy není tak snadné škálovat. Pro začátek nemůžete škálovat zápisy jen tak. Každý uzel, který obsahuje celou datovou sadu, je samozřejmě povinen zpracovávat všechny zápisy prováděné někde v clusteru, protože pouze aplikací všech úprav na datovou sadu může zachovat konzistenci. Takže, když o tom přemýšlíte, bez ohledu na to, jak navrhujete svůj cluster a jakou technologii používáte, každý člen clusteru musí provést každý zápis. Ať už se jedná o repliku, replikující všechny zápisy ze svého hlavního nebo uzlu v multimaster clusteru, jako je Galera nebo InnoDB Cluster, provádějící všechny změny datové sady provedené na všech ostatních uzlech clusteru, výsledek je stejný. Zápisy se neškálují jednoduše přidáním více uzlů do clusteru.
Jak můžeme škálovat databázi?
Víme tedy, jakým výzvám čelíme. Jaké máme možnosti? Jak můžeme rozšířit databázi?
Přidáním replik
V první řadě budeme škálovat jednoduše přidáním dalších uzlů. Jistě, zabere to čas a jistě, není to proces, od kterého můžete očekávat, že se stane okamžitě. Jistě, nebudete moci takto škálovat zápisy. Na druhou stranu nejtypičtějším problémem, kterému budete čelit, je zatížení procesoru způsobené SELECT dotazy, a jak jsme probrali, čtení lze jednoduše škálovat pouhým přidáním více uzlů do clusteru. Více uzlů ke čtení znamená snížení zatížení každého z nich. Když jste na začátku své cesty do životního cyklu vaší aplikace, předpokládejte, že právě to budete řešit. Zatížení CPU, neefektivní dotazy. Je velmi nepravděpodobné, že byste potřebovali škálovat zápisy až do dalšího životního cyklu, kdy vaše aplikace již dozrála a vy se musíte vypořádat s počtem zákazníků.
Pomocí sdílení
Přidání uzlů problém zápisu nevyřeší, to jsme zjistili. Místo toho musíte udělat sharding - rozdělení datové sady napříč clusterem. V tomto případě každý uzel obsahuje pouze část dat, ne vše. To nám umožňuje konečně začít škálovat zápisy. Řekněme, že máme čtyři uzly, z nichž každý obsahuje polovinu datové sady.
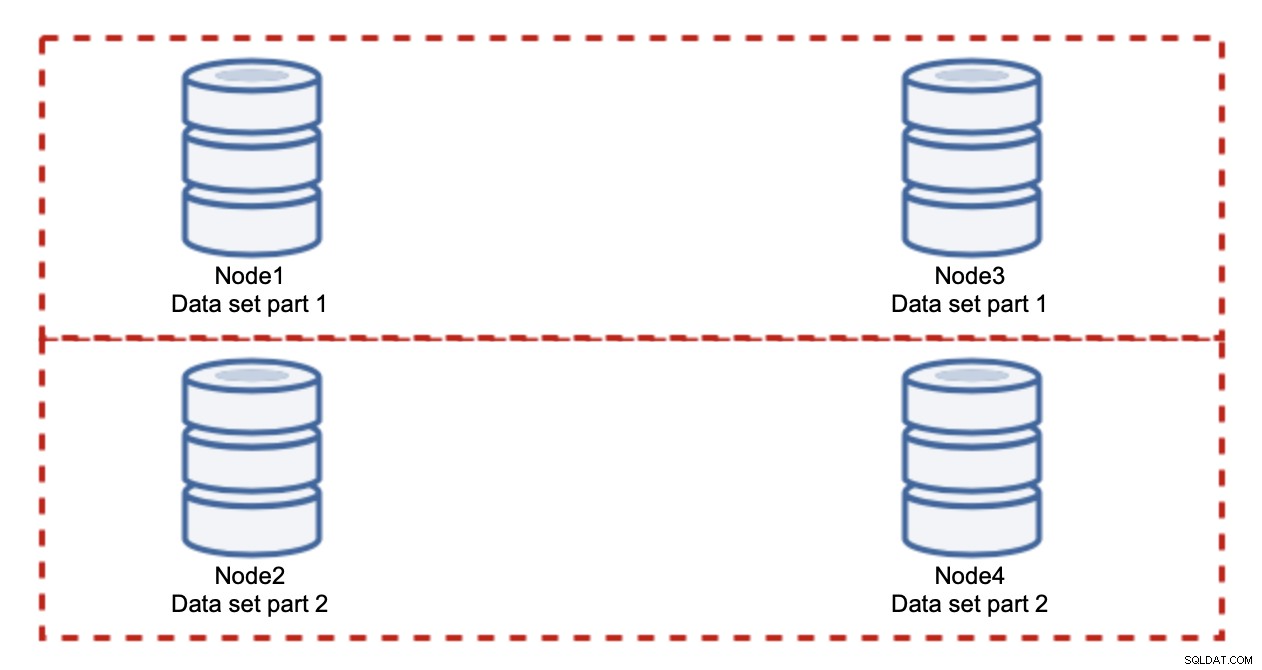
Jak vidíte, myšlenka je jednoduchá. Pokud se zápis týká části 1 datové sady, bude proveden na node1 a node3. Pokud se vztahuje k části 2 datové sady, bude provedena na node2 a node4. Databázové uzly si můžete představit jako disky v RAID. Zde máme příklad RAID10, dvou párů zrcadel, pro redundanci. V reálné implementaci to může být složitější, můžete mít více než jednu repliku dat pro lepší vysokou dostupnost. Podstatou je, že za předpokladu dokonale spravedlivého rozdělení dat polovina zápisů zasáhne uzel1 a uzel3 a druhá polovina uzly 2 a 4. Pokud chcete zatížení ještě více rozdělit, můžete zavést třetí pár uzlů:
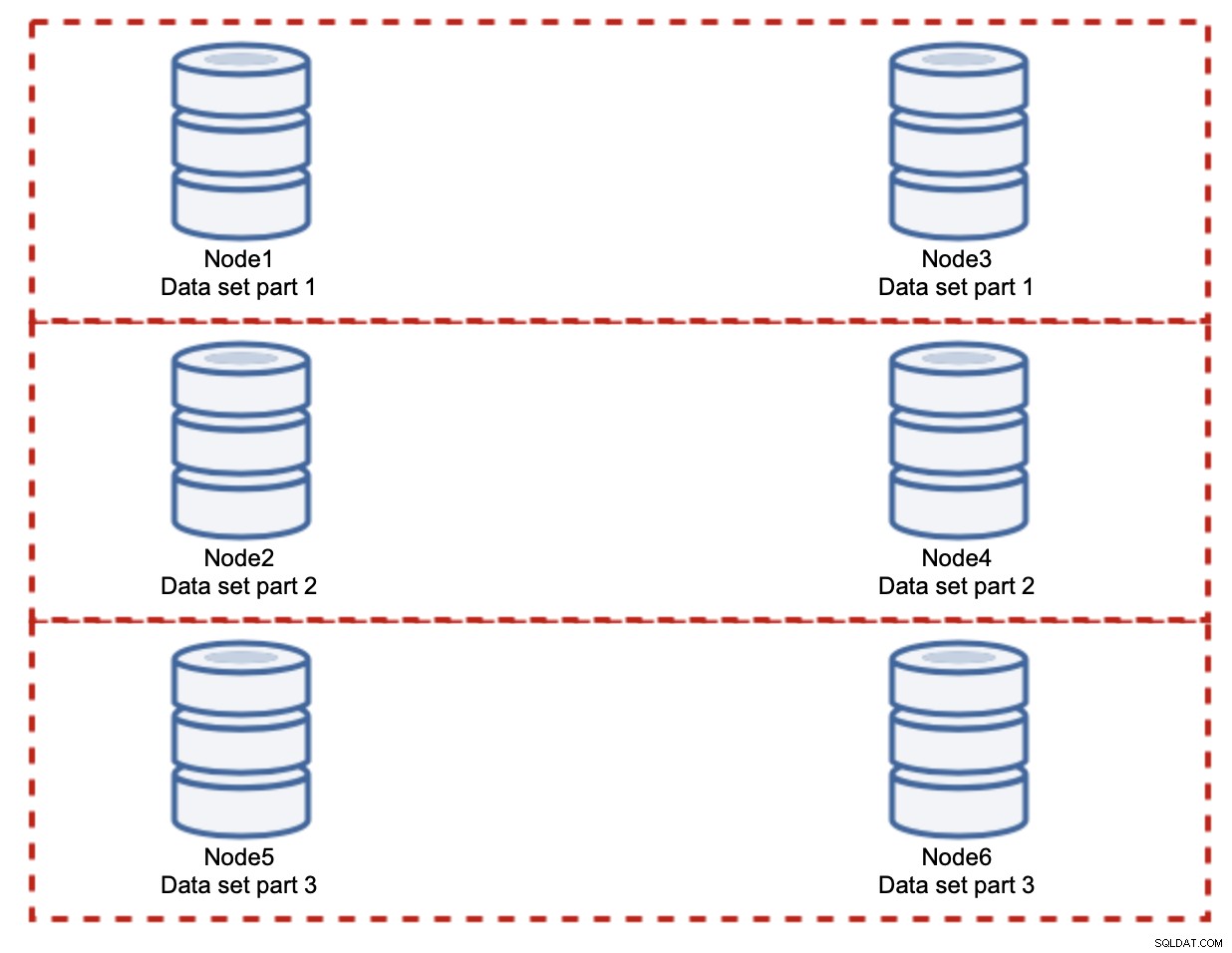
V tomto případě opět, za předpokladu naprosto spravedlivého rozdělení, bude každý pár být zodpovědný za 33 % všech zápisů do clusteru.
Toto v podstatě shrnuje myšlenku shardování. V našem příkladu přidáním dalších úlomků můžeme snížit aktivitu zápisu na uzlech databáze na 33 % původního I/O zatížení. Jak si dokážete představit, neobejde se to bez nevýhod.
Jak zjistím, na kterém fragmentu se moje data nacházejí? Podrobnosti jsou mimo rozsah tohoto volání, ale stručně řečeno, můžete buď implementovat nějakou funkci v daném sloupci (modulo nebo hash ve sloupci 'id'), nebo můžete vytvořit samostatnou metadatabázi, kde budete ukládat podrobnosti jak jsou data distribuována.
Doufáme, že pro vás byla tato krátká série blogů poučná a že jste lépe porozuměli různým výzvám, kterým čelíme, když chceme škálovat databázové prostředí. Pokud máte nějaké připomínky nebo návrhy k tomuto tématu, neváhejte je komentovat pod tímto příspěvkem a podělit se o své zkušenosti