Po nedávném upgradu na 12.1.0.2 jsem pracoval na řadě problémů s výkonem. Mnoho takových problémů souvisí se špatným SQL a u řady problémů, které jsem vyřešil, jsem dokázal, že byly problémy ve staré verzi 11.2.0.4. To jen znamená, že to byl vždy problém. Ale lidé využívají příležitosti upgradu, aby mě přiměli opravit věci, které byly po dlouhou dobu nefunkční.
Při pohledu na problémy s výkonem jsem narazil na dva příkazy SQL, které se v našem systému stávají prasaty. Zde je snímek obrazovky dvou příkazů SQL, jak jsou vidět v Lighty:
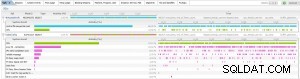
Vidíme, že první příkaz SQL (ID SQL 4b4wp0a8dvkf0) spotřebovává CPU a čeká na čtení z řídicího souboru. Druhý příkaz SQL (ID SQL frjd8zfy2jfdq) využívá hodně CPU a má také řadu dalších událostí čekání. Zde je text SQL těchto příkazů.
SQL ID:frjd8zfy2jfdq
SELECT
executions
,end_of_fetch_count
,elapsed_time / px_servers elapsed_time
,cpu_time / px_servers cpu_time
,buffer_gets / executions buffer_gets
FROM
(
SELECT
SUM (executions) AS executions
,SUM (
CASE
WHEN px_servers_executions > 0
THEN px_servers_executions
ELSE executions
END
) AS px_servers
,SUM (end_of_fetch_count) AS end_of_fetch_count
,SUM (elapsed_time) AS elapsed_time
,SUM (cpu_time) AS cpu_time
,SUM (buffer_gets) AS buffer_gets
FROM
gv$sql
WHERE
executions > 0
AND sql_id = : 1
AND parsing_schema_name = : 2
SQL ID:4b4wp0a8dvkf0
SELECT
executions
,end_of_fetch_count
,elapsed_time / px_servers elapsed_time
,cpu_time / px_servers cpu_time
,buffer_gets / executions buffer_gets
FROM
(
SELECT
SUM (executions_delta) AS EXECUTIONS
,SUM (
CASE
WHEN px_servers_execs_delta > 0
THEN px_servers_execs_delta
ELSE executions_delta
END
) AS px_servers
,SUM (end_of_fetch_count_delta) AS end_of_fetch_count
,SUM (elapsed_time_delta) AS ELAPSED_TIME
,SUM (cpu_time_delta) AS CPU_TIME
,SUM (buffer_gets_delta) AS BUFFER_GETS
FROM
DBA_HIST_SQLSTAT s
,V$DATABASE d
,DBA_HIST_SNAPSHOT sn
WHERE
s.dbid = d.dbid
AND bitand (
nvl (
s.flag
,0
)
,1
) = 0
AND sn.end_interval_time > (
SELECT
systimestamp AT TIME ZONE dbtimezone
FROM
dual
) - 7
AND s.sql_id = : 1
AND s.snap_id = sn.snap_id
AND s.instance_number = sn.instance_number
AND s.dbid = sn.dbid
AND parsing_schema_name = : 2
)
)
Oba jsou součástí nových funkcí Adaptive Query Optimization nyní ve verzi 12c. Konkrétněji se týkají části Automatická dynamická statistika této funkce. SQL ID frjd8zfy2jfdq je Oracle, který získává informace o výkonu příkazů SQL z GV$SQL. SQL ID 4b4wp0a8dvkf0 je Oracle, který získává stejné informace o výkonu SQL příkazů z tabulek Active Session History.
Bertand Drouvot o tom diskutuje na svém blogu zde:https://bdrouvot.wordpress.com/2014/10/17/watch-out-for-optimizer_adaptive_features-as-it-may-have-a-huge-negative-impact/
Kromě toho jsem se zúčastnil sezení Christiana Antogniniho na Oak Table World 2015, kde zmínil tyto příkazy SQL. Jeho snímky z OTW jsou v podstatě stejné jako tyto:
https://www.soug.ch/fileadmin/user_upload/SIGs/SIG_150521_Tuning_R/Christian_Antognini_AdaptiveDynamicSampling_trivadis.pdf
Tyto odkazy výše a poznámky MOS, na které odkazuji níže, poskytly většinu základů informací, které zde uvádím.
Všechny funkce Adaptive Query Optimization mají zlepšit život DBA. Mají pomoci optimalizátoru činit lepší rozhodnutí i poté, co se příkaz SQL začne provádět. V tomto konkrétním případě mají tyto dotazy pomoci CBO získat lepší statistiky, i když statistiky chybí. To může pomoci zlepšit výkon SQL, ale jak jsem zjistil v mém případě, brzdí to celkový výkon systému.
Další informace o adaptivní optimalizaci dotazů najdete v poznámce 2031605.1. To vás zavede k dalším poznámkám, ale zejména k této diskusi, Poznámka 2002108.1 Automatic Dynamic Statistics.
Ještě horší je, že můj produkční systém, který vidí toto chování, je Oracle RAC. Když se na systémech Oracle RAC provádí SQL ID frjd8zfy2jfdq, používá se paralelní dotaz, což je zřejmé z mého snímku obrazovky enq:PS – spory a události čekání „PX%“.
Dynamické vzorkování můžeme změnit následovně:
alter system set optimizer_dynamic_sampling=0 scope=both;
Výchozí hodnota tohoto parametru je 2.
Pro mě tyto dotazy spotřebovávají zdroje a ovlivňují celkový výkon databáze. Tyto funkce jsou však navrženy tak, aby se zlepšovaly výkon. Vždy existuje riziko, že pokud funkci vypnu, abych pomohl výkonu v jedné oblasti, zhorší to výkon v jiné oblasti. Ale protože pro mě optimizer_dynamic_sampling<>11, nevyužívám tuto funkci naplno, takže nezískávám všechny výhody, které bych mohl mít. Náš kód také nespoléhá na dynamické vzorkování. Takže to můžu bezpečně vypnout.
Po změně parametru jsem viděl okamžitou změnu, jak je uvedeno níže.

Červená čára označuje čas, kdy jsem provedl změnu. Je jasné, že ASH verze tohoto dotazu se již nespouští. Verze V$SQL se stále provádí, ale již nevidí události čekání na paralelní dotaz. Teď to většinou jen spotřebovává CPU. Považuji to za pokrok, ale ne za plné rozlišení.
Jako vedlejší poznámku jsem mohl vypnout všechny funkce Adaptivní optimalizace dotazů pomocí následujícího:
alter system set optimizer_adaptive_features=false scope=both;
Ale vím, že mám dotazy, které si „užívají“ Adaptive Join Optimization, a nechci to všechno vypínat, jen dynamické vzorkování.
Co tedy dělat s SQL ID frjd8zfy2jfdq? Uvidíme, zda dokážeme vyřešit zbývající problém. Z jedné z poznámek MOS, které jsem propojil výše, vím, že můžeme nastavit tento skrytý parametr:
alter system set "_optimizer_dsdir_usage_control"=0 scope=both;
Výchozí hodnota tohoto skrytého parametru byla v mém systému 12.1.0.2 126. Našel jsem výchozí nastavení s následujícím:
select a.ksppinm name, b.ksppstvl value, b.ksppstdf deflt,
from
sys.x$ksppi a,
sys.x$ksppcv b
where a.indx = b.indx
and a.ksppinm like '\_%' escape '\'
and a.ksppinm like '%dsdir%'
order by name;
Tato hodnota je důležitá v případě, že ji chci nastavit zpět, aniž bych musel vyjímat parametr ze SPFILE, což by vyžadovalo odstávku.
Nyní mohu pokračovat ve změně tohoto skrytého parametru a jeho nastavení na nulu. Takto vypadá tento příkaz SQL v Lighty po změně:

Zdá se, že „mise splněna“ v zastavení provádění těchto dvou příkazů SQL.
Uživatelé, kteří používají 12.1.0.2 na Oracle RAC, mohou chtít ověřit, že tyto dva příkazy SQL samy o sobě nezpůsobují problémy s výkonem.
Zdá se, že jde o jeden z případů, kdy funkce, která má pomáhat výkonu, ve skutečnosti dělá opak.