Toto je docela běžný problém.
Obyčejný B-Tree indexy nejsou dobré pro dotazy, jako je tento:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Index je dobrý pro vyhledávání hodnot v daných mezích, jako je tento:
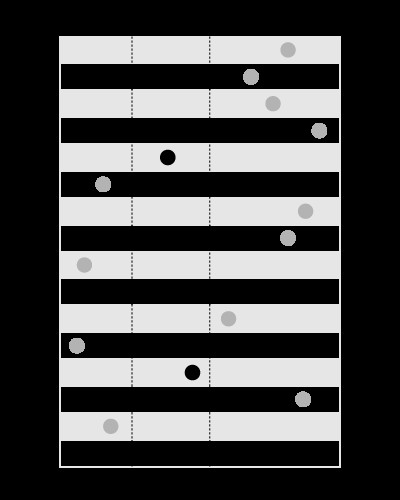
, ale ne pro hledání hranic obsahujících danou hodnotu, jako je toto:
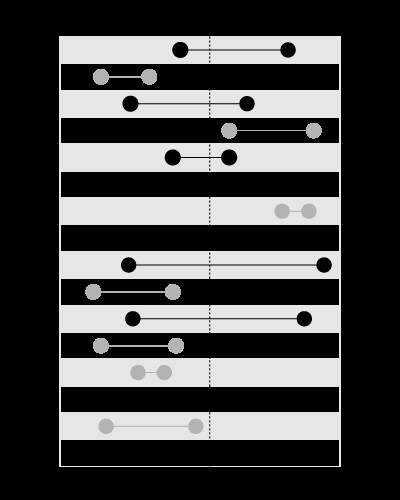
Tento článek na mém blogu vysvětluje problém podrobněji:
(model vnořených množin se zabývá podobným typem predikátu).
Index můžete vytvořit v time , tímto způsobem intervals bude ve spojení vést, bude rozsah času použit uvnitř vnořených smyček. To bude vyžadovat řazení podle time .
Prostorový index můžete vytvořit na intervals (dostupné v MySQL pomocí MyISAM úložiště), které by zahrnovalo start a end v jednom geometrickém sloupci. Tímto způsobem measures může vést ve spojení a nebude potřeba žádné řazení.
Prostorové indexy jsou však pomalejší, takže to bude efektivní pouze v případě, že máte málo měření, ale mnoho intervalů.
Protože máte málo intervalů, ale mnoho měření, ujistěte se, že máte index na measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Aktualizace:
Zde je ukázkový skript k otestování:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Tento dotaz:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
používá NESTED LOOPS a vrátí se v 1.7 sekund.
Tento dotaz:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
používá MERGE JOIN a musel jsem to zastavit po 5 minut.
Aktualizace 2:
S největší pravděpodobností budete muset přinutit motor, aby ve spojení použil správné pořadí tabulek, pomocí této nápovědy:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle Optimalizátor 's není dostatečně chytrý, aby viděl, že se intervaly neprotínají. Proto bude s největší pravděpodobností používat measures jako úvodní tabulku (což by bylo moudré rozhodnutí, pokud by se intervaly protínaly).
Aktualizace 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Tento dotaz rozdělí časovou osu na rozsahy a používá HASH JOIN pro spojení měření a časových razítek na hodnotách rozsahu s pozdějším jemným filtrováním.
Podrobnější vysvětlení, jak to funguje, najdete v tomto článku na mém blogu: