V tomto článku vytvoříme škrabku pro skutečné koncert na volné noze, kde klient chce, aby program Python seškrábal data ze Stack Overflow, aby získal nové otázky (název otázky a URL). Scrapped data by pak měla být uložena v MongoDB. Stojí za zmínku, že Stack Overflow má API, které lze použít k přístupu k přesnému stejná data. Klient však chtěl škrabku, takže dostal škrabku.
Box zdarma: Klikněte sem a stáhněte si kostru projektu Python + MongoDB s úplným zdrojovým kódem, který vám ukáže, jak přistupovat k MongoDB z Pythonu.
Aktualizace:
- 01/03/2014 - Refaktorováno pavouka. Díky, @kissgyorgy.
- 18. 2. 2015 – přidána část 2.
- 09/06/2015 – Aktualizováno na nejnovější verzi Scrapy a PyMongo – na zdraví!
Jako vždy si nezapomeňte přečíst podmínky používání/služby webu a respektovat robots.txt soubor před zahájením jakékoli škrabací práce. Ujistěte se, že dodržujete etické postupy stírání tím, že nezahlcujete web mnoha požadavky během krátké doby. Zacházejte s každým webem, který oškrábete, jako by byl váš vlastní .
Instalace
Potřebujeme knihovnu Scrapy (v1.0.3) spolu s PyMongo (v3.0.3) pro ukládání dat v MongoDB. Musíte nainstalovat také MongoDB (není zahrnuto).
Scrapy
Pokud používáte OSX nebo verzi Linuxu, nainstalujte Scrapy s pip (s aktivovaným virtualenv):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Pokud používáte počítač se systémem Windows, budete muset ručně nainstalovat řadu závislostí. Podrobné pokyny naleznete v oficiální dokumentaci a v tomto videu na YouTube, které jsem vytvořil.
Jakmile je Scrapy nastaven, ověřte svou instalaci spuštěním tohoto příkazu v prostředí Pythonu:
>>>>>> import scrapy
>>>
Pokud se vám nezobrazí chyba, můžete začít!
PyMongo
Dále nainstalujte PyMongo pomocí pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Nyní můžeme začít stavět prohledávač.
Projekt Scrapy
Začněme nový projekt Scrapy:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Tím se vytvoří řada souborů a složek, které obsahují základní vzor, abyste mohli rychle začít:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Zadejte data
Soubor items.py soubor se používá k definování „kontejnerů“ úložiště pro data, která plánujeme seškrábat.
StackItem() třída dědí z Item (docs), který má v podstatě řadu předdefinovaných objektů, které pro nás Scrapy již postavil:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Pojďme přidat nějaké položky, které skutečně chceme sbírat. Pro každou otázku klient potřebuje název a URL. Aktualizujte tedy items.py takhle:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Vytvořte Pavouka
Vytvořte soubor s názvem stack_spider.py v adresáři „pavouci“. Tady se děje kouzlo – např. kde Scrapymu řekneme, jak najít přesné údaje, které hledáme. Jak si dokážete představit, toto je specifické na každou jednotlivou webovou stránku, kterou chcete seškrábat.
Začněte definováním třídy, která dědí ze Scrapyho Spider a poté podle potřeby přidejte atributy:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Prvních několik proměnných je samovysvětlujících (docs):
namedefinuje jméno pavouka.allowed_domainsobsahuje základní adresy URL povolených domén, které může pavouk procházet.start_urlsje seznam adres URL, ze kterých má pavouk začít procházet. Všechny následující adresy URL budou začínat daty, která si pavouk stáhne z adres URL vstart_urls.
Selektory XPath
Dále Scrapy používá selektory XPath k extrahování dat z webu. Jinými slovy, můžeme vybrat určité části HTML dat na základě dané XPath. Jak je uvedeno v dokumentaci Scrapy, „XPath je jazyk pro výběr uzlů v dokumentech XML, který lze také použít s HTML.“
Konkrétní Xpath můžete snadno najít pomocí vývojářských nástrojů Chrome. Jednoduše zkontrolujte konkrétní prvek HTML, zkopírujte cestu XPath a poté dolaďte (podle potřeby):
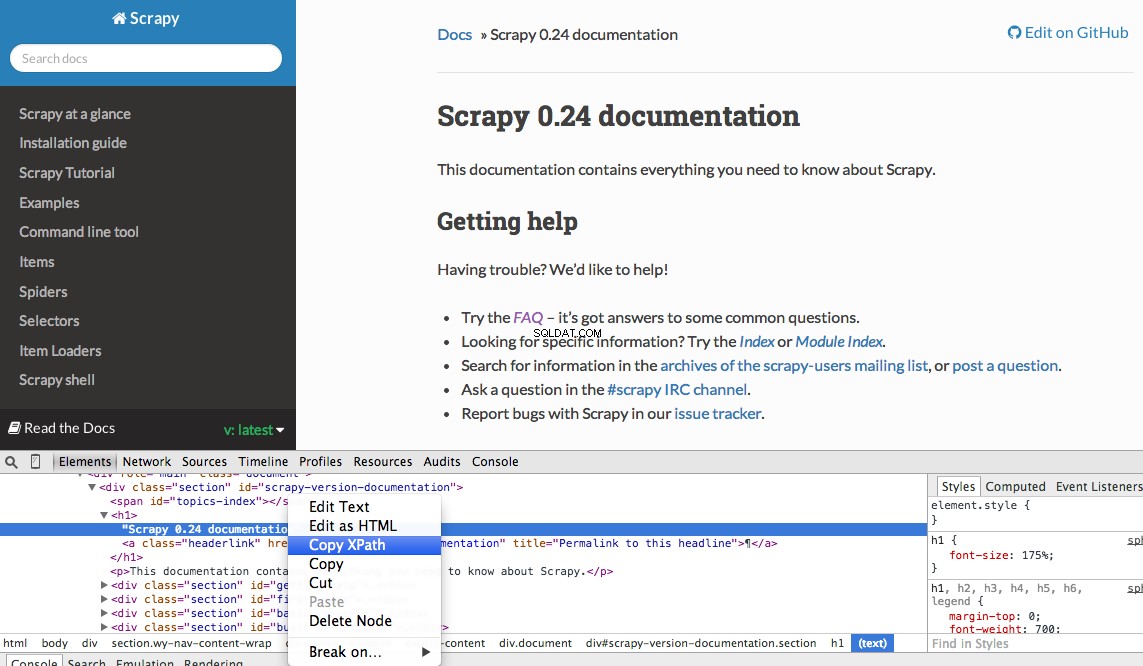
Nástroje pro vývojáře také umožňují testovat selektory XPath v konzole JavaScript pomocí $x – tj. $x("//img") :
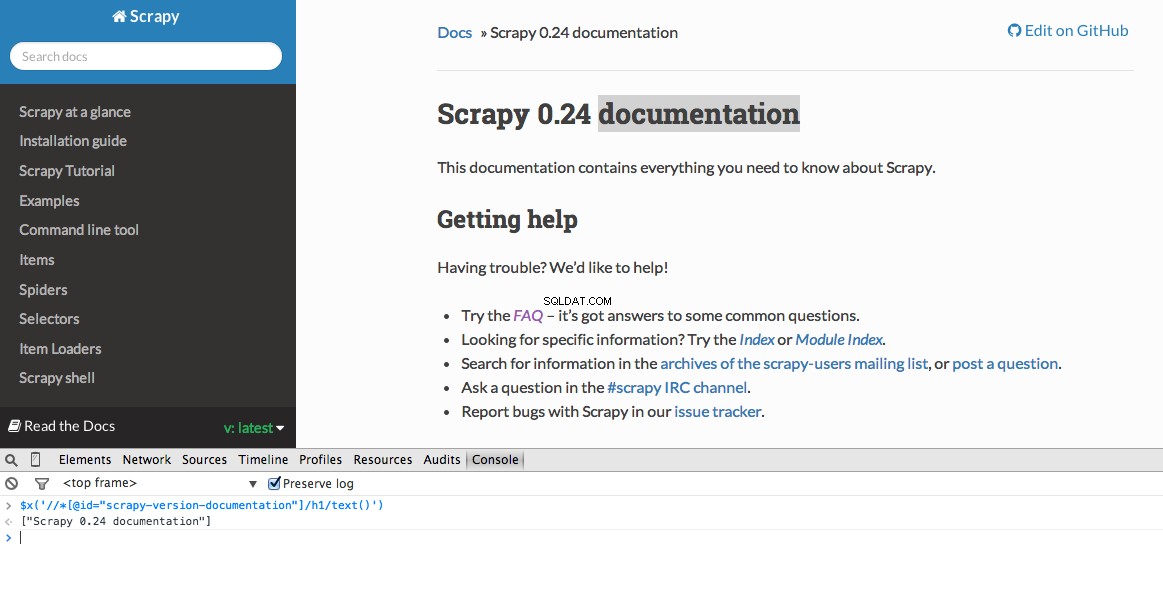
Opět v podstatě říkáme Scrapymu, kde má začít hledat informace na základě definované XPath. Přejdeme na stránku Stack Overflow v prohlížeči Chrome a najdeme selektory XPath.
Klikněte pravým tlačítkem na první otázku a vyberte „Inspect Element“:
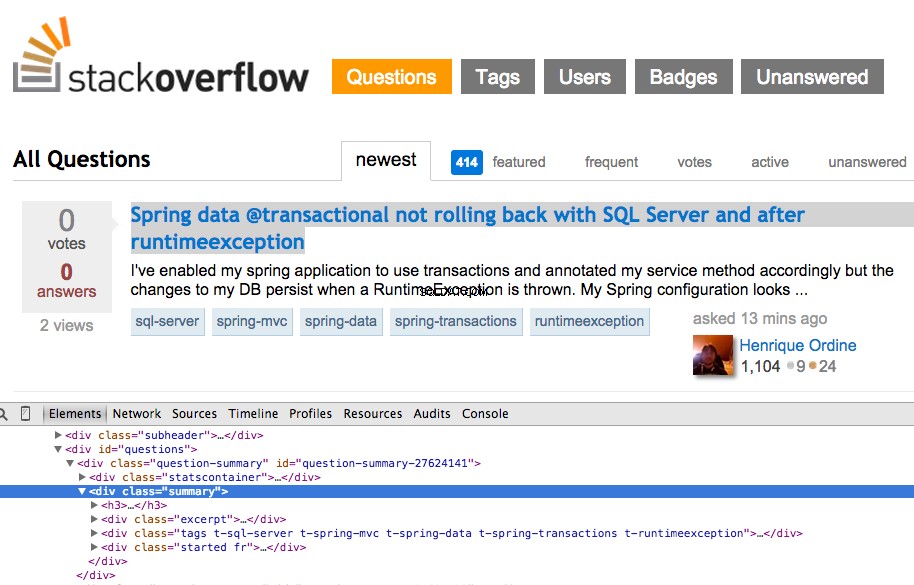
Nyní uchopte cestu XPath pro <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] a poté jej otestujte v konzole JavaScript:
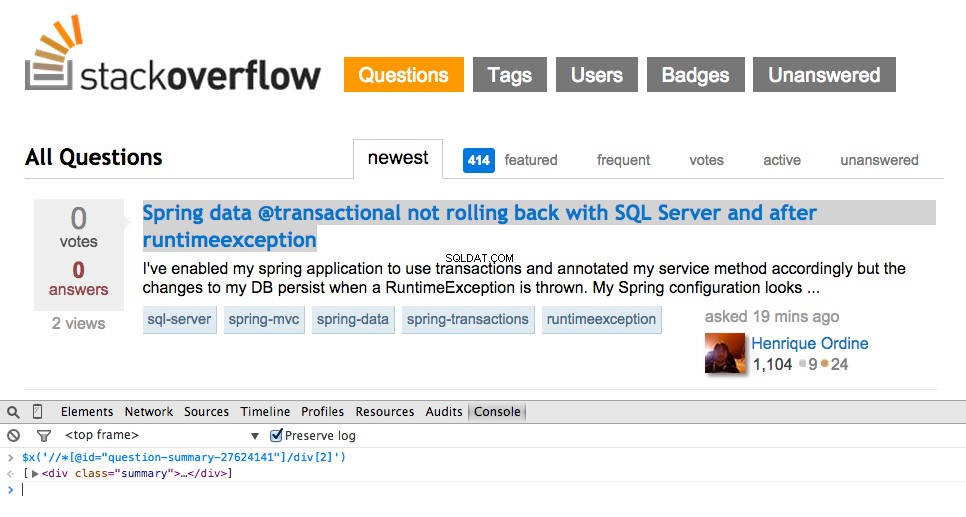
Jak můžete říci, vybere pouze to jeden otázka. Musíme tedy změnit cestu XPath tak, aby zachytila vše otázky. Nějaké nápady? Je to jednoduché://div[@class="summary"]/h3 . Co to znamená? Tato cesta XPath v podstatě uvádí:Uchopte vše <h3> prvky, které jsou potomky <div> který má třídu summary . Otestujte tuto cestu XPath v konzole JavaScript.
Všimněte si, že nepoužíváme skutečný výstup XPath z Chrome Developer Tools. Ve většině případů je výstup jen užitečnou stranou, která vás obecně nasměruje správným směrem k nalezení funkční XPath.
Nyní aktualizujme soubor stack_spider.py skript:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Extrahujte data
Stále potřebujeme analyzovat a seškrábat požadovaná data, která spadají do <div class="summary"><h3> . Znovu aktualizujte stack_spider.py takhle:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Spolu s trasováním zásobníku Scrapy by se mělo zobrazit 50 názvů otázek a adres URL. Výstup můžete vykreslit do souboru JSON pomocí tohoto malého příkazu:
$ scrapy crawl stack -o items.json -t json
Nyní jsme implementovali náš Spider na základě našich dat, která hledáme. Nyní musíme uložit seškrabovaná data do MongoDB.
Uložte data do MongoDB
Pokaždé, když se položka vrátí, chceme data ověřit a poté je přidat do kolekce Mongo.
Prvním krokem je vytvoření databáze, kterou plánujeme použít k uložení všech našich prolezených dat. Otevřete settings.py a zadejte kanál a přidejte nastavení databáze:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Správa potrubí
Nastavili jsme našeho pavouka, aby procházel a analyzoval HTML, a nastavili jsme nastavení naší databáze. Nyní je musíme propojit pomocí potrubí v pipelines.py .
Připojit k databázi
Nejprve definujme metodu skutečného připojení k databázi:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Zde vytvoříme třídu MongoDBPipeline() a máme funkci konstruktoru pro inicializaci třídy definováním nastavení Mongo a následným připojením k databázi.
Zpracování dat
Dále musíme definovat metodu zpracování analyzovaných dat:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Navážeme spojení s databází, rozbalíme data a poté je uložíme do databáze. Nyní můžeme testovat znovu!
Test
Znovu spusťte následující příkaz v adresáři „stack“:
$ scrapy crawl stack
POZNÁMKA :Ujistěte se, že máte démona Mongo -
mongod- běžící v jiném okně terminálu.
Hurá! Naše procházená data jsme úspěšně uložili do databáze:
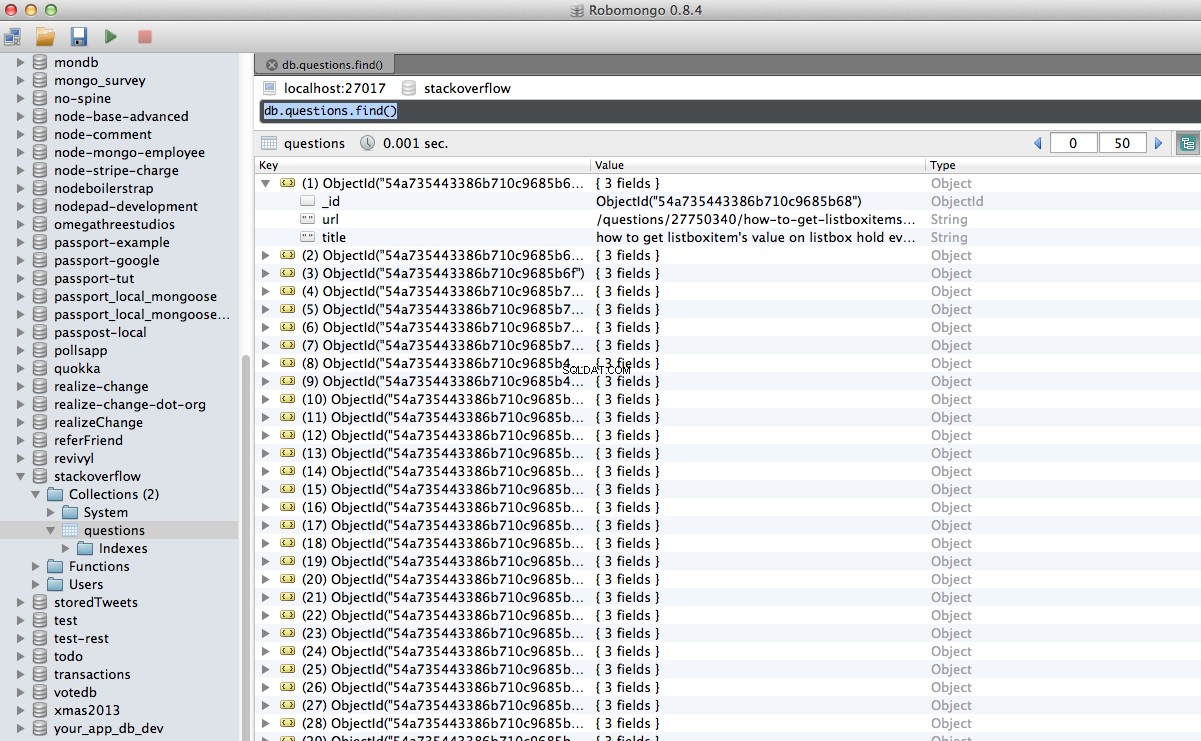
Závěr
Toto je docela jednoduchý příklad použití Scrapy k procházení a škrábání webové stránky. Skutečný projekt na volné noze vyžadoval, aby skript sledoval odkazy na stránkování a seškrábal každou stránku pomocí CrawlSpider (docs), který se velmi snadno implementuje. Zkuste to implementovat sami a zanechte níže komentář s odkazem na úložiště Github pro rychlou kontrolu kódu.
Potřebovat pomoc? Začněte s tímto skriptem, který je téměř hotový. Pak si prohlédněte část 2, kde najdete úplné řešení!
Box zdarma: Klikněte sem a stáhněte si kostru projektu Python + MongoDB s úplným zdrojovým kódem, který vám ukáže, jak přistupovat k MongoDB z Pythonu.
Celý zdrojový kód si můžete stáhnout z úložiště Github. Komentář níže s dotazy. Děkujeme za přečtení!