Efektivita databáze nespočívá pouze na doladění nejkritičtějších parametrů, ale jde také dále na vhodnou prezentaci dat v souvisejících kolekcích. Nedávno jsem pracoval na projektu, který vyvíjel aplikaci pro sociální chat, a po pár dnech testování jsme zaznamenali určité zpoždění při načítání dat z databáze. Neměli jsme tolik uživatelů, takže jsme vyloučili ladění parametrů databáze a zaměřili se na naše dotazy, abychom se dostali ke kořenové příčině.
K našemu překvapení jsme si uvědomili, že naše struktura dat není úplně vhodná, protože jsme měli více než 1 žádost o čtení, abychom získali nějaké konkrétní informace.
Koncepční model toho, jak jsou sekce aplikace zaváděny, do značné míry závisí na struktuře databázových kolekcí. Pokud se například přihlásíte do sociální aplikace, data se vloží do různých sekcí podle návrhu aplikace, jak je znázorněno na prezentaci databáze.
Stručně řečeno, pro dobře navrženou databázi jsou struktura schématu a vztahy mezi kolekcemi klíčové věci pro její vyšší rychlost a integritu, jak uvidíme v následujících částech.
Probereme faktory, které byste měli vzít v úvahu při modelování vašich dat.
Co je datové modelování
Datové modelování je obecně analýza datových položek v databázi a toho, jak souvisí s jinými objekty v této databázi.
V MongoDB například můžeme mít kolekci uživatelů a kolekci profilů. Kolekce uživatelů uvádí jména uživatelů pro danou aplikaci, zatímco kolekce profilů zachycuje nastavení profilu pro každého uživatele.
V datovém modelování musíme navrhnout vztah pro připojení každého uživatele k příslušnému profilu. Stručně řečeno, datové modelování je základním krokem v návrhu databáze vedle vytvoření architektonického základu pro objektově orientované programování. Poskytuje také vodítko o tom, jak bude fyzická aplikace vypadat během vývoje. Architektura integrace aplikace-databáze může být znázorněna níže.
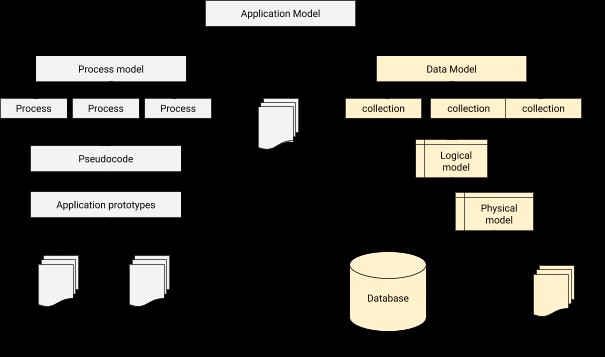
Proces modelování dat v MongoDB
Datové modelování přichází se zlepšeným výkonem databáze, ale na úkor některých úvah, mezi které patří:
- Vzory získávání dat
- Vyvážení potřeb aplikace, jako jsou:dotazy, aktualizace a zpracování dat
- Funkce výkonu zvoleného databázového stroje
- Vlastní struktura samotných dat
Struktura dokumentu MongoDB
Dokumenty v MongoDB hrají hlavní roli při rozhodování o tom, jakou techniku použít pro danou sadu dat. Obecně existují dva vztahy mezi daty, které jsou:
- Vložená data
- Referenční údaje
Vložená data
V tomto případě jsou související data uložena v rámci jednoho dokumentu buď jako hodnota pole, nebo pole v dokumentu samotném. Hlavní výhodou tohoto přístupu je, že data jsou denormalizována, a proto poskytuje příležitost pro manipulaci se souvisejícími daty v jediné databázové operaci. Následně to zlepšuje rychlost, jakou jsou prováděny operace CRUD, a proto je potřeba méně dotazů. Podívejme se na příklad dokumentu níže:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}V tomto souboru dat máme studenta s jeho jménem a některými dalšími doplňujícími informacemi. Pole Nastavení bylo vloženo s objektem a dále pole PlaceLocation je také vloženo s objektem s konfigurací zeměpisné šířky a délky. Všechna data o tomto studentovi byla obsažena v jediném dokumentu. Pokud potřebujeme získat všechny informace o tomto studentovi, spustíme:
db.students.findOne({StudentName : "George Beckonn"})Síla vkládání
- Větší rychlost přístupu k datům:Pro lepší rychlost přístupu k datům je vkládání tou nejlepší volbou, protože jediná operace dotazu může manipulovat s daty v zadaném dokumentu pomocí jediného vyhledávání v databázi.
- Snížená nekonzistence dat:Pokud se během provozu něco pokazí (například odpojení sítě nebo výpadek napájení), může být ovlivněno pouze několik dokumentů, protože kritéria často vybírají jeden dokument.
- Snížení počtu operací CRUD. To znamená, že počet operací čtení ve skutečnosti převýší počet zápisů. Kromě toho je možné aktualizovat související data v jediné operaci atomového zápisu. To znamená, že pro výše uvedená data můžeme aktualizovat telefonní číslo a také zvýšit vzdálenost pomocí této jediné operace:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Slabé stránky vkládání
- Omezená velikost dokumentu. Všechny dokumenty v MongoDB jsou omezeny na velikost BSON 16 megabajtů. Celková velikost dokumentu spolu s vloženými daty by proto neměla překročit tento limit. V opačném případě u některých úložišť, jako je MMAPv1, mohou data přerůstat a vést k fragmentaci dat v důsledku sníženého výkonu zápisu.
- Duplikace dat:více kopií stejných dat ztěžuje dotazování na replikovaná data a filtrování vložených dokumentů může trvat déle, a proto překonává hlavní výhodu vkládání.
Tečkový zápis
Tečkový zápis je identifikačním znakem pro vložená data v programovací části. Používá se pro přístup k prvkům vloženého pole nebo pole. Ve výše uvedených vzorových datech můžeme pomocí tohoto dotazu vrátit informace o studentovi, jehož poloha je „Ambasáda“, pomocí tečkové notace.
db.users.find({'Settings.location': 'Embassy'})Referenční data
Vztah dat v tomto případě je, že související data jsou uložena v různých dokumentech, ale na tyto související dokumenty je vydán určitý odkaz. Pro ukázková data výše je můžeme rekonstruovat takovým způsobem, že:
Uživatelský dokument
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Dokument nastavení
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Existují 2 různé dokumenty, ale jsou propojeny stejnou hodnotou pro pole _id a id. Datový model je tak normalizován. Abychom však měli přístup k informacím ze souvisejícího dokumentu, musíme zadat další dotazy, což má za následek delší dobu provádění. Pokud například chceme aktualizovat ParentPhone a související nastavení vzdálenosti, budeme mít alespoň 3 dotazy, tj.
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Síla odkazování
- Konzistence dat. Pro každý dokument je zachována kanonická forma, takže šance na nekonzistenci dat jsou velmi nízké.
- Vylepšená integrita dat. Díky normalizaci je snadné aktualizovat data bez ohledu na délku trvání operace a zajistit tak správná data pro každý dokument, aniž by to způsobilo jakékoli nejasnosti.
- Vylepšené využití mezipaměti. Kanonické dokumenty, ke kterým se často přistupuje, se ukládají do mezipaměti spíše než vložené dokumenty, ke kterým se přistupuje několikrát.
- Efektivní využití hardwaru. Na rozdíl od vkládání, které může mít za následek přerůstání dokumentu, odkazování nepodporuje růst dokumentu, takže snižuje využití disku a paměti RAM.
- Vylepšená flexibilita, zejména u velké sady vnořených dokumentů.
- Rychlejší zápis.
Slabé stránky odkazování
- Vícenásobné vyhledávání:Vzhledem k tomu, že musíme hledat v řadě dokumentů, které odpovídají kritériím, prodlužuje se doba čtení při načítání z disku. Kromě toho to může vést k vynechání mezipaměti.
- Za účelem dosažení určité operace je zadáváno mnoho dotazů, a proto normalizované datové modely vyžadují více zpátečních cest na server k dokončení konkrétní operace.
Normalizace dat
Normalizace dat se týká restrukturalizace databáze v souladu s některými normálními formami, aby se zlepšila integrita dat a snížily se případy redundance dat.
Datové modelování se točí kolem 2 hlavních normalizačních technik, kterými jsou:
-
Normalizované datové modely
Jak se používá v referenčních datech, normalizace rozděluje data do více kolekcí s odkazy mezi nové kolekce. Aktualizace jednoho dokumentu bude vydána pro druhou kolekci a bude aplikována odpovídajícím způsobem na odpovídající dokument. To poskytuje efektivní reprezentaci aktualizace dat a běžně se používá pro data, která se poměrně často mění.
-
Denormalizované datové modely
Data obsahují vložené dokumenty, díky čemuž jsou operace čtení poměrně efektivní. Je to však spojeno s větším využitím místa na disku a také potížemi s udržováním synchronizace. Koncept denormalizace lze dobře aplikovat na vnořené dokumenty, jejichž data se poměrně často nemění.
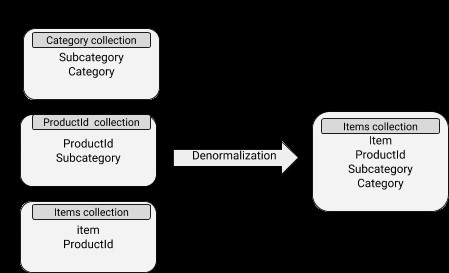
Schéma MongoDB
Schéma je v podstatě nastíněná kostra polí a datového typu, které by každé pole mělo obsahovat pro danou sadu dat. Z hlediska SQL jsou všechny řádky navrženy tak, aby měly stejné sloupce a každý sloupec by měl obsahovat definovaný datový typ. V MongoDB však máme ve výchozím nastavení flexibilní schéma, které nezachovává stejnou shodu pro všechny dokumenty.
Flexibilní schéma
Flexibilní schéma v MongoDB definuje, že dokumenty nemusí nutně mít stejná pole nebo datový typ, protože pole se může u různých dokumentů v rámci kolekce lišit. Hlavní výhodou tohoto konceptu je, že lze přidávat nová pole, odstraňovat stávající nebo měnit hodnoty polí na nový typ, a tak aktualizovat dokument do nové struktury.
Například můžeme mít tyto 2 dokumenty ve stejné kolekci:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}V prvním dokumentu máme věkové pole, zatímco ve druhém dokumentu není žádné věkové pole. Dále je datovým typem pro pole ParentPhone číslo, zatímco ve druhém dokumentu bylo nastaveno na false, což je booleovský typ.
Flexibilita schématu usnadňuje mapování dokumentů na objekt a každý dokument může odpovídat datovým polím reprezentované entity.
Pevné schéma
Jak jsme řekli, tyto dokumenty se mohou jeden od druhého lišit, někdy se můžete rozhodnout vytvořit rigidní schéma. Pevné schéma bude definovat, že všechny dokumenty v kolekci budou sdílet stejnou strukturu, a to vám dá lepší šanci nastavit některá pravidla ověřování dokumentů jako způsob zlepšení integrity dat během operací vkládání a aktualizace.
Datové typy schémat
Při použití některých ovladačů serveru pro MongoDB, jako je mongoose, jsou k dispozici některé typy dat, které vám umožňují provádět ověřování dat. Základní datové typy jsou:
- Řetězec
- Číslo
- Booleovská hodnota
- Datum
- Vyrovnávací paměť
- ObjectId
- Pole
- Smíšené
- Desetinné 128
- Mapa
Podívejte se na ukázkové schéma níže
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Příklad použití
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Ověření schématu
Stejně jako můžete provádět ověřování dat ze strany aplikace, je vždy dobrou praxí provádět ověřování také ze strany serveru. Toho dosáhneme použitím pravidel ověřování schématu.
Tato pravidla se použijí během operací vkládání a aktualizace. Obvykle jsou deklarovány na základě kolekce během procesu vytváření. Pravidla ověřování dokumentů však můžete také přidat do existující kolekce pomocí příkazu collMod s možnostmi validátoru, ale tato pravidla se na existující dokumenty nepoužijí, dokud se na ně nepoužije aktualizace.
Podobně můžete při vytváření nové kolekce pomocí příkazu db.createCollection() zadat volbu validátoru. Podívejte se na tento příklad při vytváření kolekce pro studenty. Od verze 3.6 MongoDB podporuje ověření schématu JSON, takže vše, co potřebujete, je použít operátor $jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})Pokud se v tomto návrhu schématu pokusíme vložit nový dokument jako:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})Funkce zpětného volání vrátí níže uvedenou chybu, protože některá porušená ověřovací pravidla, jako je zadaná hodnota roku, není ve specifikovaných limitech.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Dále můžete do své možnosti ověření přidat výrazy dotazu pomocí operátorů dotazu kromě $where, $text, near a $nearSphere, tj.:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Úrovně ověření schématu
Jak již bylo zmíněno dříve, normálně se operacím zápisu vydává ověření.
Ověření však lze použít i na již existující dokumenty.
Existují 3 úrovně ověření:
- Přísné:Toto je výchozí úroveň ověření MongoDB a platí pravidla ověření pro všechny vložky a aktualizace.
- Střední:Pravidla ověření se použijí během vkládání, aktualizací a na již existující dokumenty, které splňují pouze kritéria ověření.
- Vypnuto:Tato úroveň nastaví pravidla ověřování pro dané schéma na hodnotu null, proto se u dokumentů nebude provádět žádné ověřování.
Příklad:
Níže uvedená data vložíme do klientské kolekce.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Pokud použijeme střední úroveň ověření pomocí:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Pravidla ověření se použijí pouze na dokument s _id 1, protože bude odpovídat všem kritériím.
U druhého dokumentu, protože pravidla ověření nejsou splněna s vydanými kritérii, dokument nebude ověřen.
Akce ověření schématu
Po provedení ověření na dokumentech mohou existovat některé, které mohou porušovat pravidla ověřování. Vždy je potřeba provést akci, když k tomu dojde.
MongoDB poskytuje dvě akce, které lze provést s dokumenty, které nesplňují pravidla ověření:
- Chyba:Toto je výchozí akce MongoDB, která odmítne jakoukoli vložení nebo aktualizaci v případě, že poruší kritéria ověření.
-
Varovat:Tato akce zaznamená porušení do protokolu MongoDB, ale umožní dokončení operace vložení nebo aktualizace. Například:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Pokud se pokusíme vložit dokument takto:
db.students.insert( { name: "Amanda", status: "Updated" } );Gpa chybí bez ohledu na to, že je to povinné pole v návrhu schématu, ale protože akce ověření byla nastavena na varování, dokument se uloží a do protokolu MongoDB se zaznamená chybová zpráva.