Zjistěte více o architektuře zpracování dat v téměř reálném čase pro transformaci a obohacení datových toků pomocí Apache Flume, Apache Kafka a RocksDB v Santander UK.
Cloudera Professional Services spolupracuje se společností Santander UK na vybudování transakčního analytického systému téměř v reálném čase (NRT) na Apache Hadoop. Cílem je zachytit, transformovat, obohatit, počítat a uložit transakci během několika sekund od nákupu kartou. Systém přijímá transakce bankovních karet maloobchodních zákazníků a vypočítává související informace o trendech agregované podle majitele účtu a v rámci řady dimenzí a taxonomií. Tyto informace jsou poté bezpečně doručeny do aplikace „Spendlytics“ společnosti Santander (viz níže), aby zákazníci mohli analyzovat své nejnovější vzorce výdajů.
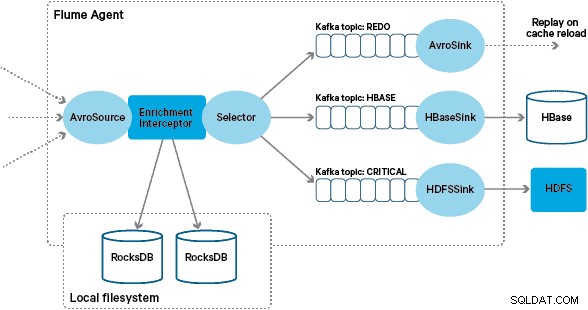
Apache HBase byl vybrán jako základní řešení úložiště kvůli své schopnosti podporovat vysokovýkonné náhodné zápisy a náhodné čtení s nízkou latencí. Požadavek NRT však vylučoval provádění transformací a obohacení transakcí v dávce, takže tyto musí být prováděny během streamování transakcí do HBase. To zahrnuje transformaci zpráv z XML do Avro a jejich obohacení o informace podle trendů, jako jsou informace o značce a obchodníkovi.
Tento příspěvek popisuje, jak Santander používá Apache Flume, Apache Kafka a RocksDB k transformaci, obohacení a streamování transakcí do HBase. Toto je implementace zpracování událostí NRT s externím kontextem vzor streamování popsaný Ted Malaska v tomto příspěvku.
Flafka
První rozhodnutí, které musel Santander učinit, bylo, jak nejlépe streamovat data do HBase. Flume je téměř vždy tou nejlepší volbou pro streamování příjmu do Hadoopu vzhledem k jeho jednoduchosti, spolehlivosti, bohaté řadě zdrojů a jímek a přirozené škálovatelnosti.
Nedávno byla přidána vynikající integrace do Kafky, která vedla k nevyhnutelně pojmenovanému Flafka. Flume může nativně poskytovat zaručené doručení událostí prostřednictvím svého souborového kanálu, ale schopnost přehrát události a přidaná flexibilita a zabezpečení do budoucna, které Kafka přináší, byly klíčovými hnacími silami integrace.
V této architektuře používá Santander kanály Kafka k poskytování spolehlivé, samovyvažující a škálovatelné vyrovnávací paměti příjmu, ve které jsou všechny transformace a zpracování zastoupeny v zřetězených tématech Kafka. Zejména široce využíváme zdroj a jímku Flafka a schopnost společnosti Flume provádět zpracování za letu pomocí interceptorů. Díky tomu jsme nemuseli kódovat našeho vlastního producenta a spotřebitele Kafka a Santanderu to umožnilo plně využít Cloudera Manager ke konfiguraci, nasazení a monitorování agentů a brokerů.
Transformace
Transakce zachycené základními bankovními systémy jsou dodávány do Flume jako zprávy XML, které byly načteny ze zdrojové databáze prostřednictvím replikace protokolu. (Přizpůsobení databázového protokolu do témat Kafka tímto způsobem je stále častějším vzorem a v kombinaci s komprimací protokolů může poskytnout „nejnovější pohled“ na databázi pro případy použití zachycení dat o změnách.)
Flume ukládá tyto XML zprávy do „surového“ Kafkova tématu. Odtud a jako předchůdce veškerého dalšího zpracování bylo rozhodnuto transformovat semistrukturovaný XML do strukturovaných binárních záznamů, aby se usnadnilo standardizované následné zpracování. Toto zpracování je prováděno uživatelským Flume Interceptorem, který transformuje XML zprávy na generickou Avro reprezentaci, přičemž tam, kde je to vhodné, aplikuje specifické typy a tam, kde ne, přechází zpět na řetězcovou reprezentaci. Veškeré následné zpracování NRT pak ukládá odvozené výsledky do Avro ve vyhrazených Kafkových tématech, takže je snadné se napojit na stream a získat zdroj událostí v kterémkoli bodě řetězce zpracování.
Pokud by bylo vyžadováno složitější zpracování událostí – například agregace pomocí Spark Streaming – bylo by triviální záležitostí konzumovat jedno nebo více těchto témat a publikovat do nových odvozených témat. (Apache Avro je pro tento formát přirozenou volbou:jedná se o kompaktní binární protokol podporující vývoj schémat, má flexibilní definici schématu a je podporován v celém zásobníku Hadoop. Avro se rychle stává de facto standardem pro dočasné a obecné ukládání dat v podnikové datové centrum a je dokonale umístěno pro transformaci na Apache Parquet pro analytické úlohy.)
Obohacení
Inspirací pro návrh řešení pro obohacení streamování byl příspěvek O’Reilly Radar, který napsal Jay Kreps. Jay ve svém příspěvku popisuje výhody používání místního úložiště, které umožňuje streamovému procesoru dotazovat se nebo upravovat místní stav v reakci na jeho vstup, na rozdíl od vzdálených volání do distribuované databáze.
Ve společnosti Santander jsme tento vzor upravili tak, aby poskytoval místní referenční úložiště, která se používají k dotazování a obohacení transakcí při jejich streamování přes Flume. Proč nepoužít HBase jako referenční obchod? Typickým vzorem pro tento typ problému je jednoduše uložit stav do HBase a nechat se na něj přímo dotazovat mechanismus obohacení. Rozhodli jsme se pro tento přístup z několika důvodů. Za prvé, referenční data jsou relativně malá a vešly by se do jedné oblasti HBase, což pravděpodobně způsobilo oblast hotspot. Za druhé, HBase obsluhuje aplikaci Spendlytics pro zákazníky a Santander nechtěl, aby dodatečné zatížení ovlivnilo latenci aplikace nebo naopak. To je také důvod, proč jsme se rozhodli nepoužívat HBase ani k bootstrapu místních obchodů při spuštění.
Poskytnutím rychlého místního obchodu pro každého agenta Flume, který obohatí události během letu, je tedy Santander schopen poskytnout lepší záruky výkonu jak pro obohacení za letu, tak pro aplikaci Spendlytics. Rozhodli jsme se použít RocksDB k implementaci místních obchodů, protože je schopen poskytnout rychlý přístup k velkému množství dat mimo hromadu (eliminující zátěž na GC) a skutečnost, že má Java API, které usnadňuje používání z vlastní Flume Interceptor. Tento přístup nás uchránil od nutnosti kódovat náš vlastní sklad mimo halu. RocksDB lze snadno vyměnit za implementaci jiného místního obchodu, ale v tomto případě se dokonale hodil pro případ použití Santander.
Vlastní implementace Flume obohacení Interceptor zpracovává události z upstream „transformovaného“ tématu, dotazuje se svého místního obchodu, aby je obohatil, a zapisuje výsledky do navazujících témat Kafka v závislosti na výsledku. Tento proces je podrobněji ilustrován níže.
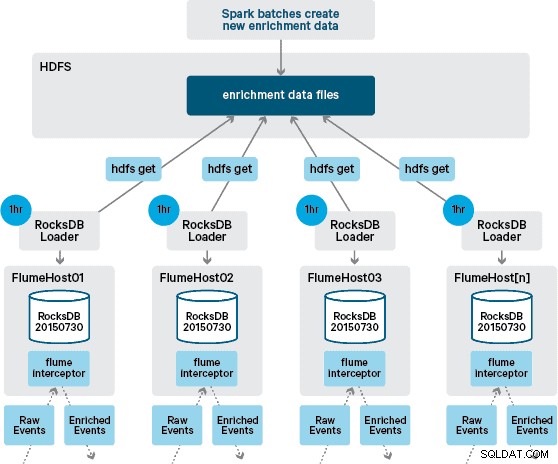
V tomto bodě se možná ptáte:Jak se generují místní úložiště, když není zajištěna persistence HBase? Referenční data obsahují řadu různých datových sad, které je třeba spojit dohromady. Tyto datové sady jsou denně obnovovány v HDFS a tvoří vstup pro naplánovanou aplikaci Apache Spark, která generuje úložiště RocksDB. Nově vygenerované obchody RocksDB jsou umístěny v HDFS, dokud je nestahují agenti Flume, aby bylo zajištěno, že stream událostí bude obohacen o nejnovější informace.
V ideálním případě bychom nemuseli čekat, až budou všechny tyto datové sady dostupné v HDFS, než bude možné je zpracovat. Pokud by tomu tak bylo, pak by aktualizace referenčních dat mohly být streamovány potrubím Flafka, aby se průběžně udržoval stav místních referenčních dat.
V našem původním návrhu jsme plánovali napsat a naplánovat přes cron skript pro dotazování HDFS, abychom zkontrolovali nové verze obchodů RocksDB a stáhli je z HDFS, až budou k dispozici. Ačkoli kvůli vnitřní kontrole a správě produkčního prostředí Santander musel být tento mechanismus začleněn do stejného Flume Interceptor, který se používá k provádění obohacení (kontroluje aktualizace jednou za hodinu, takže to není nákladná operace). Když je k dispozici nová verze obchodu, je pracovnímu vláknu odeslána úloha ke stažení nového obchodu z HDFS a načtení do RocksDB. Tento proces probíhá na pozadí, zatímco obohacovací interceptor pokračuje ve zpracování proudu. Jakmile je nová verze obchodu načtena do RocksDB, Interceptor se přepne na nejnovější verzi a expirovaný obchod je smazán. Stejný mechanismus se používá k bootstrapování obchodů RocksDB ze studeného spuštění předtím, než se Interceptor začne pokoušet o obohacení událostí.
Úspěšně obohacené zprávy se zapisují do tématu Kafka, aby byly idempotentně zapsány do HBase pomocí HBaseEventSerializer.
Zatímco stream událostí je zpracováván nepřetržitě, nové verze místního úložiště lze generovat pouze denně. Okamžitě poté, co Flume načte novou verzi místního obchodu, je považována za čerstvou,“ i když před dostupností nové verze je stále více zastaralá. V důsledku toho se počet „chybění mezipaměti“ zvyšuje, dokud nebude k dispozici novější verze místního obchodu. K referenčním údajům lze například přidat nové a aktualizované informace o značce a obchodníkovi, ale dokud nebudou k dispozici pro obohacení Flume, transakce interceptoru se nemusí podařit obohatit nebo obohatit o zastaralé informace, které bude nutné později odsouhlaseno poté, co bylo uchováno v HBase.
Aby se tento případ vyřešil, vyrovnávací paměť (události, které se nepodařilo obohatit) jsou zapsány do tématu Kafka „znovu“ pomocí nástroje Flume Selector. Když bude k dispozici nový místní obchod, téma opakování se poté přehraje zpět do zdrojového tématu interceptoru obohacení.
Abychom zabránili „jedovatým zprávám“ (událostem, které neustále selhávají v obohacení), rozhodli jsme se přidat počítadlo do záhlaví události, než ji přidáme do tématu opakování. Události, které se opakovaně objevují na toto téma, jsou nakonec přesměrovány na „kritické“ téma, které je zapsáno do HDFS pro pozdější kontrolu a nápravu. Tento přístup je znázorněn na prvním diagramu.
Závěr
Abychom shrnuli hlavní body z tohoto příspěvku:
- Použití řetězce témat Kafka k ukládání sdílených sdílených dat jako součásti vašeho kanálu příjmu je efektivní vzor.
- Máte několik možností pro uchování a dotazování na stavová nebo referenční data ve vašem kanálu zpracování NRT. Upřednostněte pro tento účel HBase jako běžný vzor, když jsou doplňková data velká, ale zvažte použití vestavěných místních úložišť (jako je RocksDB) nebo paměti JVM, když použití HBase není praktické.
- Ošetření selhání je důležité. (Nápovědu k tomu viz #1.)
V následném příspěvku popíšeme, jak využíváme koprocesory HBase k poskytování agregací historických nákupních trendů podle jednotlivých zákazníků a jak jsou offline transakce zpracovávány dávkově pomocí (projekt Cloudera Labs) SparkOnHBase (který byl nedávno přijat do HZákladní kufr). Popíšeme také, jak bylo řešení navrženo tak, aby vyhovovalo požadavkům zákazníka na vysokou dostupnost napříč datovými centry.
James Kinley, Ian Buss a Rob Siwicki jsou Solution Architects ve společnosti Cloudera.