Vyrovnávání zátěže databáze distribuuje souběžné požadavky klientů na více databázových serverů, aby se snížilo zatížení jakéhokoli jednotlivého serveru. To může výrazně zlepšit výkon vaší databáze. Naštěstí MongoDB ve výchozím nastavení dokáže zpracovat více požadavků klientů na současné čtení a zápis stejných dat. Využívá některé mechanismy kontroly souběžnosti a zamykací protokoly k zajištění konzistence dat za všech okolností.
Tímto způsobem MongoDB také zajišťuje, že všichni klienti získají kdykoli konzistentní pohled na data. Díky této vestavěné funkci zpracování požadavků od více klientů se nemusíte starat o přidání externího nástroje pro vyrovnávání zátěže na vaše servery MongoDB. I když, pokud stále chcete zlepšit výkon své databáze pomocí vyvažování zátěže, zde je několik způsobů, jak toho dosáhnout.
Vertikální škálování MongoDB
Zjednodušeně řečeno, vertikální škálování znamená přidání dalších zdrojů na váš server, které je potřeba zvládnout při načítání. Jako všechny databázové systémy i MongoDB preferuje větší kapacitu RAM a IO. Toto je nejjednodušší způsob, jak zvýšit výkon MongoDB bez rozložení zátěže na více serverů. Vertikální škálování databáze MongoDB obvykle zahrnuje zvýšení kapacity CPU nebo diskové kapacity a zvýšení propustnosti (I/O operace). Přidáním více zdrojů se váš mongo server stane schopnějším zpracovávat více požadavků klientů. Lepší vyrovnávání zátěže pro vaši databázi.
Nevýhodou použití tohoto přístupu je technické omezení přidávání zdrojů do jakéhokoli jednotlivého systému. Všichni poskytovatelé cloudu mají také omezení týkající se přidávání nových hardwarových konfigurací. Další nevýhodou tohoto přístupu je jediný bod selhání. V tomto přístupu jsou všechna vaše data uložena v jediném systému, což může vést k trvalé ztrátě vašich dat.
Vodorovné škálování MongoDB
Horizontální škálování znamená rozdělení databáze na bloky a jejich uložení na více serverů. Hlavní výhodou tohoto přístupu je, že můžete za běhu přidávat další servery a zvyšovat tak výkon databáze s nulovými prostoji. MongoDB poskytuje horizontální škálování prostřednictvím shardingu. Sharding MongoDB poskytuje další kapacitu pro rozložení zátěže zápisu na více serverů (úlomků). Zde lze na každý shard nahlížet jako na jednu nezávislou databázi a na kolekci všech shardů lze nahlížet jako na jednu velkou logickou databázi. Sdílení umožňuje vašemu MongoDB distribuovat data na více serverů a efektivně zpracovávat souběžné požadavky klientů. Zvyšuje tedy propustnost čtení a zápisu vaší databáze.
Sdílení MongoDB
Shard může být jedna instance mongoda nebo sada replik, která obsahuje podmnožinu databáze sharded mongo. Můžete převést fragmenty v sadě replik, abyste zajistili vysokou dostupnost dat a redundanci.
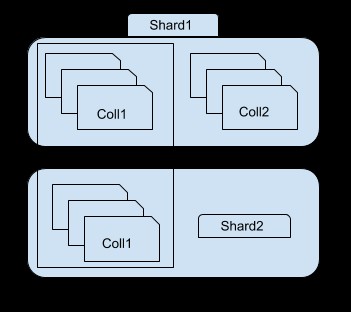
Jak můžete vidět na obrázku výše, úlomek 1 obsahuje podmnožinu kolekce 1 a celá kolekce2, zatímco střípek 2 obsahuje pouze další podmnožinu kolekce1. Ke každému fragmentu můžete přistupovat pomocí instance mongos. Pokud se například připojíte k instanci shard1, budete moci vidět/přistupovat pouze k podmnožině kolekce1.
Mongové
Mongos je směrovač dotazů, který poskytuje klientským aplikacím přístup ke sdílenému clusteru. Pro lepší vyrovnávání zátěže můžete mít více instancí mongos. Například ve svém produkčním klastru můžete mít jednu instanci mongos pro každý aplikační server. Nyní zde můžete použít externí nástroj pro vyrovnávání zatížení, který přesměruje požadavek vašeho aplikačního serveru na příslušnou instanci mongos. Při přidávání takových konfigurací na váš produkční server se ujistěte, že se připojení z jakéhokoli klienta vždy připojuje ke stejné instanci mongos, protože některé zdroje mongo, jako jsou kurzory, jsou specifické pro instanci mongos.
Konfigurační servery
Konfigurační servery ukládají nastavení konfigurace a metadata o vašem clusteru. Od verze MongoDB 3.4 musíte nasadit konfigurační servery jako sadu replik. Pokud povolujete sharding v produkčním prostředí, pak je povinné používat tři samostatné konfigurační servery, každý na jiném počítači.
Podle tohoto průvodce můžete převést cluster sady replik na sdílený cluster. Zde je ukázková ilustrace produkčního klastru:
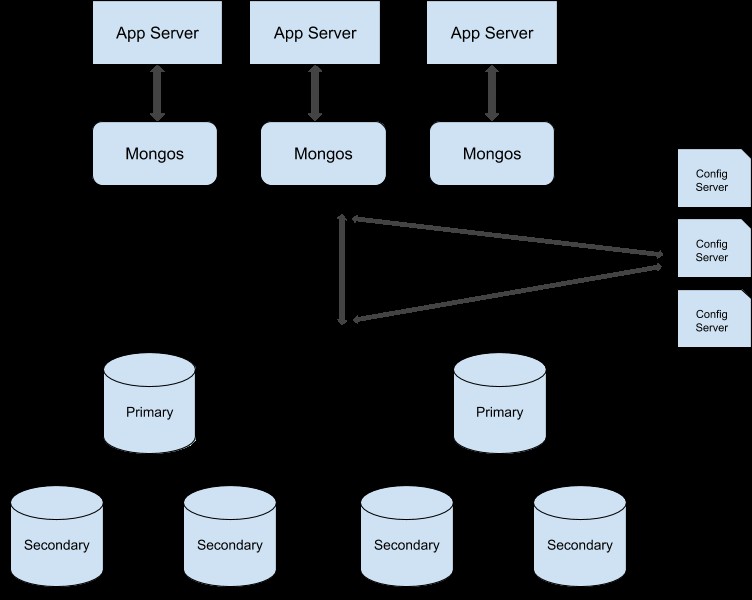
Vyrovnávání zátěže MongoDB pomocí replikace
Někdy lze replikaci MongoDB použít ke zpracování většího provozu od klientů a ke snížení zatížení primárního serveru. Chcete-li tak učinit, můžete dát klientům pokyn, aby četli ze sekundárních serverů namísto z primárního serveru. To může snížit zatížení primárního serveru, protože všechny požadavky na čtení přicházející od klientů budou zpracovány sekundárními servery a primární server se bude starat pouze o požadavky na zápis.
Následuje příkaz pro nastavení předvolby čtení na sekundární:
db.getMongo().setReadPref('secondary')Můžete také určit některé značky, které budou cílit na konkrétní sekundární položky při zpracování dotazů na čtení.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Zde se MongoDB pokusí najít sekundární uzel s hodnotou tagu datacenter jako APAC. Pokud je nalezen, Mongo bude obsluhovat požadavky na čtení ze všech sekundárních serverů s datovým centrem tagu:„APAC“. Pokud nebude nalezen, Mongo se pokusí najít sekundární položky s oblastí tagu:„East“. Pokud stále nejsou nalezeni žádní sekundární partneři, pak {} bude fungovat jako výchozí případ a Mongo bude obsluhovat požadavky od všech způsobilých sekundárních stránek.
Tento přístup pro vyvažování zátěže se však nedoporučuje používat pro zvýšení propustnosti čtení. Protože jakýkoli režim předvolby čtení jiný než primární může vrátit stará data v případě nedávných aktualizací zápisu na primární server. Primárnímu serveru obvykle nějakou dobu trvá zpracování požadavků na zápis a předání změn na sekundární servery. Pokud během této doby někdo požaduje operaci čtení se stejnými daty, sekundární server vrátí zastaralá data, protože nejsou synchronizována s primárním serverem. Tento přístup můžete použít, pokud je vaše aplikace náročná na operace čtení ve srovnání s operacemi zápisu.
Závěr
Vzhledem k tomu, že MongoDB dokáže zpracovávat souběžné požadavky sám, není třeba přidávat nástroj pro vyrovnávání zatížení do vašeho clusteru MongoDB. Pro vyrovnávání zátěže požadavků klienta si můžete vybrat buď vertikální škálování, nebo horizontální škálování, protože není vhodné používat sekundární prvky k škálování operací čtení a zápisu. Vertikální škálování může narazit na technické limity, jak je uvedeno výše. Proto je vhodný pro aplikace v malém měřítku. U velkých aplikací je horizontální škálování pomocí shardingu nejlepším přístupem pro vyrovnávání zátěže operací čtení a zápisu.