Získejte znalosti o budoucnosti nenahraditelného rámce Apache Hadoop.
Bez analýzy velkých dat jsou společnosti slepé a hluché a bloudí na web jako jelen po dálnici. – Geoffrey Moore, americký manažerský konzultant a autor.
V tomto článku uvidíme budoucnost Hadoopu v analýze velkých dat. Článek ukazuje předpovědi odborníků související s pracovními příležitostmi v Hadoopu. Uvidíte také seznam společností, které používají Hadoop, a různé domény, jako jsou finanční sektory, sektory zdravotnictví, které používají Hadoop.
Článek uvádí různé pracovní profily nabízené v rámci Big Data Hadoop.
Podívejme se nejprve na nárůst Big Data, který nutí společnosti přijmout Hadoop.
Růst velkých objemů dat
Předpovědi říkají, že do roku 2025 bude každý den celosvětově vytvořeno 463 exabajtů dat, což odpovídá 212 765 957 DVD za den!
Každý den se odešle 500 milionů tweetů, odešle se 294 miliard e-mailů, na Facebooku se vytvoří 4 petabajty dat, z každého připojeného auta se vytvoří 4 terabajty dat, na WhatsApp se odešle 65 miliard zpráv a mnoho dalších. V roce 2020 tak každý člověk generuje 1,7 MB za pouhou sekundu.
Dokážete si představit, že každý den generujeme 2,5 kvintilionu bajtů dat!!
Tato velká data bez informací nemají smysl. Startupy a společnosti z Fortune 500 využívají velká data k dosažení exponenciálního růstu.
Organizace si nyní uvědomily výhody analýzy velkých dat, která jim pomohla získat obchodní statistiky, což zlepšuje jejich možnosti rozhodování.
Bylo předpovídáno, že trh s velkými daty do roku 2023 dosáhne 103 miliard USD.
V roce 2020 vzroste množství globální datové sféry, která je předmětem analýzy dat, na 40 zettabytů, podle předpovědí.
Tradiční databáze nejsou dostatečně schopné zvládnout a analyzovat tak velký objem nestrukturovaných dat. Společnosti přijímají Hadoop k analýze velkých dat.
Podívejme se nyní, co přesně Hadoop je a proč vznikla potřeba Hadoopu, než prozkoumáme budoucnost Hadoopu.
Co je Hadoop a proč vznikla jeho potřeba?
S rozmachem světa velkých dat vyvstala potřeba bezchybných systémů, které dokážou zpracovávat, analyzovat, ukládat a získávat taková rostoucí velká data.
Tradiční databáze nejsou dostatečně schopné ukládat data generovaná v současné době z heterogenních zdrojů. Také nejsou schopny rychle zpracovat tato obrovská množství dat.
Hadoop vychází jako světlo ve světě analýzy velkých dat.
V roce 2008 Apache Software Foundation vyvinula Hadoop jako open-source softwarový rámec pro ukládání a zpracování obrovského množství dat. Má obrovský výpočetní výkon spolu se schopností paralelně zpracovávat a zpracovávat neomezený počet úkolů/úloh.
Kvůli jedinečným funkcím Hadoop , jako je jeho schopnost ukládat velká data, jeho rychlé zpracování, odolnost proti chybám, škálovatelnost a nákladová efektivita, lákají společnosti k přijetí Hadoop.
Hadoop také není jediné slovo; je to kompletní ekosystém známý jako Ekosystém Hadoop což přináší další bod pro Hadoop, který mohou organizace používat pro drcení velkých dat. Hadoop poskytuje vše, co potřebují, pod jedním deštníkem.
Trh Hadoop tedy roste den ode dne a má před sebou světlou budoucnost.
Budoucí rozsah Hadoop
Podle zprávy Forbes dosáhne trh Hadoop a Big Data v roce 2022 99,31 miliardy dolarů a dosáhne 28,5% CAGR.
Níže uvedený obrázek popisuje velikost trhu Hadoop a Big Data Market po celém světě od roku 2017 do roku 2022.
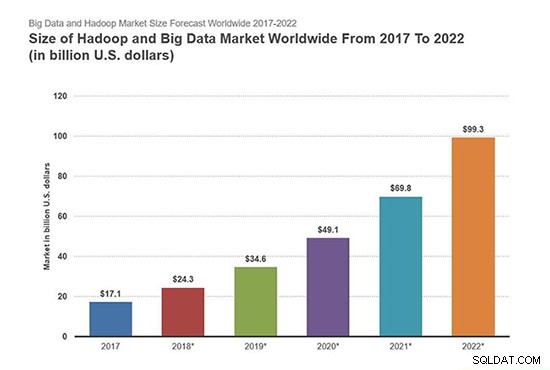
Zdroj obrázku – Forbes
Z výše uvedeného obrázku snadno vidíme vzestup Hadoopu a trhu s velkými daty. Naučit se Hadoop je tedy milníkem pro posílení kariéry v IT sektorech i v mnoha dalších oblastech.
Společnosti používající Hadoop
Výzkum ukazuje, že Hadoop má dobré vyhlídky na trhu v mnoha odvětvích. S příchodem digitálního vesmíru máme co do činění s datovou explozí. Jak čas plyne, neustále se objevují nové technologie, které přispívají k souboru dat.
Hadoop se ukázal jako průkopnické řešení pro zpracování a ukládání velkého množství dat. Trh Hadoop je distribuován v různých odvětvích.
Můžeme říci, že žádné odvětví není opuštěno, aby bylo součástí trhu Hadoop. Od odvětví výpočetní IT po průmyslová odvětví, jako jsou nemocnice a zdravotnictví, školství, finance, telekomunikace, maloobchod atd., na všech běží aplikace Hadoop.
S uvědoměním si výhod analýzy velkých dat je přijímání Hadoopu stále exponenciálnější.
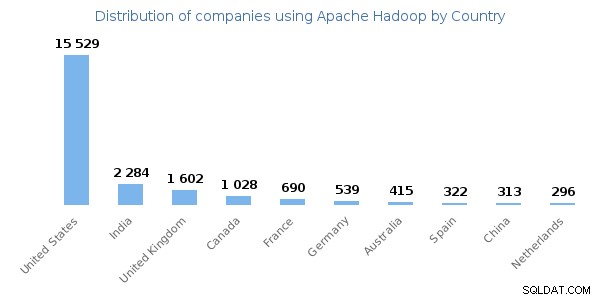
Zdroj obrázku – enlyft
Výše uvedený obrázek ukazuje distribuci společností využívajících Hadoop v jednotlivých zemích. Spojené státy americké jsou hlavním uživatelem technologie Hadoop.
Důvodem rostoucího trhu Hadoop je jeho nákladová efektivita, vysoká dostupnost, odolnost proti chybám a rychlá analýza dat.
Přestože existuje mnoho dalších nástrojů pro analýzu velkých dat, jako je Apache Spark , Flink atd. se vyvíjejí, aby se vypořádaly s velkými datovými výzvami, ale nikdo nemůže Hadoop v nadcházejících letech nahradit, protože nemají vlastní úložiště, v tom jsou závislí na Hadoopu.
I po více než 20 letech, pravděpodobně stále, nebude existovat žádná technologie, která by byla v souladu s příchodem velkých dat než Hadoop.
Velká data a Hadoop v různých doménách
Podívejme se nyní, jak Hadoop pomáhá podnikům řešit jejich problémy a ve kterých různých doménách jsou aplikace Hadoop provozovány.
a. Bankovní a finanční sektor
Bankovní a finanční průmysl čelí některým výzvám, jako jsou podvody s kartami, analýza ticků, archivace auditních záznamů, výkaznictví podnikových úvěrových rizik atd.
Používají Hadoop k získání včasného varování před bezpečnostními podvody a zviditelněním obchodu. Používají Hadoop k transformaci a analýze zákaznických dat pro lepší statistiky, analýzy předobchodního rozhodování a podpory atd.
b. Komunikace, média a zábava
Komunikační, mediální a zábavní průmysl čelí některým výzvám, jako je shromažďování a analýza spotřebitelských dat za účelem získání informací, hledání vzorců v používání médií v reálném čase, používání sociálních médií a mobilního obsahu.
Pomocí Hadoop tyto společnosti analyzují data zákazníků pro lepší statistiky a vytvářejí obsah pro různé cílové skupiny.
Například Wimbledon Championships používá velká data k poskytování podrobné analýzy sentimentu z tenisových zápasů uživatelům v reálném čase.
c. Poskytovatelé zdravotní péče
Sektory zdravotnictví pomocí Hadoop analyzují nestrukturovaný formát dat, který zahrnuje historii pacientů a historii onemocnění. To jim pomáhá efektivně léčit pacienty na základě předchozích kazuistik.
Identifikací onemocnění, které je v konkrétní oblasti běžné, lze také přijmout preventivní opatření a zpřístupnit těmto oblastem léky.
Floridská univerzita používá bezplatná data o veřejném zdraví a Mapy Google k vizualizaci dat, která umožňují rychlejší identifikaci šíření chronických onemocnění.
d. Vzdělání
Vzdělávací sektor výrazně využívá velká data. Tasmánská univerzita s 26 000 studenty nasadila LMS (Learning Management System), který sleduje dobu záznamu, kolik času studenti stráví na různých stránkách a celkový pokrok studenta v průběhu času.
e. Vláda
Existují různé vládní programy, které jsou v realizaci a ohromně generují data. Úřad pro potraviny a léčiva (FDA) používá velká data k detekci a studiu vzorců nemocí souvisejících s potravinami, což umožňuje rychlejší reakce na léčbu
Předpovědi práce v analýze velkých dat
Do roku 2023 dosáhne trh analýzy velkých dat podle předpovědí 103 miliard dolarů. IBM předpovídá, že poptávka po datových vědcích stoupne o 28 %.
Více než 97,2 % organizací investuje do velkých dat a AI.
Podle zprávy PwC bude do roku 2022 pouze v USA přibližně 2,7 milionu volných pracovních míst v oblasti datové analýzy a datové vědy. Největší společnosti jako Cisco, Dell, EY, IBM, Google, Siemens, Twitter, OCBC banka hledají odborníky na Hadoop pro zpracování a zisk z moře dostupných dat.
Zejména ve finančním průmyslu, pojišťovnictví a IT odvětví vyžadují 59 % všech pracovních míst datových vědců.
Níže uvedený obrázek ukazuje průměrné platy profesionálů s příslušnými analytickými schopnostmi. 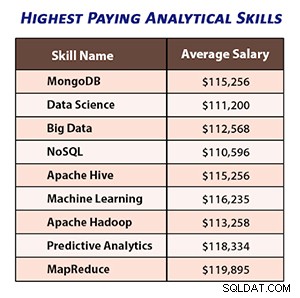
Zdroj obrázku – skutečně
Podle nedávné zprávy IBM vydělávají odborníci na Data Science a Data Analytics, kteří mají dovednosti MapReduce, v průměru 115 907 $ ročně, což z MapReduce činí nejžádanější dovednost.
Věda o datech a analytici s odbornými znalostmi v oblastech Apache Hadoop, Hive a Pig soutěží o pracovní místa za více než 100 000 $.
Platy a pracovní pozice pro Big Data Analytics
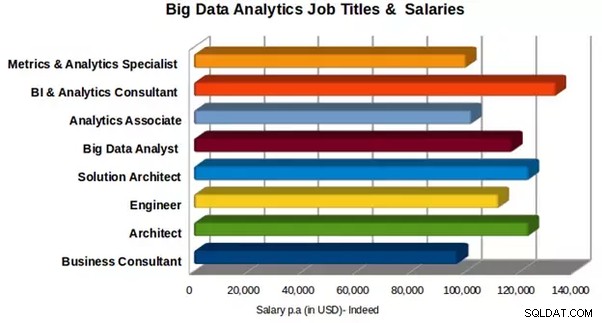
Průměrná roční mzda ve Spojeném království je 66 250–66 750 GBP pro pracovní místa Hadoop a 92 512 až 102 679 $ pro vývojáře Hadoop, podle Indeed.
Existují různé pracovní profily, které se hodí pro osoby s relevantními dovednostmi v Hadoopu. Některé z nich jsou:
Administrátor Hadoop
Administrátor Hadoop nastaví klastr Hadoop a monitoruje jej pomocí monitorovacích nástrojů. Sleduje připojení a zabezpečení clusteru.
Nabízený plat se pohybuje mezi INR 10–15 LPA .
Hadoop Architect
Hadoop Architect je ten, kdo plánuje a navrhuje architekturu Big Data Hadoop. Vytváří analýzu požadavků a řídí vývoj a nasazení napříč aplikacemi Hadoop. Nabízený plat se pohybuje mezi INR 9–11 LPA .
Big Data Analyst
Big Data Analyst analyzuje velká data pro hodnocení technické výkonnosti společností a dává doporučení na vylepšení systému. Provádějí procesy velkých dat, jako je textová anotace, analýza, obohacení filtrováním. Předem vytvořený plat je INR 7–10 LPA .
Vývojář Hadoop
Hlavním úkolem vývojáře Hadoop je vyvíjet technologie Hadoop pomocí Java, HQL a skriptovacích jazyků. Nabízený plat se pohybuje mezi INR 5–10 LPA v závislosti na pracovních profilech v Indii.
Hadoop Tester
Hadoop tester testuje chyby a chyby a opravuje chyby. Zajistí, aby MapReduce úlohy, skripty HiveQL a skripty Pig Latin fungují správně. Plat Hadoop Testera se pohybuje mezi INR 5–10 LPA .
Shrnutí
Doufám, že po přečtení tohoto článku si nyní dobře uvědomujete budoucnost Hadoopu. Žádná technologie ani po 20 letech nenahradí Apache Hadoop. Hadoop je tedy pro člověka, který hledá svou kariéru v oboru, který nikdy nevyjde z módy, tou nejlepší volbou.
Jste ohromeni budoucností Hadoop?
Tak na co čekáš? Začněte se učit hadoop a získejte svou vysněnou práci a balíček ve svých oblíbených zemích.
Postupujte podle TechVidvan na levém postranním panelu a začněte se učit Hadoop.
Pokračujte v učení!!