Hlavním cílem tohototutoriálu Hadoop je poskytnout vám podrobný popis každé součásti, která se používá při práci s Hadoopem. V tomto tutoriálu se budeme zabývat Partitionerem v Hadoopu.
Co je Hadoop Partitioner, co je potřeba Partitioner v Hadoop, Jaký je výchozí Partitioner v MapReduce, Kolik MapReduce Partitioner se používá v Hadoop?
Na všechny tyto otázky odpovíme v tomto tutoriálu MapReduce.
Co je Hadoop Partitioner?
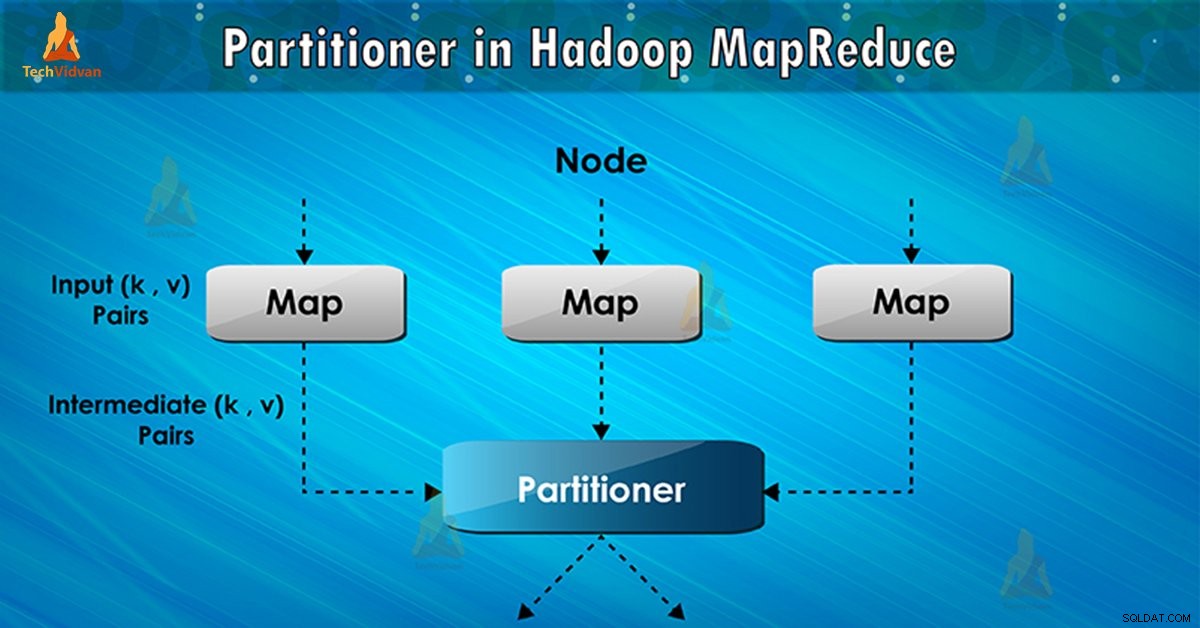
Partitioner v provádění úlohy MapReduce řídí rozdělení klíčů přechodných mapových výstupů. Pomocí hašovací funkce klíč (nebo podmnožina klíče) odvodí oddíl. Celkový počet oddílů se rovná počtu úloh snížení.
Na základě klíčové hodnoty , rámcové oddíly, každýmapovač výstup. Záznamy se stejnou hodnotou klíče jdou do stejného oddílu (v rámci každého mapovače). Poté je každý oddíl odeslán do reduktoru .
Třída oddílu rozhoduje, do kterého oddílu daný pár (klíč, hodnota) půjde. Fáze rozdělení v datovém toku MapReduce probíhá po fázi mapy a před fází zmenšení.
Potřeba MapReduce Partitioner v Hadoop
Při provádění úlohy MapReduce vezme sadu vstupních dat a vytvoří seznam párů klíč-hodnota. Tento pár klíč–hodnota je výsledkem fáze mapování. Ve kterém jsou vstupní data rozdělena a každá úloha zpracovává rozdělení a každou mapu, vypíše seznam párů klíč-hodnota.
Poté framework odešle mapový výstup, aby se úkol snížil. Procesy redukce uživatelsky definovaná funkce redukce na mapových výstupech. Před fází zmenšení proběhne rozdělení výstupu mapy na základě klíče.
Hadoop Partitioning určuje, že všechny hodnoty pro každý klíč jsou seskupeny. Také zajišťuje, že všechny hodnoty jednoho klíče jdou do stejného reduktoru. To umožňuje rovnoměrné rozložení mapového výstupu přes redukci.
Partitioner v úloze MapReduce přesměruje výstup mapovače do reduktoru určením, který reduktor zpracovává konkrétní klíč.
Výchozí rozdělovač Hadoop
Hash Partitioner je výchozí oddíl. Vypočítá hodnotu hash pro klíč. Na základě tohoto výsledku také přiřadí oddíl.
Kolik Partitionerů v Hadoopu?
Celkový počet rozdělovačů závisí na počtu reduktorů. Hadoop Partitioner rozděluje data podle počtu reduktorů. Nastavuje se pomocí JobConf.setNumReduceTasks() metoda.
Jediný reduktor tedy zpracovává data z jednoho oddílu. Důležité je poznamenat, že framework vytváří partitioner pouze v případě, že existuje mnoho reduktorů.
Špatné rozdělení v Hadoop MapReduce
Pokud se při zadávání dat v úloze MapReduce objeví jeden klíč více než kterýkoli jiný. V takovém případě k odeslání dat do oddílu používáme dva následující mechanismy:
- Klíč, který se objeví vícekrát, bude odeslán do jednoho oddílu.
- Všechny ostatní klíče budou odeslány do oddílů na základě jejich hashCode() .
Pokud hashCode() metoda nedistribuuje další klíčová data v rozsahu oddílu. Potom nebudou data odeslána do reduktorů.
Špatné rozdělení dat znamená, že některé reduktory budou mít více datových vstupů ve srovnání s jinými. Budou mít více práce než ostatní reduktory. Celá zakázka tak musí čekat, až jeden reduktor dokončí svůj extra velký podíl zátěže.
Jak překonat špatné rozdělení v MapReduce?
Abychom překonali špatné rozdělení na oddíly v Hadoop MapReduce, můžeme vytvořit vlastní oddíl. To umožňuje sdílení pracovní zátěže mezi různými reduktory.
Závěr
Na závěr, Partitioner umožňuje rovnoměrné rozložení mapového výstupu přes redukci. V MapReducer Partitioner se rozdělování mapového výstupu děje na základě klíče a hodnoty.
Proto jsme v tomto blogu pokryli kompletní přehled Partitioneru. Doufám, že se vám to líbilo. Pokud vás napadne nějaká pochybnost o Hadoop Partitioneru, tak se s námi nezapomeňte podělit.