Pojem dobrý nebo špatný design je relativní. Zároveň existují některé programovací standardy, které ve většině případů zaručují efektivitu, udržovatelnost a testovatelnost. Například v objektově orientovaných jazycích se jedná o použití zapouzdření, dědičnosti a polymorfismu. Existuje soubor návrhových vzorů, které mají v řadě případů pozitivní nebo negativní vliv na návrh aplikace v závislosti na situaci. Na druhou stranu existují protiklady, jejichž následování někdy vede k návrhu problému.
Tento návrh má obvykle následující indikátory (jeden nebo několik najednou):
- Rigidita (je obtížné upravit kód, protože jednoduchá změna ovlivní mnoho míst);
- Imobilita (je komplikované rozdělit kód do modulů, které lze použít v jiných programech);
- Viskozita (je poměrně obtížné vyvinout nebo otestovat kód);
- Zbytečná složitost (v kódu je nevyužitá funkce);
- Zbytečné opakování (Kopírovat/Vložit);
- Špatná čitelnost (je obtížné porozumět tomu, k čemu je kód navržen, a udržet jej);
- Křehkost (funkci lze snadno narušit i při malých změnách).
Musíte být schopni těmto funkcím porozumět a rozlišit je, abyste se vyhnuli problémovému návrhu nebo předvídali možné důsledky jeho použití. Tyto indikátory jsou popsány v knize «Agilní principy, vzorce a postupy v C#» od Roberta Martina. V tomto článku i v jiných článcích recenze je však stručný popis a žádné příklady kódu.
Chystáme se odstranit tuto nevýhodu spočívající v každé funkci.
Tuhost
Jak již bylo zmíněno, rigidní kód je obtížné upravit, dokonce i ty nejmenší věci. To nemusí být problém, pokud se kód nemění často nebo vůbec. Kód se tedy ukazuje jako docela dobrý. Pokud je však nutné kód upravit a je to obtížné, stává se to problémem, i když to funguje.
Jedním z oblíbených případů rigidity je explicitní určení typů tříd namísto použití abstrakcí (rozhraní, základní třídy atd.). Níže naleznete příklad kódu:
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
} Zde třída A velmi závisí na třídě B. Pokud tedy v budoucnu budete potřebovat použít jinou třídu místo třídy B, bude to vyžadovat změnu třídy A a povede to k jejímu opětovnému testování. Pokud navíc třída B ovlivní jiné třídy, situace se značně zkomplikuje.
Řešením je abstrakce, která má zavést rozhraní IComponent prostřednictvím konstruktoru třídy A. V tomto případě již nebude záviset na konkrétní třídě В a bude záviset pouze na rozhraní IComponent. Сlass В musí implementovat rozhraní IComponent.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
} Uveďme konkrétní příklad. Předpokládejme, že existuje sada tříd, které zaznamenávají informace – ProductManager a Consumer. Jejich úkolem je uložit produkt do databáze a odpovídajícím způsobem jej objednat. Obě třídy zaznamenávají relevantní události. Představte si, že nejprve existoval log do souboru. K tomu byla použita třída FileLogger. Kromě toho byly třídy umístěny v různých modulech (sestavení).
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
} Pokud nejprve stačilo použít pouze soubor, a pak bude nutné přihlásit se do jiných úložišť, jako je databáze nebo cloudová služba pro sběr a ukládání dat, budeme muset změnit všechny třídy v obchodní logice. modul (Modul 2), které používají FileLogger. To se ostatně může ukázat jako obtížné. K vyřešení tohoto problému můžeme zavést abstraktní rozhraní pro práci s loggerem, jak je ukázáno níže.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
} V tomto případě stačí při změně typu loggeru upravit klientský kód (Main), čímž se logger inicializuje a přidá do konstruktoru ProductManager a Consumer. Tím jsme podle potřeby uzavřeli třídy obchodní logiky z modifikace typu logger.
Kromě přímých vazeb na použité třídy můžeme sledovat rigiditu i v dalších variantách, které mohou vést k potížím při úpravě kódu. Může jich být nekonečná množina. Pokusíme se však uvést jiný příklad. Předpokládejme, že existuje kód, který zobrazuje oblast geometrického vzoru na konzole.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
} Jak vidíte, při přidávání nového vzoru budeme muset změnit metody třídy ShapeHelper. Jednou z možností je předat algoritmus vykreslování ve třídách geometrických vzorů (Obdélník a Kruh), jak je uvedeno níže. Tímto způsobem izolujeme příslušnou logiku v odpovídajících třídách, čímž snížíme odpovědnost třídy ShapeHelper před zobrazením informací na konzole.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
} V důsledku toho jsme ve skutečnosti uzavřeli třídu ShapeHelper pro změny, které přidávají nové typy vzorů pomocí dědičnosti a polymorfismu.
Imobilita
Můžeme sledovat nehybnost při rozdělování kódu do opakovaně použitelných modulů. V důsledku toho se projekt může přestat rozvíjet a být konkurenceschopný.
Jako příklad budeme uvažovat desktopový program, jehož celý kód je implementován ve spustitelném aplikačním souboru (.exe) a byl navržen tak, aby obchodní logika nebyla postavena v samostatných modulech nebo třídách. Později vývojář čelil následujícím obchodním požadavkům:
- změnit uživatelské rozhraní jeho přeměnou na webovou aplikaci;
- Zveřejnit funkce programu jako sadu webových služeb dostupných klientům třetích stran pro použití v jejich vlastních aplikacích.
V tomto případě je obtížné tyto požadavky splnit, protože celý kód je umístěn ve spustitelném modulu.
Na obrázku níže je příklad nepohyblivého provedení na rozdíl od toho, které tento indikátor nemá. Jsou odděleny tečkovanou čarou. Jak je vidět, alokace kódu na opakovaně použitelných modulech (Logic), stejně jako zveřejnění funkčnosti na úrovni webových služeb, umožňuje jeho použití v různých klientských aplikacích (App), což je nepochybná výhoda.
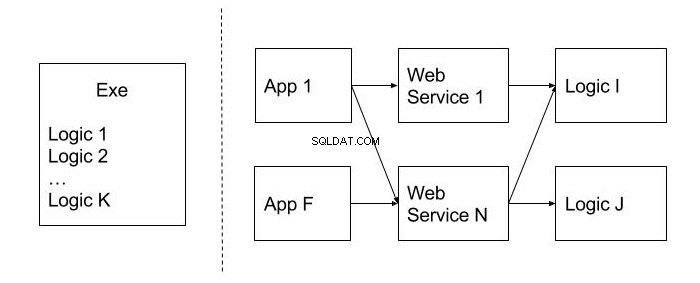
Imobilita může být také nazývána monolitickým designem. Je obtížné jej rozdělit na menší a užitečné jednotky kódu. Jak se můžeme tomuto problému vyhnout? Ve fázi návrhu je lepší přemýšlet o tom, jak pravděpodobné je použití té či oné funkce v jiných systémech. Kód, u kterého se očekává opětovné použití, je nejlepší umístit do samostatných modulů a tříd.
Viskozita
Existují dva typy:
- Vývojová viskozita
- Viskozita prostředí
Vidíme vývojovou viskozitu při snaze dodržet zvolený design aplikace. To se může stát, když programátor potřebuje splnit příliš mnoho požadavků a přitom existuje jednodušší způsob vývoje. Kromě toho lze vývojovou viskozitu vidět, když proces montáže, nasazení a testování není efektivní.
Jako jednoduchý příklad můžeme uvažovat práci s konstantami, které mají být umístěny (By Design) do samostatného modulu (Modul 1) pro použití dalšími komponentami (Modul 2 a Modul 3).
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
} Pokud z jakéhokoli důvodu proces sestavení zabere mnoho času, bude pro vývojáře obtížné čekat na jeho dokončení. Navíc je třeba poznamenat, že konstantní modul obsahuje smíšené entity, které patří do různých částí obchodní logiky (finanční a marketingové moduly). Konstantní modul lze tedy poměrně často měnit z důvodů, které jsou na sobě nezávislé, což může vést k dalším problémům, jako je synchronizace změn.
To vše zpomaluje proces vývoje a může programátory vystresovat. Varianty méně viskózního designu by byly buď vytvoření samostatných konstantních modulů – jeden pro odpovídající modul obchodní logiky – nebo předání konstant na správné místo, aniž by pro ně byl použit samostatný modul.
Příkladem viskozity prostředí může být vývoj a testování aplikace na virtuálním počítači vzdáleného klienta. Někdy se tento pracovní postup stane neúnosným kvůli pomalému připojení k internetu, takže vývojář může systematicky ignorovat testování integrace napsaného kódu, což může nakonec vést k chybám na straně klienta při používání této funkce.
Zbytečná složitost
V tomto případě má design vlastně nevyužitou funkčnost. Tato skutečnost může zkomplikovat podporu a údržbu programu a také prodloužit dobu vývoje a testování. Vezměme si například program, který vyžaduje čtení některých dat z databáze. K tomu byla vytvořena komponenta DataManager, která se používá v jiné komponentě.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
} Pokud vývojář přidá do DataManageru novou metodu pro zápis dat do databáze (WriteData), která pravděpodobně nebude v budoucnu použita, bude to také zbytečná složitost.
Dalším příkladem je rozhraní pro všechny účely. Například budeme uvažovat o rozhraní s metodou single Process, která přijímá objekt typu string.
interface IProcessor
{
void Process(string message);
} Pokud by úkolem bylo zpracovat určitý typ zprávy s dobře definovanou strukturou, pak by bylo snazší vytvořit striktně typované rozhraní, než nutit vývojáře deserializovat tento řetězec pokaždé na konkrétní typ zprávy.
Nadměrné používání návrhových vzorů v případech, kdy to není vůbec nutné, může vést také k návrhu viskozity.
Proč ztrácet čas psaním potenciálně nepoužívaného kódu? Někdy QA testuje tento kód, protože je skutečně publikován a je otevřen pro použití klienty třetích stran. To také oddaluje čas vydání. Zahrnout funkci pro budoucnost se vyplatí pouze tehdy, pokud její možný přínos převýší náklady na její vývoj a testování.
Zbytečné opakování
Možná většina vývojářů čelila nebo narazí na tuto funkci, která spočívá ve vícenásobném kopírování stejné logiky nebo kódu. Hlavní hrozbou je zranitelnost tohoto kódu při jeho úpravách – opravou něčeho na jednom místě to můžete zapomenout udělat na jiném. Navíc provedení změn zabere více času ve srovnání se situací, kdy kód tuto funkci neobsahuje.
Zbytečné opakování může být způsobeno nedbalostí vývojářů a také rigiditou/křehkostí designu, kdy je mnohem obtížnější a riskantnější kód neopakovat, než to udělat. V každém případě však opakovatelnost není dobrý nápad a je nutné kód neustále vylepšovat a předávat znovu použitelné části běžným metodám a třídám.
Špatná čitelnost
Tuto funkci můžete sledovat, když je obtížné přečíst kód a pochopit, k čemu je vytvořen. Důvody špatné čitelnosti mohou být nesoulad s požadavky na provádění kódu (syntaxe, proměnné, třídy), komplikovaná implementační logika atd.
Níže naleznete příklad obtížně čitelného kódu, který implementuje metodu s proměnnou Boolean.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
} Zde můžeme nastínit několik problémů. Za prvé, názvy metod a proměnných neodpovídají obecně uznávaným konvencím. Za druhé, implementace metody není nejlepší.
Možná stojí za to vzít booleovskou hodnotu spíše než řetězec. Je však lepší ji převést na booleovskou hodnotu na začátku metody, než používat metodu určování délky řetězce.
Za třetí, text výjimky neodpovídá oficiálnímu stylu. Při čtení takových textů může nastat pocit, že kód vytvořil amatér (přesto tu může být problém). Metoda může být přepsána následovně, pokud má logickou hodnotu:
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
} Zde je další příklad refaktoringu, pokud stále potřebujete vzít řetězec:
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
} Doporučuje se provést refaktoring s obtížně čitelným kódem, například když jeho údržba a klonování vede k četným chybám.
Křehkost
Křehkost programu znamená, že může být při úpravách snadno zhroucen. Existují dva typy selhání:chyby kompilace a chyby běhu. První mohou být zadní stranou tuhosti. Poslední jmenované jsou nejnebezpečnější, protože se vyskytují na straně klienta. Jsou tedy indikátorem křehkosti.
Není pochyb o tom, že ukazatel je relativní. Někdo opravuje kód velmi pečlivě a možnost jeho pádu je poměrně nízká, jiní to dělají ve spěchu a nedbale. Rozdílný kód se stejnými uživateli však může způsobit různé množství chyb. Pravděpodobně můžeme říci, že čím obtížnější je porozumět kódu a spoléhat se spíše na dobu provádění programu než na fázi kompilace, tím je kód křehčí.
Navíc funkce, která se nechystá upravovat, často padá. Může trpět vysokou provázaností logiky různých komponent.
Zvažte konkrétní příklad. Zde se logika autorizace uživatele s určitou rolí (definovanou jako rolovaný parametr) pro přístup ke konkrétnímu zdroji (definovaná jako resourceUri) nachází ve statické metodě.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
} Jak vidíte, logika je složitá. Je zřejmé, že přidáním nových rolí a prostředků se to snadno rozbije. V důsledku toho může určitá role získat nebo ztratit přístup ke zdroji. Vytvoření třídy Resource, která interně ukládá identifikátor zdroje a seznam podporovaných rolí, jak je uvedeno níže, by snížilo nestabilitu.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
} V tomto případě pro přidání nových zdrojů a rolí není nutné vůbec upravovat kód autorizační logiky, to znamená, že vlastně není co rozbít.
Co může pomoci zachytit běhové chyby? Odpovědí je ruční, automatické a jednotkové testování. Čím lépe je testovací proces organizován, tím je pravděpodobnější, že se křehký kód objeví na straně klienta.
Křehkost je často zadní stranou jiných identifikátorů špatného designu, jako je tuhost, špatná čitelnost a zbytečné opakování.
Závěr
Pokusili jsme se nastínit a popsat hlavní identifikátory špatného designu. Některé z nich jsou na sobě závislé. Musíte pochopit, že problém designu ne vždy nevyhnutelně vede k potížím. Poukazuje pouze na to, že k nim může dojít. Čím méně jsou tyto identifikátory sledovány, tím je tato pravděpodobnost nižší.