V tomto článku se zaměříme na provozní analytiku v reálném čase a na to, jak tento přístup aplikovat na databázi OLTP. Když se podíváme na tradiční analytický model, vidíme, že OLTP a analytická prostředí jsou samostatné struktury. Za prvé, tradiční prostředí analytických modelů musí vytvářet úlohy ETL (Extract, Transform and Load). Protože potřebujeme přenést transakční data do datového skladu. Tyto typy architektury mají některé nevýhody. Jsou to náklady, složitost a latence dat. Abychom tyto nevýhody odstranili, potřebujeme jiný přístup.
Provozní analýza v reálném čase
Microsoft oznámil Real-Time Operational Analytics v SQL Server 2016. Schopností této funkce je kombinovat pracovní zátěž transakční databáze a analytických dotazů bez jakýchkoli problémů s výkonem. Operační analýza v reálném čase poskytuje:
- hybridní struktura
- transakční a analytické dotazy lze provádět současně
- nezpůsobuje žádné problémy s výkonem a latencí.
- jednoduchá implementace.
Tato funkce může překonat nevýhody tradičního analytického prostředí. Hlavním tématem této funkce je, že index úložiště sloupců uchovává kopii dat bez ovlivnění výkonu transakčního systému. Toto téma umožňuje provádění analytických dotazů bez ovlivnění výkonu. Takže to minimalizuje dopad na výkon. Hlavním omezením této funkce je, že nemůžeme shromažďovat data z různých zdrojů dat.
Index úložiště neklasifikovaných sloupců
SQL Server 2016 zavádí aktualizovatelný „index neklastrovaného úložiště sloupců“. Index neklastrovaného úložiště sloupců je index založený na sloupcích, který poskytuje výhody výkonu pro analytické dotazy. Tato funkce nám umožňuje vytvořit rámec provozní analýzy v reálném čase. To znamená, že můžeme provádět transakce a analytické dotazy současně. Zvažte, že potřebujeme celkové měsíční tržby. V tradičním modelu musíme vyvinout úlohy ETL, data mart a datový sklad. Ale v reálném čase provozní analýzy to můžeme dělat, aniž bychom vyžadovali jakýkoli datový sklad nebo jakékoli změny ve struktuře OLTP. Potřebujeme pouze vytvořit vhodný neklastrovaný index úložiště sloupců.
Architektura neklastrovaného indexu úložiště sloupců
Podívejme se krátce na architekturu indexu úložiště sloupců bez klastrů a spouštěcího mechanismu. Index úložiště neklastrovaných sloupců obsahuje kopii části nebo všech řádků a sloupců v podkladové tabulce. Hlavním tématem indexu úložiště bez klastrů je udržovat kopii dat a používat tuto kopii dat. Tento mechanismus tedy minimalizuje dopad na výkon transakční databáze. Neklastrovaný index úložiště sloupců může vytvořit jeden nebo více sloupců a může na sloupce použít filtr.
Když vložíme nový řádek do tabulky, která má neshlukovaný index úložiště sloupců, nejprve SQL Server vytvoří „skupinu řádků“. Skupina řádků je logická struktura, která představuje sadu řádků. SQL Server pak tyto řádky uloží do dočasného úložiště. Název tohoto dočasného úložiště je „deltastore“. SQL Server používá tuto oblast dočasného úložiště, protože tento mechanismus zlepšuje kompresní poměr a snižuje fragmentaci indexu. Když počet řádků dosáhne 1 048 577, SQL Server zavře stav skupiny řádků. SQL Server zkomprimuje tuto skupinu řádků a změní stav na „komprimovaný“.
Nyní vytvoříme tabulku a přidáme index úložiště neklastrovaných sloupců.
DROP TABLE IF EXISTS Analysis_TableTestCREATE TABLE Analysis_TableTest(ID INT PRIMÁRNÍ KLÍČ IDENTITY(1,1),Název_kontinentu VARCHAR(20),Název_země VARCHAR(20),Název_města VARCHAR(20),ProdejVYTVOŘTE INDEX NENCLUSTERED COLUMNSTORE [NonClusteredColumnStoreIndex] ZAPNUTO [dbo].[Analysis_TableTest]( [Country_Name], [City_Name] , Sales_Amnt)S (DROP_EXISTING =VYPNUTO, KOMPRESE)_ZPOŽDĚNÍ] [před ŘÁDEM]V tomto kroku vložíme několik řádků a podíváme se na vlastnosti neklastrovaného indexu úložiště sloupců.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Mnichov','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('Amerika','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japonsko','Tokio','190','17')GOTento dotaz zobrazí stavy skupiny řádků, celkový počet velikostí řádků a další hodnoty.
SELECT i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, CSRowGroups.*, 100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull FROM sys.indexes AS i PŘIPOJIT SE k sys.column_store_row_groups JAKO CSRowGroups ON i.object_id =CSRowGroups.object_id AND i.index_id =CSRowGroups.index_id ORDER BY object_name(i.object_id), i.name, row_group_id;
Obrázek výše nám ukazuje stav deltastore a celkový počet řádků, které nejsou komprimovány. Nyní do tabulky vyplníme další data, a když počet řádků dosáhne 1 048 577, SQL Server zavře první skupinu řádků a otevře novou skupinu řádků.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Mnichov','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('Amerika','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asie','Japonsko','Tokio','190','17')GO 2000000
SQL Server zkomprimuje tuto skupinu řádků a vytvoří novou skupinu řádků. Možnost „COMPRESSION_DELAY“ nám umožňuje řídit, jak dlouho bude skupina řádků čekat v uzavřeném stavu.
Když spustíme příkazy pro údržbu indexu (reorganize, rebuild), odstraněné řádky jsou fyzicky odstraněny a index je defragmentován.
Když aktualizujeme (smažeme + vložíme) některé řádky v této tabulce, smazané řádky jsou označeny jako „smazané“ a nové aktualizované řádky jsou vloženy do deltastore.
Srovnání výkonu analytických dotazů
V tomto záhlaví vyplníme data do tabulky Analysis_TableTest. Vložil jsem 4 miliony záznamů. (Tento krok a další kroky musíte otestovat ve svém testovacím prostředí. Mohou nastat problémy s výkonem a také příkaz DBCC DROPCLEANBUFFERS může snížit výkon. Tento příkaz odstraní všechna data vyrovnávací paměti ve fondu vyrovnávacích pamětí.)
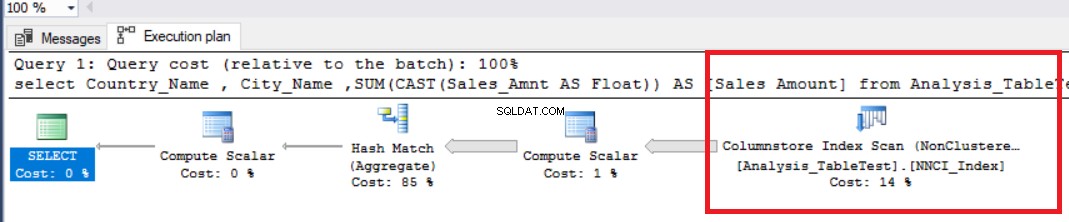
Nyní spustíme následující analytický dotaz a prozkoumáme hodnoty výkonu.
NASTAVTE STATISTIKY STATISTIKY ČASOVÉHO NÁSTUPU IO ONDBCC DROPCLEANBUFFERSvyberte Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount]ze skupiny Analysis_TableTest byCountry_Name ,City_Name
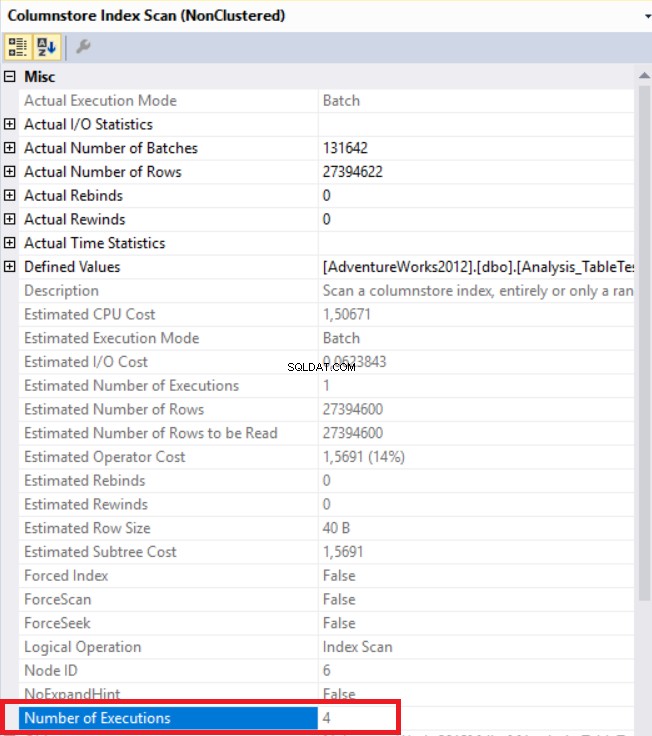
Na obrázku výše vidíme operátor skenování indexu úložiště neshluků. Níže uvedená tabulka ukazuje CPU a doby provádění. Tento dotaz spotřebuje 1,765 milisekundy v CPU a je dokončen za 0,791 milisekundy. Čas CPU je delší než uplynulý čas, protože plán provádění používá paralelní procesory a rozděluje úlohy na 4 procesory. Můžeme to vidět ve vlastnostech operátora „Columnstore Index Scan“. Udává to hodnota „Počet provedení“.
Nyní do dotazu přidáme nápovědu pro snížení počtu procesorů. Neuvidíme žádný operátor paralelismu.
NASTAVTE STATISTIKY STATISTIKY ČASOVÉHO NÁSTUPU IO ONDBCC DROPCLEANBUFFERSvyberte název země , název_města ,SUM(CAST(Sales_Amnt AS Float)) JAKO [Částka prodeje]ze skupiny Analysis_TableTest byCountry_Name ,Název_městaOPTION> (MAXD)
Níže uvedená tabulka definuje doby provádění. V tomto grafu můžeme vidět, že uplynulý čas je delší než čas CPU, protože SQL Server používal pouze jeden procesor.
Nyní zakážeme index úložiště neklastrovaných sloupců a provedeme stejný dotaz.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLEGOSET STATISTICS TIME ONSET STATISTICS IO ONDBCD DROPCLEANBUFFERSvyberte Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float_Countation) OD [SalesNast. 1)
Výše uvedená tabulka nám ukazuje, že index úložiště sloupců bez klastrů poskytuje neuvěřitelný výkon v analytických dotazech. Indexovaný dotaz úložiště sloupců je přibližně pětkrát lepší než druhý.
Závěr
Operační analýzy v reálném čase poskytují neuvěřitelnou flexibilitu, protože můžeme provádět analytické dotazy v systémech OLTP bez jakékoli datové latence. Tyto analytické dotazy zároveň neovlivňují výkon databáze OLTP. Tato funkce nám umožňuje spravovat transakční data a analytické dotazy ve stejném prostředí.
Odkazy
Indexy ukládání sloupců – Pokyny k načítání dat
Začněte s Column store pro provozní analýzy v reálném čase
Operační analýza v reálném čase
Další čtení:
Zpětné skenování indexu SQL Server:Porozumění, ladění
Použití indexů v tabulkách s optimalizovanou pamětí serveru SQL