V tomto článku se podíváme na operátor „APPLY“ a jeho varianty – CROSS APPLY a OUTER APPLY spolu s příklady, jak je lze použít.
Zejména se naučíme:
- rozdíl mezi CROSS APPLY a klauzulí JOIN
- jak propojit výstup SQL dotazů s funkcemi vyhodnocovanými tabulkou
- jak identifikovat problémy s výkonem pomocí dotazů na pohledy dynamické správy a funkce dynamické správy.
Co je klauzule APPLY
Microsoft zavedl operátor APPLY v SQL Server 2005. Operátor APPLY je podobný klauzuli T-SQL JOIN, protože také umožňuje spojit dvě tabulky – například můžete spojit vnější tabulku s vnitřní tabulkou. Operátor APPLY je dobrou volbou, když na jedné straně máme tabulkou vyhodnocený výraz, který chceme vyhodnotit pro každý řádek z tabulky, kterou máme na druhé straně. Pravá tabulka se tedy zpracovává pro každý řádek tabulky na levé straně. Nejprve se vyhodnotí tabulka na levé straně a poté se vyhodnotí tabulka na pravé straně s každým řádkem tabulky na levé straně, aby se vytvořila konečná sada výsledků. Konečná sada výsledků obsahuje všechny sloupce z obou tabulek.
Operátor APPLY má dvě varianty:
- POUŽÍT KRÍŽEM
- VNĚJŠÍ POUŽITÍ
POUŽÍT KRÍŽEM
CROSS APPLY je podobný INNER JOIN, ale lze jej také použít ke spojení funkcí vyhodnocovaných tabulkou s tabulkami SQL. Konečný výstup CROSS APPLY se skládá ze záznamů odpovídajících mezi výstupem funkce vyhodnocované tabulkou a tabulkou SQL.
VNĚJŠÍ POUŽITÍ
OUTER APPLY se podobá LEFT JOIN, ale má schopnost spojit funkce vyhodnocené tabulkou s tabulkami SQL. Konečný výstup OUTER APPLY obsahuje všechny záznamy z levé tabulky nebo funkce vyhodnocené tabulkou, i když se neshodují se záznamy v tabulce na pravé straně nebo funkci s hodnotou tabulky.
Nyní mi dovolte vysvětlit obě varianty na příkladech.
Příklady použití
Příprava nastavení ukázky
Chcete-li připravit demo nastavení, budete muset vytvořit tabulky s názvem „Zaměstnanci“ a „Oddělení“ v databázi, kterou budeme nazývat „DemoDatabáze“. Chcete-li to provést, spusťte následující kód:
POUŽÍVEJTE DEMODATABÁZI GO CREATE TABLE [DBO].[ZAMĚSTNANCI] ( [JMÉNO ZAMĚSTNANCE] [VARCHAR](MAX) NULL, [DATUM NAROZENÍ] [DATUM ČAS] NULL, [NÁZEV PRÁCE] [VARCHAR](150) NULL, [EMAILID] [ VARCHAR](100) NULL, [PHONENUMBER] [VARCHAR](20) NULL, [DATUM NÁBORU] [DATUMTIME] NULL, [ID ODDĚLENÍ] [INT] NULL ) VYTVOŘIT TABULKU [DBO].[ODDĚLENÍ] ( [ODDĚLENÍ] INT IDENTITY (1, 1), [NÁZEV ODDĚLENÍ] [VARCHAR](MAX) NULL ) PŘEJÍT
Dále do obou tabulek vložte nějaká fiktivní data. Následující skript vloží data do „Zaměstnanec s ” tabulka:
[rozbalit název =”CELÝ DOTAZ “]
VLOŽTE [DBO].[ZAMĚSTNANCI] ([JMÉNO ZAMĚSTNANCE], [DATUM NAROZENÍ], [PRÁCE], [EMAIL], [TELEFONNÍ ČÍSLO], [DATUM NÁJMU], [ID ODDĚLENÍ]) HODNOTY (N'KEN J SÁNCHEZ', CAST (N'1969-01-29T00:00:00.000' AS DATETIME), N'CHIEF EXECUTIVE OFFICER', N'example@sqldat.com', N'697-555-0142', CAST(N'2009-01- 14T00:00:00.000' AS DATETIME), 1), (N'TERRI LEE DUFFY', CAST(N'1971-08-01T00:00:00.000' AS DATETIME), N'VICE PRESIDENT OF ENGINEERING', N'example @sqldat.com', N'819-555-0175', CAST(N'2008-01-31T00:00:00.000' AS DATETIME), NULL), (N'ROBERTO TAMBURELLO', CAST(N'1974-11) -12T00:00:00.000' AS DATETIME), N'ENGINEERING MANAGER', N'example@sqldat.com', N'212-555-0187', CAST(N'2007-11-11T00:00:00.000' AS DATETIME), NULL), (N'ROB WALTERS', CAST(N'1974-12-23T00:00:00.000' AS DATETIME), N' SENIOR TOOL DESIGNER', N'example@sqldat.com', N'612-555-0100', CAST (N'2007-12-05T00:00:00.000' AS DATETIME), NULL), (N'GAIL A ERICKSON ', CAST(N'1952-09-27T00:00:00.000' AS DATETIME), N'DESIGN ENGINEER', N'example@sqldat.com', N'849-555-0139', CAST(N'2008- 01-06T00:00:00.000' AS DATETIME), NULL), (N'JOSSEF H GOLDBERG', CAST(N'1959-03-11T00:00:00.000' AS DATETIME), N'DESIGN ENGINEER', N'example @sqldat.com', N'122-555-0189', CAST(N'2008-01-24T00:00:00.000' AS DATETIME), NULL), (N'DYLAN A MILLER', CAST(N'1987-) 02-24T00:00:00.000' AS DATETIME), N'RESEARCH AND DEVELOPMENT MANAGER', N'example@sqldat.com', N'181-555-0156', CAST(N'2009-02-08T00:00:00.000' AS DATETIME), 3), (N'DIANE L MARGHEIM', CAST (N'1986-06-05T00:00:00.000' AS DATETIME), N'RESEARCH AND DEVELOPMENT ENGINEER', N'example@sqldat.com', N'815-555-0138', CAST(N'2008-12-29T00:00:00.000' AS DATETIME), 3), (N'GIGI N MATTHEW', CAST(N '1979-01-21T00:00:00.000' AS DATETIME), N'RESEARCH AND DEVELOPMENT ENGINEER', N'example@sqldat.com', N'185-555-0186', CAST(N'2009-01-16T00 :00:00.000' AS DATETIME), 3), (N'MICHAEL RAHEEM', CAST(N'1984-11-30T00:00:00.000' AS DATETIME), N'RESEARCH AND DEVELOPMENT MANAGER', N'example@sqldat .com', N'330-555-2568', CAST(N'2009-05-03T00:00:00.000' AS DATETIME), 3)
[/expand]
Chcete-li přidat data do našeho „oddělení ” spusťte následující skript:
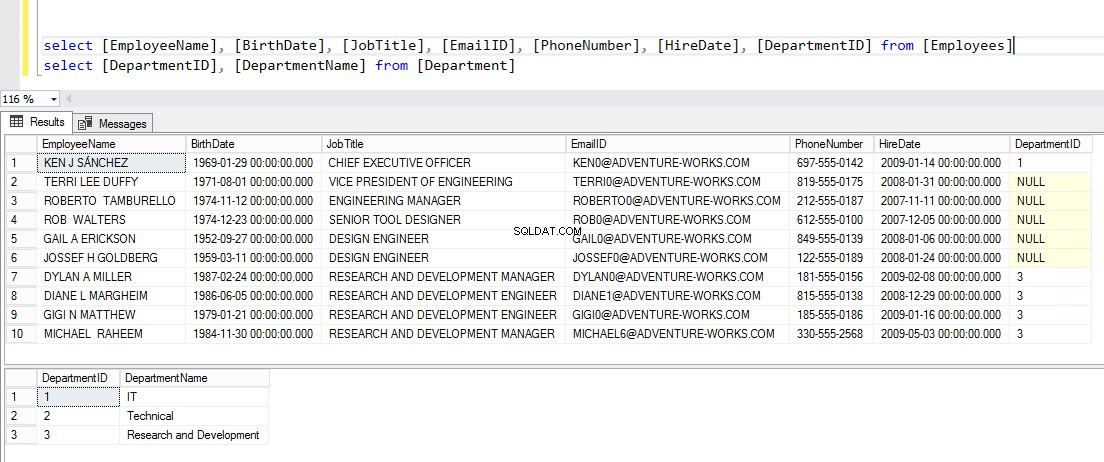
VLOŽTE [DBO].[ODDĚLENÍ] ([ID ODDĚLENÍ], [NÁZEV ODDĚLENÍ]) HODNOTY (1, N'IT'), (2, N'TECHNICKÉ'), (3, N' VÝZKUM A VÝVOJ')Nyní pro ověření dat spusťte kód, který vidíte níže:
VYBERTE [JMÉNO ZAMĚSTNANCŮ], [DATUM NAROZENÍ], [PRÁCE], [EMAILID], [TELEFONNÍ ČÍSLO], [DATUM NÁBORU], [ID ODDĚLENÍ] OD [ZAMĚSTNANCŮ] GOSELECT [ID ODDĚLENÍ], [NÁZEV ODDĚLENÍ] Z [ODDĚLENÍ] PŘEJÍTZde je požadovaný výstup:
Vytvoření a testování funkce vyhodnocené tabulkou
Jak jsem již zmínil, „POUŽÍT KRÍŽEM “ a „VNĚJŠÍ POUŽÍT ” se používají ke spojení tabulek SQL s funkcemi vyhodnocenými tabulkami. Abychom to demonstrovali, vytvořme funkci vyhodnocenou tabulkou s názvem „getEmployeeData .“ Tato funkce použije hodnotu z ID oddělení sloupec jako vstupní parametr a vrátí všechny zaměstnance z příslušného oddělení.
Chcete-li vytvořit funkci, spusťte následující skript:
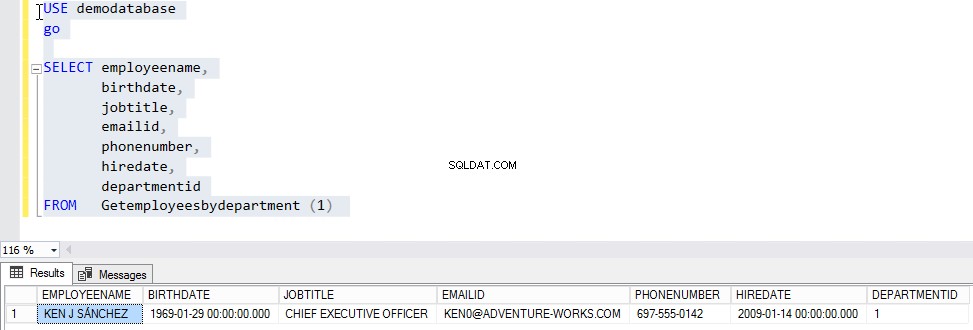
CREATE FUNCTION Getemployeesbydepartment (@DEPARTMENTID INT) VRACÍ @EMPLOYEES TABLE ( JMÉNO ZAMĚSTNANCŮ VARCHAR (MAX), DATUM NAROZENÍ, DATUM NAROZENÍ, JOBTITLE VARCHAR(150), EMAILID VARCHAR(100), TELEFONNÍ ČÍSLO 2DATUM VARCHAR(TIME PART0), 0 DATUM ODDĚLENÍ 5. DATUM )) JAKO ZAČÁTEK VLOŽTE DO @ZAMĚSTNANCI VYBERTE JMÉNO ZAMĚSTNANCE, DATUM NAROZENÍ, PRÁCI, E-MAIL, TELEFONNÍ ČÍSLO, A. NÁJEM, A. ODDĚLENÍ OD [ZAMĚSTNANCŮ] A KDE A. ID ODDĚLENÍ =@ODDĚLENÍ NÁVRAT KONECNyní, abychom funkci otestovali, předáme „1 “ jako „ID oddělení “ na „Getemployeesbyoddělení funkce “. Chcete-li to provést, spusťte níže uvedený skript:
POUŽÍVEJTE DEMODATABASEGOSELECT EMPLOYEENAME, BIRTHDATE, JOBTITLE, EMAILID, PHONE NUMBER, HIREDATE, DEPARTMENTIDFROM GETEMPLOYEESBYDEPARTMENT (1)Výstup by měl být následující:
Spojení stolu s funkcí vyhodnocenou tabulkou pomocí CROSS APPLY
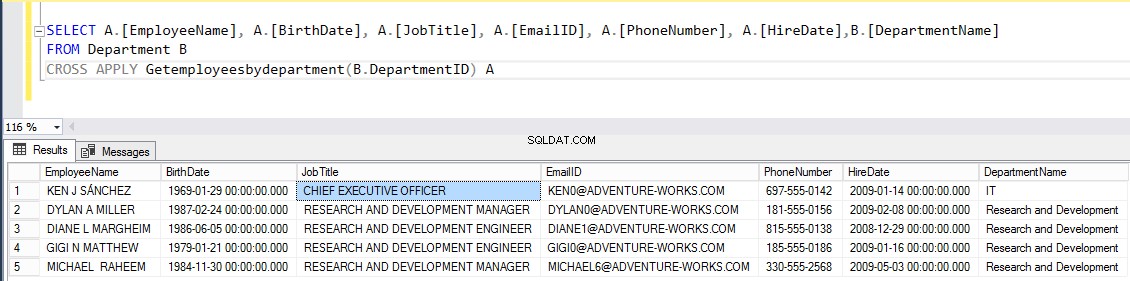
Nyní se zkusme připojit k tabulce Zaměstnanci pomocí „Getemployeesbydepartment ” funkce vyhodnocená tabulkou pomocí KŘÍŽOVÉ POUŽITÍ . Jak jsem již zmínil, POUŽÍVAT KŘÍŽEM operátor je podobný klauzuli Join. Vyplní všechny záznamy z „Zaměstnance ” tabulka, pro kterou existují odpovídající řádky ve výstupu „Getemployeesbydepartment “.
Spusťte následující skript:
VYBERTE A[JMÉNO ZAMĚSTNANCŮ], A[DATUM NAROZENÍ], A[PRÁCE], A[EMAILID], A[TELEFONNÍ ČÍSLO], A[DATUM NÁJMU], B[NÁZEV ODDĚLENÍ] Z ODDĚLENÍ B PŘIHLÁSIT SE KŘÍŽOVOU PŘIHLÁŠKOU GETEMPLOYEESBYDEPARTMENT (B.DEPARTMENTID) AVýstup by měl být následující:
Spojení tabulky s funkcí vyhodnocenou tabulkou pomocí OUTER APPLY
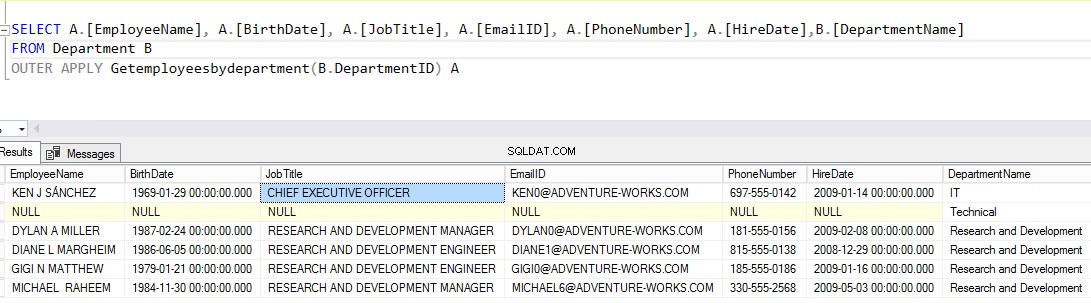
Nyní se pokusme připojit k tabulce Zaměstnanci pomocí „Getemployeesbydepartment ” funkce vyhodnocená tabulkou pomocí OUTER APPLY . Jak jsem již zmínil, VNĚJŠÍ POUŽIJETE operátor připomíná „OUTER JOIN ”klauzule. Vyplní všechny záznamy z „Zaměstnance ” a výstup z “Getemployeesbydepartment ” funkce.
Spusťte následující skript:
ZVOLTE A[JMÉNO ZAMĚSTNANCE], A[DATUM NAROZENÍ], A[PRÁCE], A[EMAIL], A[TELEFONNÍ ČÍSLO], A[DATUM NÁBORU], B[NÁZEV ODDĚLENÍ] Z ODDĚLENÍ B VNĚJŠÍ PŘIHLÁŠKU GETEMPLOYEESBYDEPARTMENT (B.DEPARTMENTID) AZde je výstup, který byste jako výsledek měli vidět:
Identifikace problémů s výkonem pomocí funkcí dynamické správy a zobrazení
Dovolte mi ukázat vám jiný příklad. Zde uvidíme, jak získat plán dotazů a odpovídající text dotazu pomocí funkcí dynamické správy a dynamických zobrazení správy.
Pro demonstrační účely jsem vytvořil tabulku s názvem „SmokeTestResults “ v „Demodatabázi“. Obsahuje výsledky aplikačního kouřového testu. Představme si, že vývojář omylem spustí dotaz SQL, aby naplnil data z „SmokeTestResults ” bez přidání filtru, což výrazně snižuje výkon databáze.
Jako správce databází musíme identifikovat dotaz náročný na zdroje. K tomu použijeme „sys.dm_exec_requests “ a „sys.dm_exec_sql_text ” funkce.
„Sys.dm_exec_requests ” je dynamické zobrazení správy, které poskytuje následující důležité podrobnosti, které můžeme použít k identifikaci dotazu náročného na zdroje:
- ID relace
- Čas CPU
- Typ čekání
- ID databáze
- Čte (fyzické)
- Píše (fyzicky)
- Logické čtení
- Popisovač SQL
- Popis plánu
- Stav dotazu
- Příkaz
- ID transakce
“sys.dm_exec_sql_text ” je dynamická funkce správy, která přijímá SQL handle jako vstupní parametr a poskytuje následující podrobnosti:
- ID databáze
- ID objektu
- Je zašifrováno
- Text dotazu SQL
Nyní spustíme následující dotaz, abychom vygenerovali určité napětí v databázi ASAP. Proveďte následující dotaz:
POUŽÍVEJTE CO ASAP GO SELECT TSID, USERID, EXECUTIONID, EX_RESULTFILE, EX_TESTDATAFILE, EX_ZIPFILE, EX_STARTTIME, EX_ENDTIME, EX_REMARKS FROM [ASAP].[DBO].[SMOKETESTRESULTS]SQL Server přidělí ID relace „66“ a spustí provádění dotazu. Viz následující obrázek:
Nyní, abychom mohli problém vyřešit, potřebujeme ID databáze, logická čtení, SQL Dotaz, Příkaz, ID relace, Typ čekání a SQL Handle . Jak jsem zmínil, můžeme získat ID databáze, logická čtení, příkaz, ID relace, typ čekání a popisovač SQL z „sys.dm_exec_requests.“ Chcete-li získat dotaz SQL , musíme použít „sys.dm_exec_sql_text. “ Jedná se o dynamickou funkci správy, takže je potřeba se připojit k „sys.dm_exec_requests “ pomocí „sys.dm_exec_sql_text ” pomocí CROSS APPLY.
V okně Nový editor dotazů spusťte následující dotaz:
VYBERTE B.TEXT, A.WAIT_TYPE, A.LAST_WAIT_TYPE, A.COMMAND, A.SESSION_ID, CPU_TIME, A.BLOCKING_SESSION_ID, A.LOGICAL_READS Z SYS.DM_EXEC_REQUESTS A CROSS APPLY SYS.DM_EXEC_SQL_TEXT(A.)SQL /před>Měl by vytvořit následující výstup:
Jak můžete vidět na výše uvedeném snímku obrazovky, dotaz vrátil všechny informace potřebné k identifikaci problému s výkonem.
Nyní kromě textu dotazu chceme získat plán provádění, který byl použit k provedení příslušného dotazu. K tomu použijeme „sys.dm_exec_query_plan“ funkce.
„sys.dm_exec_query_plan ” je funkce dynamické správy, která přijímá popisovač plánu jako vstupní parametr a poskytuje následující podrobnosti:
- ID databáze
- ID objektu
- Je zašifrováno
- Plán dotazů SQL ve formátu XML
Abychom naplnili plán provádění dotazu, musíme použít CROSS APPLY a připojit se k „sys.dm_exec_requests “ a „sys.dm_exec_query_plan. “
Otevřete okno editoru nového dotazu a proveďte následující dotaz:
VYBERTE B.TEXT, A.WAIT_TYPE, A.LAST_WAIT_TYPE, A.COMMAND, A.SESSION_ID, CPU_TIME, A.BLOCKING_SESSION_ID, A.LOGICAL_READS, C.QUERY_PLAN ZE SYS.DM_EXEC_REQUESTS A CROSS APPLY_SYS_TEXT.DM_EXE SQL_HANDLE) B CROSS APPLY SYS.DM_EXEC_QUERY_PLAN (A.PLAN_HANDLE) CVýstup by měl být následující:
Nyní, jak vidíte, je plán dotazů ve výchozím nastavení generován ve formátu XML. Chcete-li jej otevřít jako grafické znázornění, klikněte na výstup XML v plánu_dotazů sloupec, jak je znázorněno na obrázku výše. Jakmile kliknete na výstup XML, otevře se plán provádění v novém okně, jak je znázorněno na následujícím obrázku:
Získání seznamu tabulek s vysoce fragmentovanými indexy pomocí dynamických zobrazení a funkcí správy
Podívejme se na další příklad. Chci získat seznam tabulek s indexy, které mají 50% nebo větší fragmentaci v dané databázi. K načtení těchto tabulek budeme muset použít „sys.dm_db_index_physical_stats “ a „sys.tables ” funkce.
„Sys.tables ” je dynamické zobrazení správy, které vyplní seznam tabulek v konkrétní databázi.
„sys.dm_db_index_physical_stats ” je funkce dynamické správy, která přijímá následující vstupní parametry:
- ID databáze
- ID objektu
- ID indexu
- Číslo oddílu
- Režim
Vrací podrobné informace o fyzickém stavu zadaného indexu.
Nyní, abychom naplnili seznam fragmentovaných indexů, musíme se připojit k „sys.dm_db_index_physical_stats “ a „sys.tables ” pomocí CROSS APPLY. Spusťte následující dotaz:
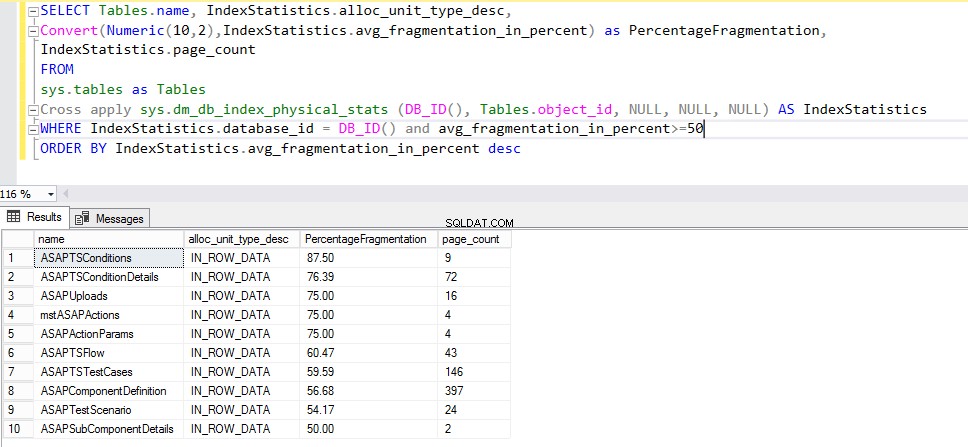
SELECT TABLES.NAME, INDEXSTATISTICS.ALLOC_UNIT_TYPE_DESC, CONVERT(NUMERIC(10, 2), INDEXSTATISTICS.AVG_FRAGMENTATION_IN_PERCENT) JAKO PERCENTAGEFRAGMENTATION, TJDB , NULL, NULL, NULL) JAKO INDEXSTATISTICS WHERE INDEXSTATISTICS.DATABASE_ID =DB_ID() A AVG_FRAGMENTATION_IN_PERCENT>=50 ORDER BY INDEXSTATISTICS.AVG_FRAGMENTATION_IN_PERCENT DESCDotaz by měl vytvořit následující výstup:
Shrnutí
V tomto článku jsme se zabývali operátorem POUŽÍT, jeho variacemi – POUŽÍT KŘÍŽEM a VNĚJŠÍ POUŽITÍ a jak fungujete. Také jsme viděli, jak je můžete použít k identifikaci problémů s výkonem SQL pomocí dynamických pohledů správy a funkcí dynamické správy.