Máte problém s SQL UNION? Stává se to, pokud výsledky, které jste zkombinovali, uvedou váš SQL Server do klidu. Nebo sestava, která dříve fungovala, zobrazí pole s červenou ikonou X. Dojde k chybě „srážka typu operandu“, která ukazuje na řádek s UNION. Začíná „oheň“. Zní vám to povědomě?
Ať už SQL UNION nějakou dobu používáte nebo s ním teprve začínáte, cheat sheet nebo stručná sada poznámek neuškodí. To je to, co dnes získáte v tomto příspěvku. Tento seznam nabízí 10 užitečných tipů pro nováčky i veterány. Také zde budou příklady a některé pokročilé diskuse.

[sendpulse-form id=”11900″]
Než se ale dostaneme k prvnímu bodu, ujasněme si pojmy.
UNION je jeden z operátorů množin v SQL, který kombinuje 2 nebo více sad výsledků. Může se hodit, když potřebujete kombinovat jména, měsíční statistiky a další z různých zdrojů. A ať už používáte SQL Server, MySQL nebo Oracle, účel, chování a syntaxe budou velmi podobné. Ale jak to funguje?
1. Ke kombinaci Unikátní použijte SQL UNION Záznamy
Použití UNION ke spojení sad výsledků odstraní duplikáty.
Proč je to důležité?
Většinu času nechcete výsledky s duplikáty. Zpráva s duplicitními řádky plýtvá inkoustem a papírem v tištěných kopiích. A to vaše uživatele rozzlobí.
Jak jej používat
Kombinujete výsledky příkazů SELECT s UNION mezi nimi.
Než začneme s příkladem, připravme si ukázková data.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
Až do třetího tipu použijeme data vygenerovaná výše uvedeným kódem. Nyní, když jsme připraveni, níže je příklad:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Máme 3 kopie jmen stejných zákazníků a očekáváme, že jedinečné záznamy zmizí. Podívejte se na výsledky:
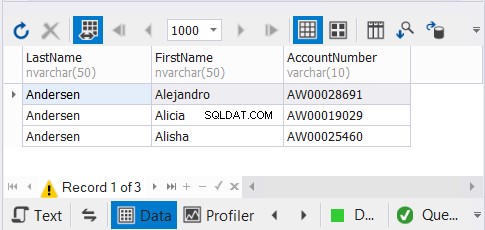
Řešení dbForge Studio pro SQL Server, které používáme pro naše příklady, zobrazuje pouze 3 záznamy. Mohlo to být 9. Použitím UNION jsme odstranili duplikáty.
Jak to funguje?
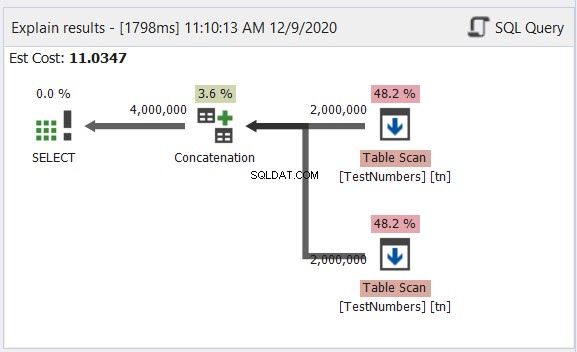
Diagram plánu v dbForge Studio odhaluje, jak SQL Server vytváří výsledek znázorněný na obrázku 1. Podívejte se:
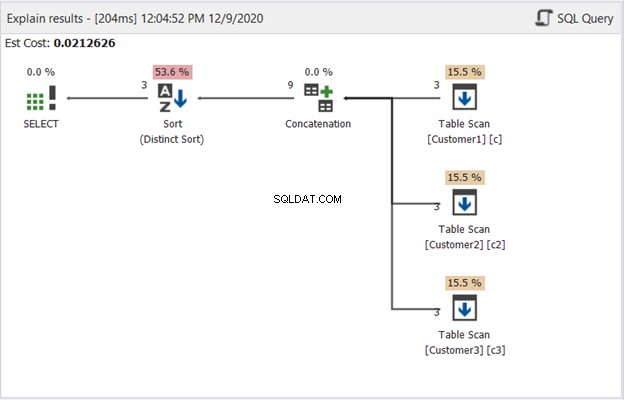
Chcete-li interpretovat obrázek 2, začněte zprava doleva:
- Od každého operátora prohledávání tabulky jsme získali 3 záznamy. To jsou 3 příkazy SELECT z příkladu výše. Každý řádek, který z něj vychází, ukazuje „3“, což znamená, že každý má 3 záznamy.
- Operátor Concatenation provádí kombinování výsledků. Řádek, který z něj vychází, ukazuje „9“ – výstup 9 záznamů z kombinace výsledků.
- Operátor Distinct Sort zajišťuje, že konečným výstupem budou jedinečné záznamy. Řádek vycházející z něj ukazuje „3“, což odpovídá počtu záznamů na obrázku 1.
Výše uvedený diagram ukazuje, jak je UNION zpracováván SQL Serverem. Počet a typ použitých operátorů se může lišit v závislosti na dotazu a základním zdroji dat. Ale shrnuto, UNION funguje následovně:
- Načtěte výsledky každého příkazu SELECT.
- Zkombinujte výsledky pomocí operátoru Concatenation.
- Pokud kombinované výsledky nejsou jedinečné, SQL Server duplikáty odfiltruje.
Všechny úspěšné příklady s UNION se řídí těmito základními kroky.
2. Ke kombinaci záznamů s duplikáty použijte SQL UNION ALL
Použití UNION ALL zkombinuje sady výsledků se zahrnutými duplikáty.
Proč je to důležité?
Možná budete chtít zkombinovat sady výsledků a poté získat záznamy s duplikáty pro pozdější zpracování. Tato úloha je užitečná pro vyčištění dat.
Jak jej používat
Kombinujete výsledky příkazů SELECT s UNION ALL mezi nimi. Podívejte se na příklad:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Výše uvedený kód vygeneruje 9 záznamů, jak je znázorněno na obrázku 3:
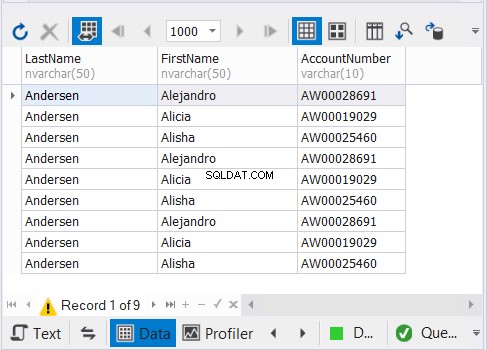
Jak to funguje?
Stejně jako dříve používáme plán plánu, abychom věděli, jak to funguje:
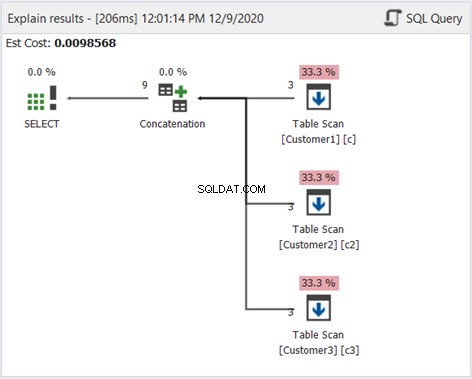
S výjimkou rozdílu řazení na obrázku 2 je výše uvedený diagram stejný. To se hodí, protože nechceme filtrovat duplikáty.
Výše uvedený diagram ukazuje, jak UNION ALL funguje. Stručně řečeno, toto jsou kroky, které bude SQL Server následovat:
- Načtěte výsledky každého příkazu SELECT.
- Poté zkombinujte výsledky s operátorem Concatenation.
Úspěšné příklady s UNION ALL se řídí tímto vzorem.
3. Můžete kombinovat SQL UNION a UNION VŠECHNY, ale seskupit je do závorek
Použití UNION a UNION ALL můžete kombinovat alespoň ve třech příkazech SELECT.
Jak jej používat?
Kombinujete výsledky příkazů SELECT s UNION nebo UNION ALL mezi nimi. Závorky seskupují výsledky, které se spojují. Použijme stejná data pro další příklad:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
Výše uvedený příklad kombinuje výsledky posledních dvou příkazů SELECT bez duplikátů. Potom to zkombinuje s výsledkem prvního příkazu SELECT. Výsledek je na obrázku 5 níže:
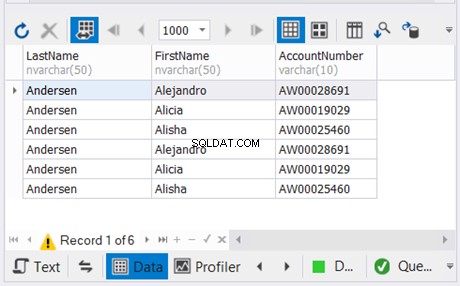
4. Sloupce každého příkazu SELECT by měly mít kompatibilní datové typy
Sloupce v každém příkazu SELECT, který používá UNION, mohou mít různé datové typy. Je to přijatelné, pokud jsou kompatibilní a umožňují nad nimi implicitní konverzi. Konečný datový typ kombinovaných výsledků použije datový typ s nejvyšší prioritou. Také základem konečné velikosti dat jsou data s největší velikostí. V případě řetězců použije data s největším počtem znaků.
Proč je to důležité?
Pokud potřebujete vložit výsledek UNIONů do tabulky, konečný datový typ a velikost určí, zda se vejde do sloupce cílové tabulky nebo ne. Pokud ne, dojde k chybě. Například jeden ze sloupců v UNION má konečný typ NVARCHAR(50). Pokud je sloupec cílové tabulky VARCHAR(50), nemůžete jej vložit do tabulky.
Jak to funguje?
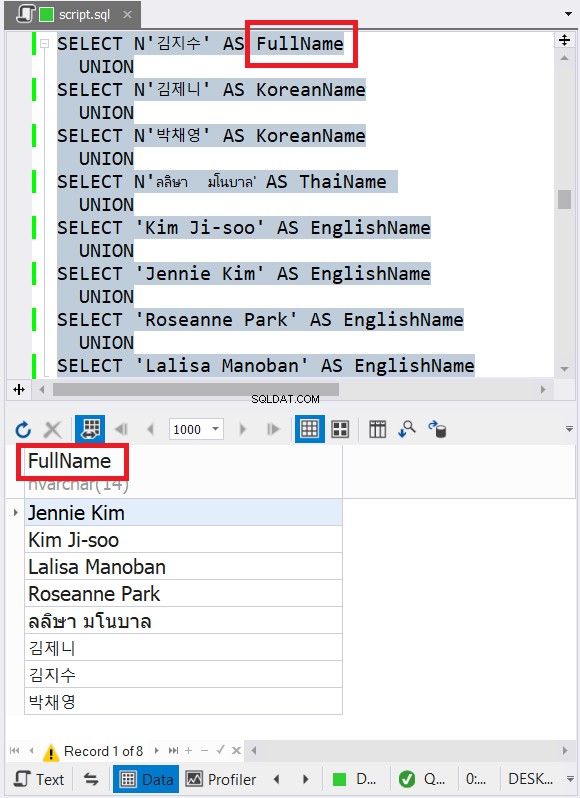
Není lepší způsob, jak to vysvětlit, než příklad:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
Výše uvedený příklad obsahuje data s anglickými, korejskými a thajskými názvy znaků. Thajština a korejština jsou znaky Unicode. Anglické znaky nejsou. Jaký tedy bude podle vás konečný datový typ a velikost? dbForge Studio jej zobrazí ve výsledné sadě:
Všimli jste si konečného datového typu na obrázku 6? Nemůže to být VARCHAR kvůli znakům Unicode. Takže to musí být NVARCHAR. Mezitím velikost nemůže být menší než 14, protože data s největším počtem znaků mají 14 znaků. Viz červené titulky na obrázku 6. Je dobré zahrnout typ a velikost dat do záhlaví sloupce v dbForge Studio.
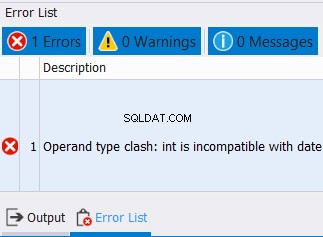
To platí nejen pro datové typy řetězců. Platí to i pro čísla a data. Pokud se mezitím pokusíte zkombinovat data s nekompatibilními datovými typy, dojde k chybě. Viz příklad níže:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
Nemůžeme kombinovat data a celá čísla do jednoho sloupce. Očekávejte tedy chybu podobnou té níže:
5. Názvy sloupců kombinovaných výsledků budou používat názvy sloupců prvního příkazu SELECT
Tento problém souvisí s předchozím tipem. Všimněte si názvů sloupců v kódu v tipu #4. V každém příkazu SELECT jsou různé názvy sloupců. Konečný název sloupce jsme však viděli v kombinovaném výsledku na obrázku 6 dříve. Základem je tedy název sloupce prvního příkazu SELECT.
Proč je to důležité?
To může být užitečné, když potřebujete uložit výsledek UNION do dočasné tabulky. Pokud potřebujete odkazovat na názvy sloupců v následujících příkazech, musíte si být jisti názvy. Pokud nepoužíváte pokročilý editor kódu s IntelliSense, máte v kódu T-SQL další chybu.
Jak to funguje?
Přehlednější výsledky používání dbForge Studio naleznete na obrázku 8:
6. Přidejte ORDER BY do posledního příkazu SELECT s SQL UNION k řazení výsledků
Musíte seřadit kombinované výsledky. V řadě příkazů SELECT s UNION mezi nimi to můžete provést pomocí klauzule ORDER BY v posledním příkazu SELECT.
Proč je to důležité?
Uživatelé chtějí v aplikacích, na webových stránkách, v sestavách, tabulkách a dalších položkách třídit data tak, jak jim to vyhovuje.
Jak jej používat
Použijte ORDER BY v posledním příkazu SELECT. Zde je příklad:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
Ve výše uvedené ukázce to vypadá, že k řazení dochází pouze v posledním příkazu SELECT. ale není. Bude to fungovat pro kombinovaný výsledek. Pokud jej umístíte do každého příkazu SELECT, budete mít potíže. Podívejte se na výsledek:
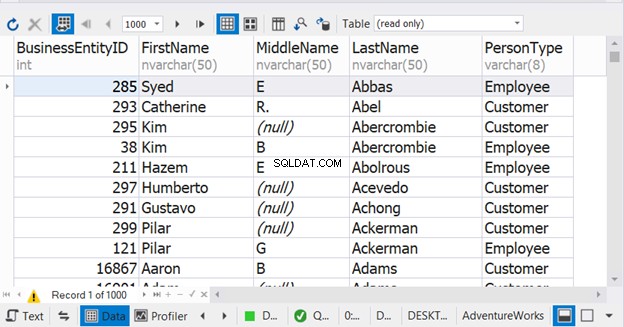
Bez ORDER BY bude mít sada výsledků všechny PersonType zaměstnance nejprve následují všechny PersonType zákazníka . Obrázek 9 však ukazuje, že názvy se stávají pořadím řazení kombinovaného výsledku.
Pokud se pokusíte umístit ORDER BY do každého příkazu SELECT, který chcete seřadit, stane se toto:
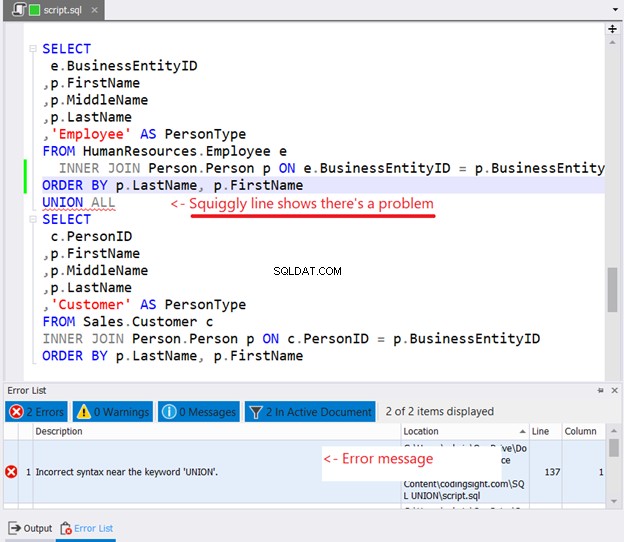
Viděli jste klikatou čáru na obrázku 10? je to varování. Pokud jste si toho nevšimli a pokračovali, v okně Error List programu dbForge Studio se objeví chyba.
7. Klauzule WHERE a GROUP BY lze použít v každém příkazu SELECT s SQL UNION
Klauzule ORDER BY nefunguje v každém příkazu SELECT s UNION mezi nimi. Klauzule WHERE a GROUP BY však fungují.
Proč je to důležité?
Možná budete chtít zkombinovat výsledky různých dotazů, které filtrují, počítají nebo sumarizují data. Můžete to například udělat, chcete-li získat celkové prodejní objednávky za leden 2012 a porovnat je s lednem 2013, lednem 2014 a tak dále.
Jak jej používat
Umístěte klauzule WHERE a/nebo GROUP BY do každého příkazu SELECT. Podívejte se na příklad níže:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Výše uvedený kód kombinuje počet lednových objednávek za tři po sobě jdoucí roky. Nyní zkontrolujte výstup:
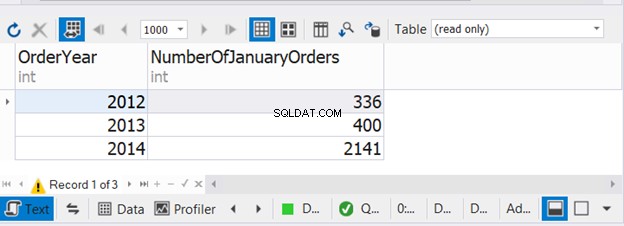
Tento příklad ukazuje, že je možné použít WHERE a GROUP BY v každém ze tří příkazů SELECT s UNION.
8. SELECT INTO Funguje s SQL UNION
Když potřebujete vložit výsledky dotazu pomocí SQL UNION do tabulky, můžete tak učinit pomocí SELECT INTO.
Proč je to důležité?
Nastanou situace, kdy budete muset vložit výsledky dotazu pomocí UNION do tabulky pro další zpracování.
Jak jej používat
Umístěte klauzuli INTO do prvního příkazu SELECT. Zde je příklad:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Nezapomeňte do prvního příkazu SELECT umístit pouze jednu klauzuli INTO.
Jak to funguje
SQL Server se řídí vzorem zpracování UNION. Potom vloží výsledek do tabulky uvedené v klauzuli INTO.
9. Odlišení SQL UNION od SQL JOIN
SQL UNION i SQL JOIN kombinují data tabulky, ale rozdíl v syntaxi a výsledcích je jako noc a den.
Proč je to důležité?
Pokud vaše zpráva nebo jakýkoli požadavek vyžaduje JOIN, ale vy jste provedli UNION, výstup bude chybný.
Jak se používají SQL UNION a SQL JOIN
Je to SQL UNION vs. JOIN. Toto je jeden ze souvisejících vyhledávacích dotazů a otázek, které nováček dělá na Googlu, když se učí o SQL UNION. Zde je tabulka rozdílů:
| SQL UNION | SQL JOIN | |
| Co je kombinováno | Řádky | Sloupce (pomocí klíče) |
| Počet sloupců v tabulce | Stejné pro všechny tabulky | Proměnná (nula na všechny sloupce/tabulku) |
Ve všech projektech, na kterých jsem byl, se většinou používá SQL JOIN. Měl jsem jen několik případů, které používaly SQL UNION. Ale jak jste doposud viděli, SQL UNION není ani zdaleka k ničemu.
10. SQL UNION ALL je rychlejší než UNION
Schémata plánu na obrázku 2 a obrázku 4 dříve naznačují, že UNION vyžaduje dalšího operátora, aby zajistil jedinečné výsledky. Proto je UNION ALL rychlejší.
Proč je to důležité?
Vy, vaši uživatelé, vaši zákazníci, váš šéf, všichni chcete rychlé výsledky. Vědomí, že UNION ALL je rychlejší než UNION, vás nutí přemýšlet, co dělat, pokud potřebujete jedinečné kombinované výsledky. Existuje jedno řešení, jak uvidíte později.
SQL UNION ALL vs. výkon UNION
Obrázek 2 a obrázek 4 vám již poskytly představu o tom, co je rychlejší. Ale použité ukázky kódu jsou jednoduché s malou sadou výsledků. Pojďme přidat několik dalších srovnání pomocí milionů záznamů, aby to bylo přesvědčivé.
Pro začátek si připravíme data:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
To jsou 2 miliony záznamů. Doufám, že je to dostatečně přesvědčivé. Nyní si dáme další dva příklady dotazů níže.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Pojďme se podívat na procesy zahrnuté v těchto dotazech, počínaje tím rychlejším.
Analýza plánového diagramu
Diagram na obrázku 12 vypadá jako typický pro proces UNION ALL. Výsledkem jsou však 4 miliony kombinovaných výsledků. Podívejte se na šipku vycházející z operátoru Concatenation. Přesto je to obvykle proto, že se nezabývá duplikáty.
Nyní mějme schéma dotazu UNION na obrázku 13:
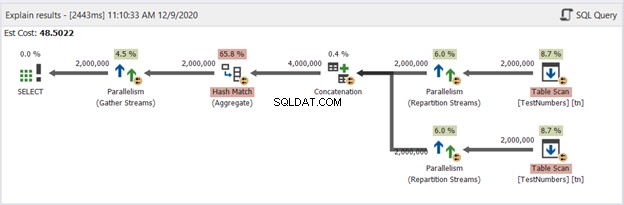
Tenhle už není typický. Plán se stává plánem paralelních dotazů, který se zabývá odstraněním duplikátů ve čtyřech milionech řádků. Plán paralelních dotazů znamená, že SQL Server potřebuje rozdělit proces počtem procesorových jader, která má k dispozici.
Pojďme si to vyložit, začněme od pravých operátorů doleva:
- Protože kombinujeme tabulku pro sebe, SQL Server ji potřebuje načíst dvakrát. Podívejte se na dva prohledávání tabulek, každý se dvěma miliony záznamů.
- Operátoři streamu rozdělení budou řídit distribuci každého řádku do dalšího dostupného vlákna.
- Zřetězení zdvojnásobí výsledek na čtyři miliony. To je stále s ohledem na počet procesorových jader.
- K odstranění duplikátů se použije hash Match. Jedná se o drahý proces s 65,8% náklady na operátora. V důsledku toho byly vyřazeny dva miliony záznamů.
- Shromažďování datových proudů spojuje výsledky dosažené v každém jádru procesoru nebo vláknu do jednoho.
To je příliš mnoho práce, i když je proces rozdělen do více vláken. Proto dojdete k závěru, že poběží pomaleji. Ale co když existuje řešení, jak získat jedinečné záznamy pomocí UNION ALL, ale rychleji než toto?
Jedinečné výsledky, ale rychlejší oprava s UNION ALL – Jak?
Nenechám tě čekat. Zde je kód:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
To může být chabé řešení. Ale podívejte se na jeho plánový diagram na obrázku 14:
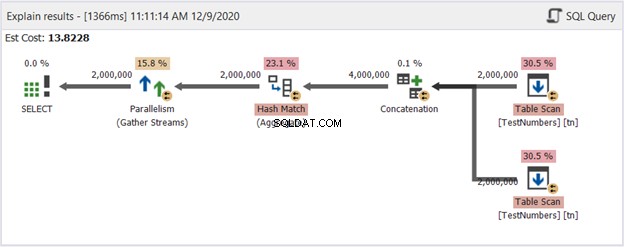
Takže, co to zlepšilo? Pokud to porovnáte s obrázkem 13, uvidíte, že operátoři Repartition Stream zmizeli. Stále však využívá více vláken k provedení práce. Na druhou stranu to znamená, že optimalizátor dotazů považuje tento proces za jednodušší než dotaz pomocí UNION.
Můžeme bezpečně dojít k závěru, že bychom se měli vyhnout používání UNION a místo toho použít tento přístup? Vůbec ne! Vždy zkontrolujte schéma prováděcího plánu! Vždy záleží na tom, co chcete, aby vám SQL Server dal. Tento pouze ukazuje, že pokud narazíte na výkonnostní zeď, musíte změnit svůj přístup k dotazům.
Jak je to se statistikou I/O?
Nemůžeme odmítnout, kolik zdrojů SQL Server potřebuje ke zpracování našich příkladů dotazů. Proto také musíme prozkoumat jejich STATISTICS IO. Porovnáním tří výše uvedených dotazů získáme logická čtení níže:
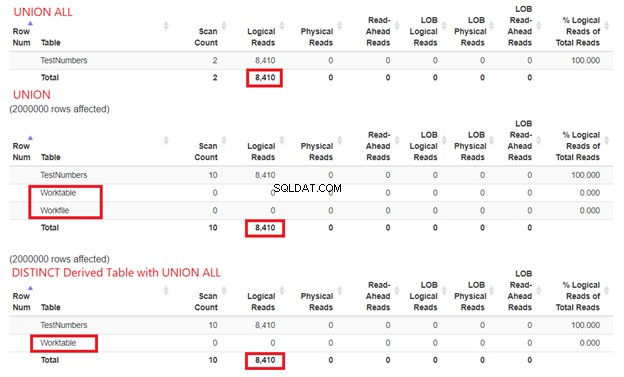
Z obrázku 15 můžeme stále usuzovat, že UNION ALL je rychlejší než UNION, ačkoli logická čtení jsou stejná. Přítomnost Worktable a Pracovní soubor zobrazuje pomocí tempdb dokončit práci. Mezitím, když použijeme SELECT DISTINCT z odvozené tabulky s UNION ALL, tempdb využití je menší ve srovnání s UNION. To dále potvrzuje, že naše analýza z výše uvedených plánových diagramů je správná.
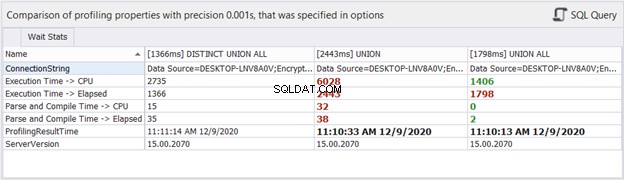
A co časové statistiky?
I když se uplynulý čas může změnit při každém provádění, které provádíme na stejné dotazy, může nám to poskytnout určitou představu a přidat další důkazy do naší analýzy. dbForge Studio zobrazuje časové rozdíly tří výše uvedených dotazů. Toto srovnání je v souladu s předchozí analýzou, kterou jsme provedli.
Závěr
Pokryli jsme spoustu pozadí, abychom vám poskytli to, co potřebujete k použití SQL UNION a UNION ALL. Po přečtení tohoto příspěvku si možná nebudete vše pamatovat, takže si tuto stránku nezapomeňte uložit do záložek.
Pokud se vám příspěvek líbí, neváhejte ho sdílet na sociálních sítích.