V dřívějším kurzu „Slučování datových souborů s programem Statistica, část 1“ jsme představili používání programu Statistica pro slučování tabulek. Probrali jsme režim sloučení zřetězení. V tomto tutoriálu probereme dva další režimy:používání názvů případu a názvů proměnných. Tento výukový program má následující sekce:
- Použití názvů případů ke sloučení datových souborů
- Použití názvů proměnných ke sloučení datových souborů
- Závěr
Použití názvů případů ke sloučení datových souborů
Dále sloučíme datové soubory (tabulky) porovnáním řádků (také nazývané případy ). Pokud mají řádky stejné názvy velkých a malých písmen, data v řádcích ze dvou datových souborů se sloučí. Vzorové datové soubory, které jsme použili v předchozím článku, neobsahují název případu. Název případu je uveden ve sloupci 1, sloupci před sloupci dat. Pomocí stejných dat jako pro zřetězení datových souborů přidejte názvy případů (log1 na log6 ) na řádky v wlslog1.sta tabulkový procesor, jak je znázorněno na obrázku 1.
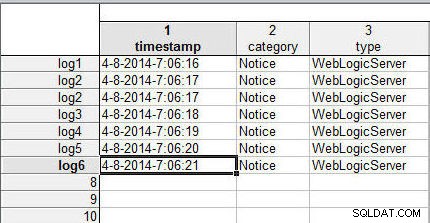
Obrázek 1: Tabulka wlslog1
Podobně přidejte názvy případů (log1 na log6 ) do každého řádku v wlslog2.sta , jak je znázorněno na obrázku 2.
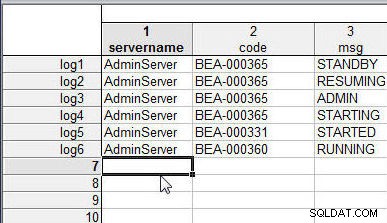
Obrázek 2: Tabulka wlslog2
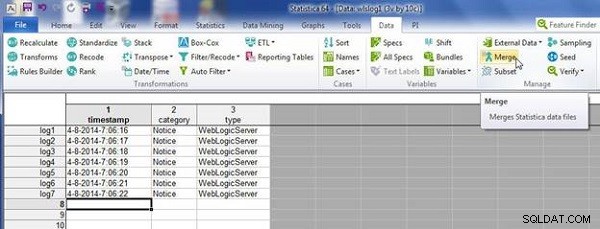
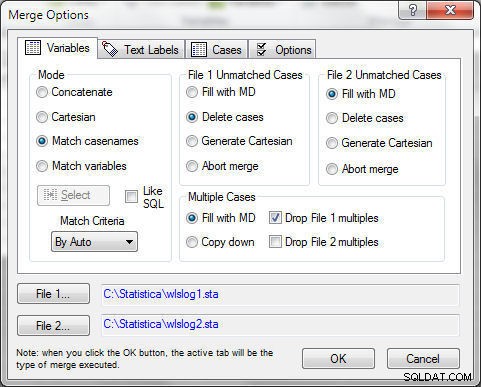
Vyberte možnost Data>Sloučit a v Možnosti sloučení , vyberte Režim as Match casenames , jak je znázorněno na obrázku 3. Klikněte na OK .
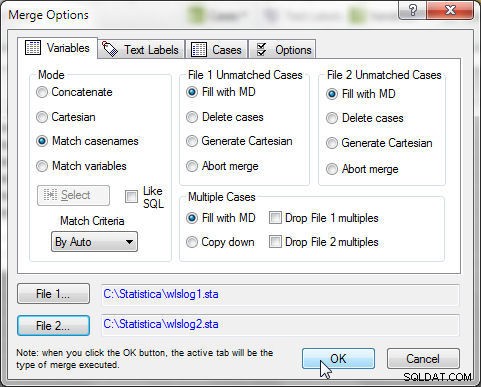
Obrázek 3: Sloučení wlslog1 a wlslog2
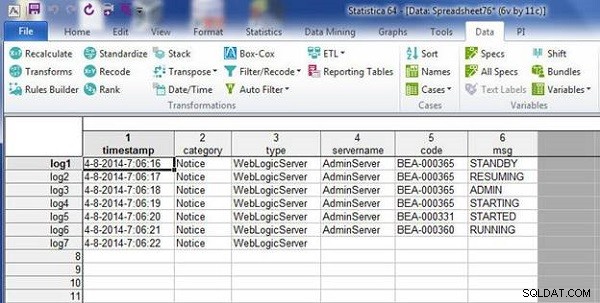
Data v wlslog1.sta tabulka se sloučí s daty v wlslog2.sta tabulka, jak je znázorněno ve výsledné tabulce na obrázku 4.
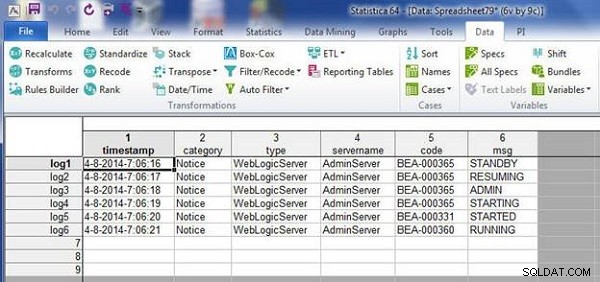
Obrázek 4: Sloučený soubor
Při slučování podle názvů případů musí každý datový soubor ke sloučení obsahovat názvy případů, jinak se zobrazí chyba znázorněná na obrázku 5.
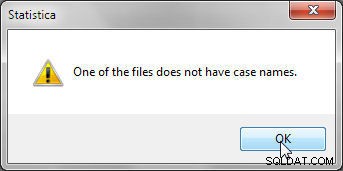
Obrázek 5: Názvy případů jsou vyžadovány při slučování odpovídajícími názvy případů
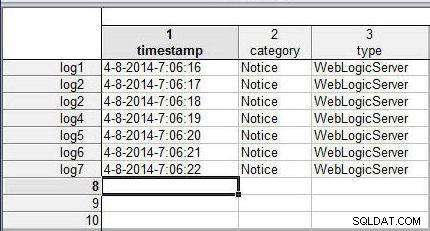
Jedna tabulka může mít více případů (nebo řádků) než druhá. Jako příklad přidejte do wlslog1.sta řádek 7 (viz obrázek 6). Klikněte na Sloučit ke sloučení tabulek.
Obrázek 6: Sloučit se 7. řadou v wlslog1.sta
Sloučit tak, že porovnáte názvy případů s wlslog2.sta , což je stejné jako dříve se 6 případy (řádky), jak je znázorněno na obrázku 28. Tabulky ke sloučení mají neshodné případy (jedna tabulka má více případů než druhá). Nespárované případy jsou ve výchozím nastavení sloučeny vyplněním chybějících dat, což znamená, že hodnoty dat jsou prázdné. Výsledná tabulka obsahuje prázdná chybějící data pro neshodné případy, jak ukazuje obrázek 7.
Obrázek 7: Výsledná tabulka obsahuje prázdná chybějící data
Možnosti sloučení poskytuje některé možnosti pro Nepřiřazené případy kromě doplnění chybějících údajů. K demonstraci použijte tabulku wlslog1.sta , s řádkem navíc a také s duplicitním názvem případu (log2 ), jak je znázorněno na obrázku 8.
Obrázek 8: Tabulka s duplicitním názvem případu
Nepřiřazené případy lze smazat výběrem možnosti Smazat případy v Soubor 1 nepřiřazených případů , jak je znázorněno na obrázku 9. Více případů je opraveno výběrem „Drop File 1 multiples“. S režimem sloučení jako Match Casenames , klikněte na OK .
Obrázek 9: Soubor 1 Unmatched Cases>Smazat případy
Výsledná tabulka má oba problémy opravené. Nepřiřazený případ se odstraní a duplicitní případ se zahodí, jak je znázorněno na obrázku 10.
Obrázek 10: Výsledná tabulka s odstraněnými Unmatched case a Duplicate case zrušen
Použití názvů proměnných ke sloučení datových souborů
Dále sloučíme tabulky seřazením názvů proměnných. Začněte se dvěma tabulkami, wlslog1.sta a wlslog2.sta , každý s názvy sloupců zobrazenými na obrázku 11.
Obrázek 11: Sloupce Názvy ve wlslog1 a wlslog2
Přidejte následující data do wlslog1.sta .
4-8-2014-7:06:16,Notice,WebLogicServer,AdminServer,BEA-000365, STANDBY 4-8-2014-7:06:17,Notice,WebLogicServer,AdminServer,BEA-000365, RESUMING 4-8-2014-7:06:18,Notice,WebLogicServer,AdminServer,BEA-000365, ADMIN
Soubor wlslog1.sta tabulka je znázorněna na obrázku 12.
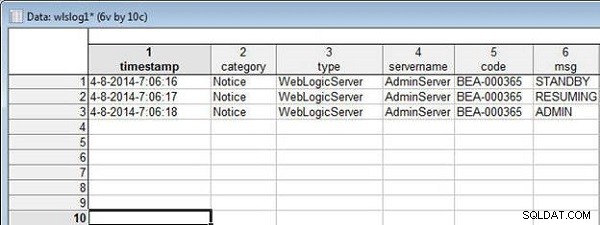
Obrázek 12: Tabulka wlslog1.sta
Přidejte následující data do wlslog2.sta .
4-8-2014-7:06:20,Notice,WebLogicServer,AdminServer,BEA-000331, STARTING 4-8-2014-7:06:21,Notice,WebLogicServer,AdminServer,BEA-000365, STARTED 4-8-2014-7:06:22,Notice,WebLogicServer,AdminServer,BEA-000360, RUNNING
Soubor wlslog2.sta je znázorněno na obrázku 13. Vyberte Data>Sloučit jako předtím.
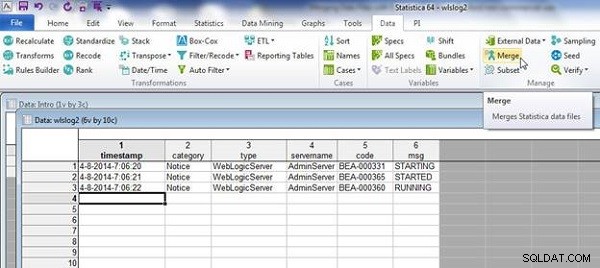
Obrázek 13: Tabulka wlslog2.sta
V Možnosti sloučení , vyberte Režim jako Shoda proměnných , jak je znázorněno na obrázku 14. Vyberte Soubor 1 jako wlslog1.sta a Soubor 2 jako wlslog2.sta . Pořadí je důležité, protože tabulka, která se má přidat na konec druhé, musí být Soubor 2 . Udržujte Kritéria shody jako Automaticky , který automaticky vybere nejvhodnější kritéria sloučení. Další možnosti pro kritéria shody jsou Podle textu , který porovnává data porovnáním textu; a Podle čísel , který porovnává data porovnáním číselných hodnot. Dále klikněte na Vybrat vyberte proměnné, které se mají shodovat.
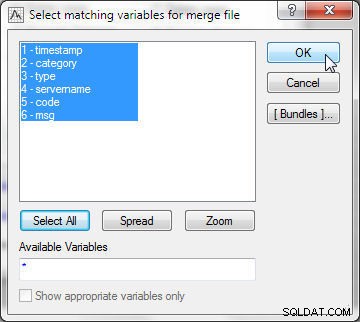
Obrázek 14: Režim sloučení jako shoda proměnných
Nejprve vyberte odpovídající proměnné pro aktuální soubor (Soubor 1). Klikněte na Vybrat vše a klepněte na OK, jak je znázorněno na obrázku 15.
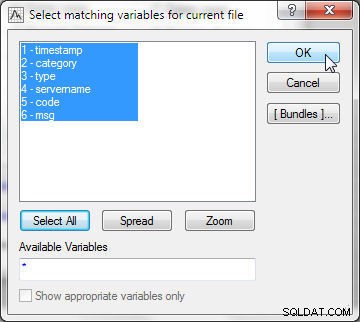
Obrázek 15: Výběr proměnných v aktuálním souboru
Podobně vyberte všechny proměnné pro slučovací soubor (Soubor 2) a klikněte na OK (viz obrázek 16).
Obrázek 16: Výběr proměnných v Merge File
Klikněte na OK v Merge Options, jak ukazuje obrázek 17.
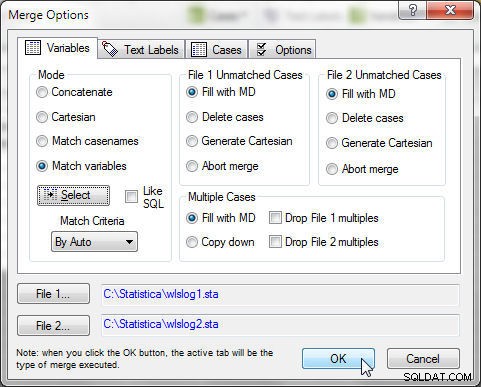
Obrázek 17: Sloučení s režimem jako shoda proměnných
Tyto dvě tabulky se sloučí odpovídajícími názvy proměnných, jak je znázorněno na obrázku 18.
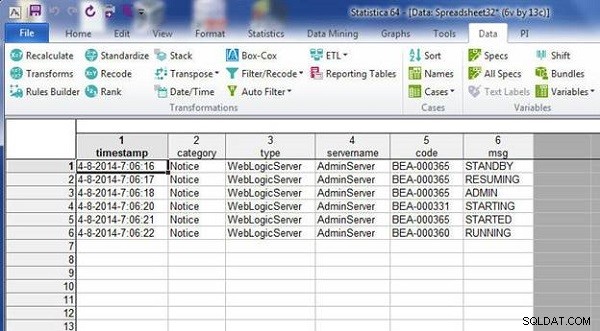
Obrázek 18: Výsledná tabulka ze sloučení podle názvů proměnných
Při slučování tabulek podle názvů proměnných jsou datové hodnoty seřazeny číselně a textově. Jako příklad sloučte dvě tabulky s 1 tabulkou, jak je znázorněno na obrázku 19.
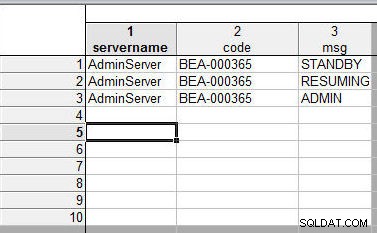
Obrázek 19: První tabulka ke sloučení
2. tabulka je znázorněna na obrázku 20. Přidaná úprava spočívá v tom, že název proměnné byl v souboru 1 mírně upraven:„ServerType“ místo „servername“, „MessageCode“ místo „code“ a „Message“ namísto „ zpráva“.
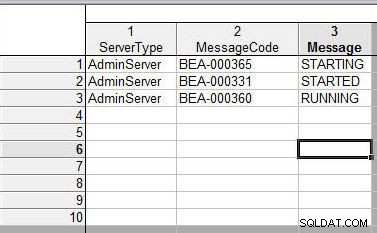
Obrázek 20: Druhá tabulka ke sloučení
Kliknutím na Vybrat vyberte proměnné, které se mají použít pro párování. V souboru 1 vyberte všechny proměnné (viz obrázek 21).
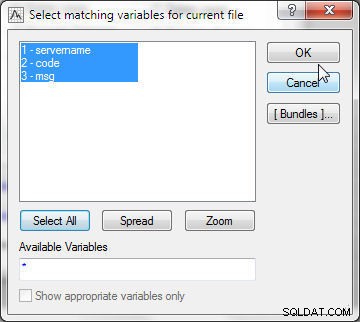
Obrázek 21: Výběr odpovídajících proměnných pro aktuální soubor
V souboru 2 také vyberte všechny proměnné, jak je znázorněno na obrázku 22.
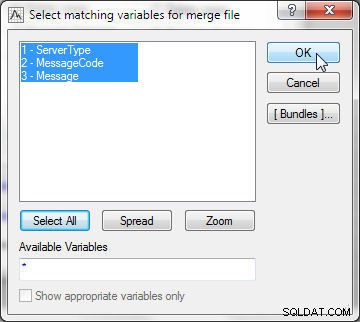
Obrázek 22: Výběr odpovídajících proměnných pro soubor sloučení
Sloučit dvě tabulky jako předtím. Název „servername“ nebo „ServerType“ je pro všechny řádky stejný a nepřispívá k řazení dat ve výsledné tabulce. Datové hodnoty ve sloupcích „code“ nebo „MessageCode“ jsou seřazeny podle typu Text nerozlišují malá a velká písmena; BEA-000331 je tříděn před BEA-000360, který je tříděn před BEA-000365. Pro stejnou hodnotu pro kód BEA-000365 jsou data ve sloupcích „msg“ nebo „Message“ seřazena také podle textu – ADMIN->RESUMING->STANDBY>STARTING – jak je znázorněno na obrázku 23.
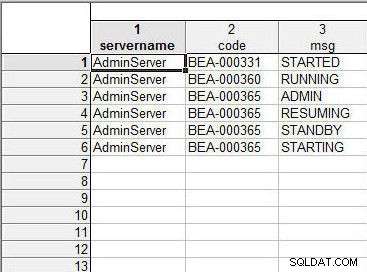
Obrázek 23: Výsledná tabulka
Při výběru proměnných musí být splněny určité podmínky. Pro párování musí být vybrána alespoň jedna proměnná, jinak se vygeneruje chyba zobrazená na obrázku 24.
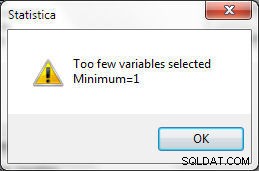
Obrázek 24: Musí být vybrána minimálně 1 proměnná
Počet vybraných proměnných musí být stejný v souboru 1 a souboru 2, jinak se vygeneruje chyba zobrazená na obrázku 25.
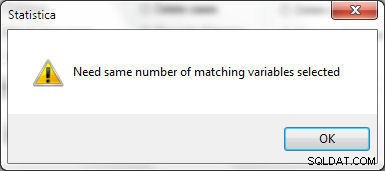
Obrázek 25: V Tabulkách ke sloučení
Datový typ vybraných proměnných musí být pro vybrané proměnné stejný. Například proměnné „servername“ a „ServerType“ v souboru 1 a souboru 2 musí mít stejný datový typ, jinak se vygeneruje chyba zobrazená na obrázku 26.
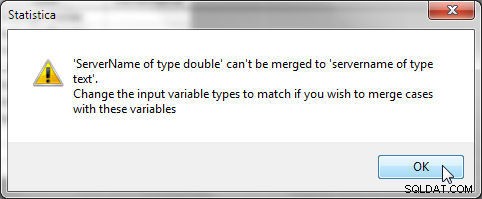
Obrázek 26: Typy proměnných musí být stejné při slučování pomocí porovnávání proměnných
Závěr
V tomto tutoriálu jsme diskutovali o slučování datových souborů (také nazývaných tabulky) v platformě Statistica pomocí režimů:Match casenames a Match variables.