Úvod
T-SQL nám umožňuje kombinovat záznamy z více než jedné tabulky a vrátit je jako jednu sadu výsledků. Toho je dosaženo prostřednictvím konceptu spojení v SQL Server.
Tato příležitost je často nezbytná, protože data v relačních databázích jsou obvykle normalizována. Máme například údaje o zaměstnancích rozložené ve dvou nebo více tabulkách. První tabulka bude obsahovat základní údaje o zákaznících a bude se jmenovat zaměstnanec. Druhá tabulka by byla oddělení .
Konzistence dat vyžaduje správný vztah mezi zákazníkem a oddělením. Vrácení úplných dat pro sadu zaměstnanců a jejich oddělení vyžaduje spojení obou tabulek.
Operace spojení SQL mohou také zahrnovat více než dvě tabulky.
Jiný případ existence takových vztahů cizího klíče mezi tabulkami je pro souhrn a podrobnosti tabulky.
Lidé, kteří pracovali se vzorovými databázemi AdventureWorks nebo WideWorldImporters, znají Sales.Orders a tabulky Sales.OrderDetails. V tomto případě tato obsahuje podrobnosti o každé objednávce zaznamenané v Sales.Orders stůl. Dvě tabulky mají vztah na základě objednávky. Můžeme tedy získat data z obou tabulek jako jednu sadu výsledků pomocí JOINS.
Typy připojení SQL Server JOIN
T-SQL umožňuje následující typy spojení:
- Vnitřní spojení vrátí všechny záznamy společné pro všechny tabulky zahrnuté v dotazu.
- Levé (vnější) spojení vrátí všechny záznamy z vlevo tabulka a všechny záznamy z zprava tabulky, které se také vyskytují v levé tabulce. Výrazy vlevo a vpravo odkazují na pozici tabulky vzhledem ke klauzuli JOIN.
- Pravé (vnější) připojení vrátí všechny záznamy zprava tabulka a všechny záznamy z vlevo tabulky, které se také vyskytují v levé tabulce. Podmínky jsou podobné jako v předchozím případě.
- Úplné vnější spojení vrátí všechny záznamy společné pro obě tabulky plus všechny ostatní záznamy z obou tabulek. Sloupce, které nemají odpovídající řádky v druhé tabulce, vrátí hodnotu NULL
- Křížové připojení , také nazývané Kartézské spojení , vrátí kartézský součin dat z obou tabulek. Proto bude výsledná sada výsledků pro každý řádek v tabulce A obsahovat mapování všech řádků v tabulce B a naopak.
Tento článek se zaměří na SQL INNER JOINs.
Ukázkové tabulky
K demonstraci konceptu vnitřních spojení používáme tři související tabulky z databáze TSQLV4 vytvořené Itzikem Ben-Ganem.
Následující výpisy ukazují strukturu těchto tabulek.
-- Listing 1: Structure of the Sales.Customers Table
CREATE TABLE [Sales].[Customers](
[custid] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[companyname] [nvarchar](40) NOT NULL,
[contactname] [nvarchar](30) NOT NULL,
[contacttitle] [nvarchar](30) NOT NULL,
[address] [nvarchar](60) NOT NULL,
[city] [nvarchar](15) NOT NULL,
[region] [nvarchar](15) NULL,
[postalcode] [nvarchar](10) NULL,
[country] [nvarchar](15) NOT NULL,
[phone] [nvarchar](24) NOT NULL,
[fax] [nvarchar](24) NULL,
CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED
(
[custid] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GOVšimněte si vztahu cizího klíče mezi sloupcem zákazníka v Sales.Orders a sloupec zákazníka v Sales.Customers .
Pro provádění JOINů musíme určit takový společný sloupec jako základ JOIN.
K provádění dotazů JOIN striktně nevyžaduje vztah cizího klíče, ale sloupce, které určují sadu výsledků, musí být srovnatelné.
Cizí klíče mohou také pomoci zlepšit dotazy JOIN, zejména pokud je sloupec cizího klíče indexován.
-- Listing 2: Structure of the Sales.Orders Table
CREATE TABLE [Sales].[Orders](
[orderid] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[custid] [int] NULL,
[empid] [int] NOT NULL,
[orderdate] [date] NOT NULL,
[requireddate] [date] NOT NULL,
[shippeddate] [date] NULL,
[shipperid] [int] NOT NULL,
[freight] [money] NOT NULL,
[shipname] [nvarchar](40) NOT NULL,
[shipaddress] [nvarchar](60) NOT NULL,
[shipcity] [nvarchar](15) NOT NULL,
[shipregion] [nvarchar](15) NULL,
[shippostalcode] [nvarchar](10) NULL,
[shipcountry] [nvarchar](15) NOT NULL,
CONSTRAINT [PK_Orders] PRIMARY KEY CLUSTERED
(
[orderid] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [Sales].[Orders] ADD CONSTRAINT [DFT_Orders_freight] DEFAULT ((0)) FOR [freight]
GO
ALTER TABLE [Sales].[Orders] WITH CHECK ADD CONSTRAINT [FK_Orders_Customers] FOREIGN KEY([custid])
REFERENCES [Sales].[Customers] ([custid])
GO
ALTER TABLE [Sales].[Orders] CHECK CONSTRAINT [FK_Orders_Customers]
GO
ALTER TABLE [Sales].[Orders] WITH CHECK ADD CONSTRAINT [FK_Orders_Employees] FOREIGN KEY([empid])
REFERENCES [HR].[Employees] ([empid])
GO
ALTER TABLE [Sales].[Orders] CHECK CONSTRAINT [FK_Orders_Employees]
GO
ALTER TABLE [Sales].[Orders] WITH CHECK ADD CONSTRAINT [FK_Orders_Shippers] FOREIGN KEY([shipperid])
REFERENCES [Sales].[Shippers] ([shipperid])
GO
ALTER TABLE [Sales].[Orders] CHECK CONSTRAINT [FK_Orders_Shippers]
GO-- Listing 3: Structure of the Sales.OrderDetails Table
CREATE TABLE [Sales].[OrderDetails](
[orderid] [int] NOT NULL,
[productid] [int] NOT NULL,
[unitprice] [money] NOT NULL,
[qty] [smallint] NOT NULL,
[discount] [numeric](4, 3) NOT NULL,
CONSTRAINT [PK_OrderDetails] PRIMARY KEY CLUSTERED
(
[orderid] ASC,
[productid] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [Sales].[OrderDetails] ADD CONSTRAINT [DFT_OrderDetails_unitprice] DEFAULT ((0)) FOR [unitprice]
GO
ALTER TABLE [Sales].[OrderDetails] ADD CONSTRAINT [DFT_OrderDetails_qty] DEFAULT ((1)) FOR [qty]
GO
ALTER TABLE [Sales].[OrderDetails] ADD CONSTRAINT [DFT_OrderDetails_discount] DEFAULT ((0)) FOR [discount]
GO
ALTER TABLE [Sales].[OrderDetails] WITH CHECK ADD CONSTRAINT [FK_OrderDetails_Orders] FOREIGN KEY([orderid])
REFERENCES [Sales].[Orders] ([orderid])
GO
ALTER TABLE [Sales].[OrderDetails] CHECK CONSTRAINT [FK_OrderDetails_Orders]
GO
ALTER TABLE [Sales].[OrderDetails] WITH CHECK ADD CONSTRAINT [FK_OrderDetails_Products] FOREIGN KEY([productid])
REFERENCES [Production].[Products] ([productid])
GO
ALTER TABLE [Sales].[OrderDetails] CHECK CONSTRAINT [FK_OrderDetails_Products]
GO
ALTER TABLE [Sales].[OrderDetails] WITH CHECK ADD CONSTRAINT [CHK_discount] CHECK (([discount]>=(0) AND [discount]<=(1)))
GO
ALTER TABLE [Sales].[OrderDetails] CHECK CONSTRAINT [CHK_discount]
GO
ALTER TABLE [Sales].[OrderDetails] WITH CHECK ADD CONSTRAINT [CHK_qty] CHECK (([qty]>(0)))
GO
ALTER TABLE [Sales].[OrderDetails] CHECK CONSTRAINT [CHK_qty]
GO
ALTER TABLE [Sales].[OrderDetails] WITH CHECK ADD CONSTRAINT [CHK_unitprice] CHECK (([unitprice]>=(0)))
GO
ALTER TABLE [Sales].[OrderDetails] CHECK CONSTRAINT [CHK_unitprice]
GOUkázkové dotazy s SQL INNER JOIN
Proveďme několik ukázkových dotazů pomocí SQL INNER JOIN.
Ve výpisu 4 provedeme dotaz, který načte VŠECHNY řádky společné pro tabulky Sales.Customers a Sales.Orders. Jako podmínku pro spojení používáme sloupec custid.
Všimněte si, že klauzule ON je filtr velmi podobný klauzuli WHERE. K rozlišení tabulek jsme také použili aliasy.
-- Listing 4: Customer Orders
use TSQLV4
go
select * from Sales.Customers sc
inner join Sales.Orders so
on sc.custid=so.custid;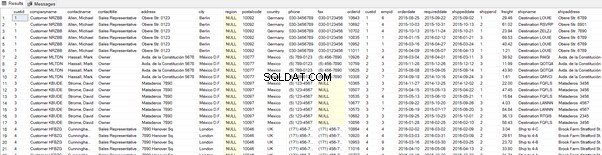
Ve výpisu 5 zužujeme dotaz na konkrétní sloupce na Prodej.Zákazníci tabulky a Sales.Orders stůl. Používáme custid sloupec jako podmínka pro spojení.
Všimněte si, že klauzule ON je filtr velmi podobný klauzuli WHERE. K rozlišení tabulek jsme také použili aliasy.
-- Listing 5: Customer Orders with specific Rows
use TSQLV4
go
select
contactname
, contacttitle
, address
, orderid
, orderdate
, shipaddress
, shipcountry
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid=so.custid;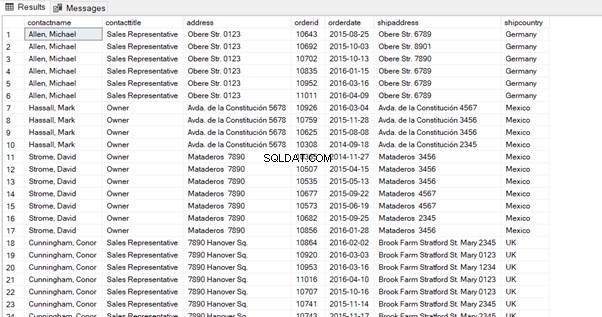
Ve výpisu 6 rozšiřujeme myšlenku zavedením klauzule WHERE, která filtruje data pro jednoho zákazníka. Do seznamu sloupců jsme také přidali aliasy.
I když to v tomto příkladu není nutné, existují případy, kdy potřebujete promítnout sloupce se stejným názvem z obou tabulek. Potom budou sloupce potřebovat výraz jako dvoudílná jména pomocí aliasů nebo názvů tabulky.
-- Listing 6: Customer Orders for a Single Customer
use TSQLV4
go
select
sc.contactname
, sc.contacttitle
, sc.address
, so.orderid
, so.orderdate
, so.shipaddress
, so.shipcountry
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid=so.custid
where sc.contactname='Allen, Michael';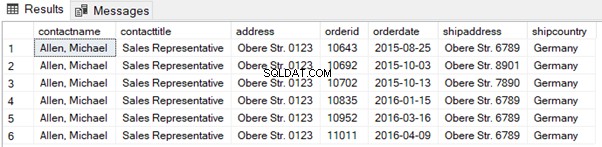
Ve výpisu 7 zavádíme sloupec custid. Můžeme rozlišit sloupce pomocí aliasu, ale nemůžeme rozlišit dva custid sloupců ve výstupu (viz obrázek 4). Můžeme to opravit pomocí aliasů:
-- Listing 7: Customer Orders for a Single Customer with Common Column
use TSQLV4
go
select
sc.custid
, sc.contactname
, sc.contacttitle
, sc.address
, so.custid
, so.orderid
, so.orderdate
, so.shipaddress
, so.shipcountry
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid=so.custid
where sc.contactname='Allen, Michael';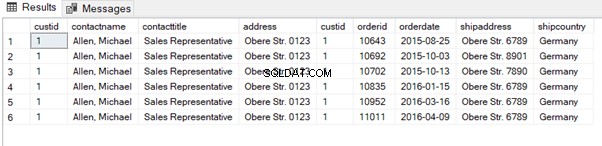
-- Listing 8: Customer Orders for a Single Customer with Aliased Column
use TSQLV4
go
select
sc.custid customer_custid
, sc.contactname
, sc.contacttitle
, sc.address
, so.custid order_custid
, so.orderid
, so.orderdate
, so.shipaddress
, so.shipcountry
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid=so.custid
where sc.contactname='Allen, Michael';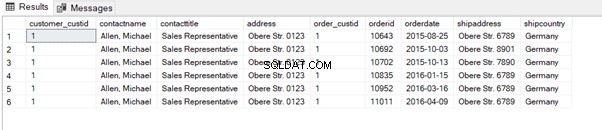
Ve výpisu 9 jsme do mixu přidali tabulku Sales.OrderDetails. Při spojování více než dvou stolů se sada výsledků z prvních dvou stolů JOIN změní na levou stůl pro další stůl. Pořadí tabulek v dotazu JOIN však neovlivňuje konečný výstup.
Všimněte si, že k načtení VŠECH sloupců z tabulky Sales.OrderDetails používáme zástupný znak.
-- Listing 9: Inner Join with Three Tables
use TSQLV4
go
select
sc.custid customer_custid
, sc.contactname
, sc.contacttitle
, sc.address
, so.custid order_custid
, so.orderid
, so.orderdate
, so.shipaddress
, so.shipcountry
, sod.*
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid=so.custid
inner join Sales.OrderDetails sod
on so.orderid=sod.orderid
where sc.contactname='Allen, Michael';Výpis 10 představuje tabulku Production.Product, která zobrazuje podrobnosti o produktu související s objednávkou.
-- Listing 10: Inner Join with Four Tables
use TSQLV4
go
select
sc.custid customer_custid
, sc.contactname
, sc.contacttitle
, sc.address
, so.custid order_custid
, so.orderid
, so.orderdate
, so.shipaddress
, so.shipcountry
, sod.*
, pp.productname
, pp.unitprice
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid=so.custid
inner join Sales.OrderDetails sod
on so.orderid=sod.orderid
inner join Production.Products pp
on sod.productid=pp.productid
where sc.contactname='Allen, Michael';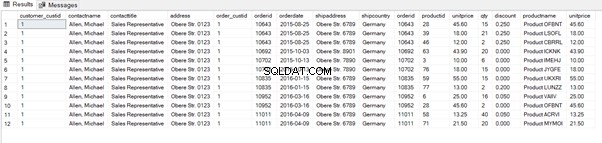
Non-Equi JOINs
Protože klauzule ON je filtr, můžeme použít jiné operátory než operátor „=“. JOIN obecně podporují použití nerovností jako <,>, !=, = v klauzuli ON. Výpis 11 to dokazuje.
Spuštění těchto dotazů vrátí různé sady výsledků.
-- Listing 11: Non-Equi JOINs, "Equal to"
use TSQLV4
go
select
contactname
, contacttitle
, address
, orderid
, orderdate
, shipaddress
, shipcountry
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid=so.custid;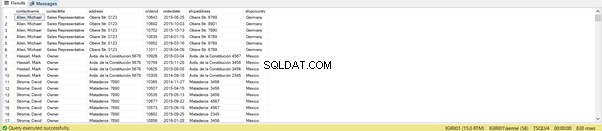
-- Listing 12: Non-Equi JOINs, "Not Equal to"
use TSQLV4
go
select
contactname
, contacttitle
, address
, orderid
, orderdate
, shipaddress
, shipcountry
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid<>so.custid;
-- Listing 13: Non-Equi JOINs, "Less than OR Equal to"
use TSQLV4
go
select
contactname
, contacttitle
, address
, orderid
, orderdate
, shipaddress
, shipcountry
from Sales.Customers sc
inner join Sales.Orders so
on sc.custid<=so.custid;Závěr
Tento článek pojednával o SQL INNER JOINs a představil příklady jeho použití. Pokrýval scénáře se dvěma, třemi a čtyřmi tabulkami ve stejném dotazu.
Pomocí souvisejících tabulek jsme také ukázali, jak bychom mohli změnit strukturu dotazu, abychom zobrazili výstup podle našich požadavků. Také jsme přidali krátké příklady Non-Equi JOINů.