Jak skvělá je funkce COALESCE v SQL?
Je to dost cool na to, aby to bylo pro mě tak důležité. A já budu víc než rád, když najmu nového chlapa, který nemá špatný zvyk ignorovat cíl COALESCE. To zahrnuje další výrazy a funkce pro řešení podobných situací.
Dnes najdete odpovědi na pět nejčastěji kladených otázek o výrazu SQL COALESCE. O jednom z nich se diskutuje znovu a znovu.
Můžeme začít?
Jaké je použití funkce COALESCE v SQL?
Dá se odpovědět dvěma slovy:obsluhování null .
Null je prázdnota hodnot. Jinými slovy neznámý. Liší se od prázdného řetězce nebo nulového čísla. Práce s hodnotami null vyžaduje použití výrazů a funkcí. Jedním z nich je COALESCE.
Abyste pochopili, co tím myslím, podívejte se na následující prohlášení:
DECLARE @number INT
SELECT @number + 33587Pojede to dobře? Bude.
Je tam problém? Momentálně žádné.
Ale výsledkem příkazů bude NULL, protože přidání null k číslu se rovná NULL.
Pokud všechny vaše dotazy spadají pouze na tuto úroveň, můžete přestat číst. Ale samozřejmě nejsou. Dostáváme zaplaceno za víc než jen za výrobu tohoto druhu kódu.
Nyní přidáme trochu ‚katastrofy‘:
DECLARE @number INT
SET @number = @number + 33587
UPDATE myTable
set col1 = @number -- Surprise! col1 is NOT NULLABLE
where ID = 1
PRINT 'Success!'Spuštění výše uvedeného kódu bude ve slepé uličce, když dosáhne příkazu UPDATE. Nevytiskne „Úspěch!“, protože do sloupce bez možnosti null nelze vložit hodnotu null. Je z tohoto prohlášení jasné, proč musíme zacházet s nulami?
Pojďme změnit kód a přidat záchrannou síť:
DECLARE @number INT
SET @number = COALESCE(@number,0) + 33587 -- our safety net. Thanks to COALESCE.
UPDATE myTable
set col1 = @number -- Disaster averted!
where ID = 1
PRINT 'Success!'COALESCE změní hodnotu null na nulu a součet nebude null.
Z toho plyne ponaučení, COALESCE je jednou ze záchranných sítí proti nulám. Ještě lepší je, že správné zacházení s nulami v kódu SQL snižuje vaše bolesti hlavy a umožňuje vám jít domů brzy. To je jisté.
Teď už chápete, proč chci ve svém týmu někoho, kdo by byl pilný ve zpracování nulových bodů.
Praktičtější příklady použití SQL COALESCE
Podívejme se na praktičtější příklady.
Předpokládejme, že žijete v oblasti, kde někteří lidé mají prostřední jména, ale jiní ne. Jak vytvoříte celé jméno z křestního jména, druhého jména a příjmení, aniž byste se dostali do pasti?
Zde je jedno možné řešení pomocí COALESCE:
USE AdventureWorks
GO
SELECT
p.LastName + ', ' + p.FirstName + ' ' + COALESCE(p.MiddleName + ' ','') AS FullName
FROM Person.Person pDalší příklad:předpokládejme, že jste zaměstnancem ve společnosti, kde se hrubá mzda počítá pro každého zaměstnance jinak. U některých z nich jsou hodinové sazby. Ostatní dostávají výplatu v týdenních nebo měsíčních sazbách.
Zde je ukázka tabulky spolu s řešením dotazu pomocí COALESCE:
-- STEP 1: Create the table
CREATE TABLE EmployeeWages (
employee_id INT PRIMARY KEY,
hourly_rate SMALLMONEY,
weekly_rate SMALLMONEY,
monthly_rate MONEY,
CHECK(
hourly_rate IS NOT NULL OR
weekly_rate IS NOT NULL OR
monthly_rate IS NOT NULL)
);
-- STEP 2: Insert data
INSERT INTO
EmployeeWages(
employee_id,
hourly_rate,
weekly_rate,
monthly_rate
)
VALUES
(1,60, NULL,NULL),
(2,40, NULL,NULL),
(3,NULL, 1000,NULL),
(4,NULL, NULL,7000),
(5,NULL, NULL,5000);
-- STEP 3: Query the monthly salary.
SELECT
employee_id,
COALESCE(
hourly_rate*22.00*8.00,
weekly_rate*4.00,
monthly_rate
) AS monthly_salary
FROM
EmployeeWages;Tabulka obsahuje různé režimy odměňování podle ID zaměstnance. Dotaz vyžaduje, abyste vypsali měsíční plat pro všechny.
Zde bude COALESCE zářit:přijímá seznam hodnot a může zde být libovolný počet položek. COALESCE vybere první, který není null:
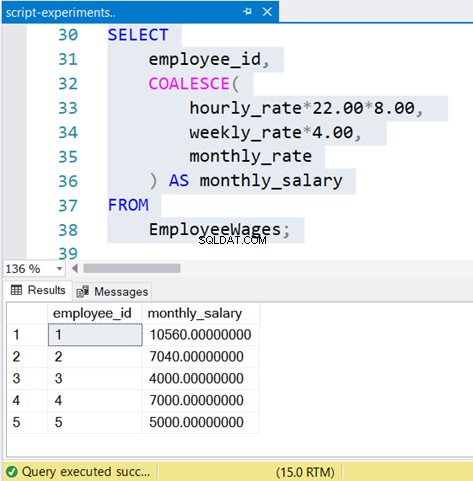
Pěkné, že?
Jak COALESCE funguje v SQL?
Definice COALESCE je výraz, který vrací první nenulovou hodnotu ze seznamu hodnot. Syntaxe COALESCE je:
COALESCE ( výraz [ ,…n ] )
Náš předchozí příklad s různými způsoby výplaty mezd to ilustruje.
Co je pod pokličkou
Pod kapotou je funkce COALESCE v SQL výrazem pokrytým cukrem pro mnohem delší výraz CASE. Eliminuje to potřebu psát ekvivalentní CASE, který je delší (a únavný pro líné písaře, jako jsem já). Výsledek bude stejný.
Můžeme to dokázat? Ano! Za prvé, Microsoft to přiznává.
Ale dobře pro nás, Microsoft to zahrnul do exekučního plánu. Takže víme, co se děje.
Zkusme to na předchozím příkladu se mzdami. Než však znovu spustíte dotaz níže, zapněte možnost Zahrnout plán skutečného provedení nebo stačí stisknout CTRL-M .
SELECT
employee_id,
COALESCE(
hourly_rate * 22.00 * 8.00,
weekly_rate * 4.00,
monthly_rate
) AS monthly_salary
FROM
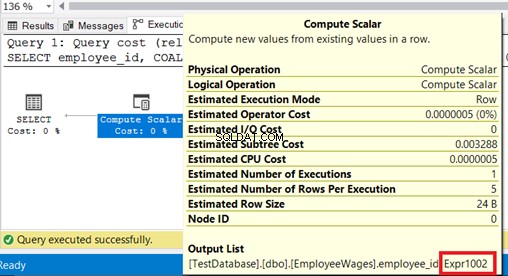
EmployeeWages;Klikněte na Prováděcí plán kartu ve výsledcích. Vypadá to jednoduše, ale náš skrytý klenot spočívá v Compute Scalar uzel. Když na něj najedete myší, uvidíte výraz s názvem Expr1002 (Obrázek 2). Co by to mohlo být?
Podívejme se hlouběji. Klikněte na něj pravým tlačítkem a vyberte možnost Zobrazit XML plánu provádění . Objeví se nové okno. Podívejte se na obrázek 3 níže:
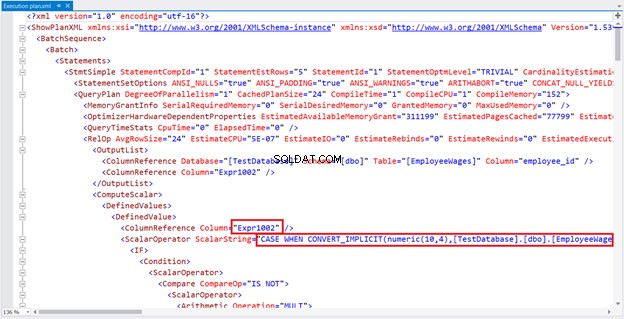
Zde je vaše prohlášení CASE. Níže je celá věc naformátována a odsazena pro čitelnost:
CASE WHEN CONVERT_IMPLICIT(numeric(10,4),[TestDatabase].[dbo].[EmployeeWages].[hourly_rate],0)
*(22.00)*(8.00) IS NOT NULL
THEN CONVERT_IMPLICIT(numeric(23,8),CONVERT_IMPLICIT(numeric(10,4),
[TestDatabase].[dbo].[EmployeeWages].[hourly_rate],0)*(22.00)*(8.00),0)
ELSE CASE WHEN
CONVERT_IMPLICIT(numeric(10,4),[TestDatabase].[dbo].[EmployeeWages].[weekly_rate],0)
*(4.00) IS NOT NULL
THEN CONVERT_IMPLICIT(numeric(23,8),CONVERT_IMPLICIT(numeric(10,4),
[TestDatabase].[dbo].[EmployeeWages].[weekly_rate],0)*(4.00),0)
ELSE CONVERT_IMPLICIT(numeric(23,8),[TestDatabase].[dbo].[EmployeeWages].[monthly_rate],0)
END
ENDTo je ve srovnání s
docela dlouhoCOALESCE(
hourly_rate * 22.00 * 8.00,
weekly_rate * 4.00,
monthly_rate
)To udělal SQL Server s naším dotazem s COALESCE. Vše je pro získání první hodnoty, která není nulová v seznamu hodnot.
Může být kratší?
vím, co si myslíš. Pokud to SQL Server provede během zpracování dotazu, COALESCE musí být pomalé. Nemluvě o vícenásobném výskytu CONVERT_IMPLICIT. Budete raději používat alternativy?
Za prvé můžete sami zadat kratší příkaz CASE. Nebo můžete použít ISNULL. Více o tom později. Když už mluvíme o tom, že jsem pomalý, měl jsem to pokryto před koncem tohoto příspěvku.
Jaké jsou rozdíly mezi COALESCE a ISNULL v SQL?
Jednou z alternativ COALESCE je ISNULL. Použití COALESCE se 2 hodnotami se podobá ISNULL. Alespoň výsledky vypadají podobně. Přesto jsou zde patrné rozdíly. Můžete jej použít jako vodítko při rozhodování, zda použijete COALESCE nebo ISNULL.
(1) ISNULL Přijímá 2 argumenty. COALESCE přijímá seznam argumentů
Je to nejviditelnější rozdíl. Ze syntaxe se to určitě liší.
ISNULL ( kontrolní_výraz , náhradní_hodnota )
COALESCE ( výraz [ ,…n ] )
Když použijete oba se 2 argumenty, výsledky jsou stejné. 2 níže uvedená tvrzení povedou k 1:
SELECT ISNULL(NULL, 1)
SELECT COALESCE(NULL, 1)I když jsou výsledky stejné, jsou míněny jinak:
- ISNULL(NULL, 1) vrátila 1, protože první argument je NULL.
- COALESCE(NULL, 1) vrátilo 1, protože 1 je první nenulová hodnota v seznamu .
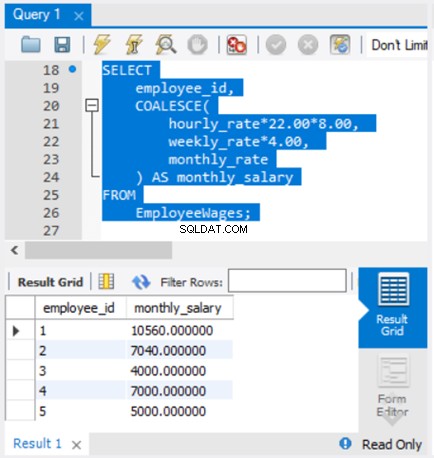
(2) COALESCE je standard SQL-92
To je správně. Můžete to zkontrolovat. Pokud například chcete přenést svůj kód SQL do MySQL ze serveru SQL Server, COALESCE bude fungovat stejně. Viz obrázek 4 a porovnejte výsledek z obrázku 1:
Použití ISNULL v MySQL však způsobí chybu, pokud použijete syntaxi SQL Serveru.
např. v SQL Server Management Studio a MySQL Workbench spusťte následující:
SELECT ISNULL(null,1)Co se stalo? V SQL Server je výstup 1. Ale v MySQL je výstupem chyba:
06:36:52 SELECT ISNULL(null,1) Kód chyby:1582. Nesprávný počet parametrů ve volání nativní funkce ‘ISNULL’
Jde o to, že ISNULL v MySQL přijímá 1 argument a vrací 1, pokud je argument null. V opačném případě vrátí 0.
(3) Předání 2 nul v COALESCE spustí chybu. S ISNULL je to v pořádku
To způsobí chybu:
SELECT COALESCE(NULL, NULL)Chyba je:‚Alespoň jeden z argumentů COALESCE musí být výraz, který není konstantou NULL.‘
Tohle bude v pohodě:
SELECT ISNULL(NULL, NULL)Změna kódu COALESCE na něco podobného níže nespustí chybu:
DECLARE @value INT = NULL
SELECT COALESCE(@value,null)Stalo se tak, protože @value není nulová konstanta.
(4) SQL COALESCE je převedeno na CASE. ISNULL Zůstane ISNULL
Viděli jsme to v článku Jak COALESCE funguje v SQL? sekce. Zde se podívejme na další příklad:
SELECT
P.LastName + ', ' + P.FirstName + ' ' + COALESCE(P.MiddleName + ' ','') AS FullName
FROM Person.Person pKontrola Prováděcího plánu XML protože skalární operátor odhalí převod na CASE:
[AdventureWorks].[Person].[Person].[LastName] as [p].[LastName]+N', '
+[AdventureWorks].[Person].[Person].[FirstName] as [p].[FirstName]+N' '
+CASE WHEN ([AdventureWorks].[Person].[Person].[MiddleName] as [p].[MiddleName]+N' ') IS NOT NULL
THEN [AdventureWorks].[Person].[Person].[MiddleName] as [p].[MiddleName]+N' '
ELSE N''
ENDNyní spusťte ekvivalentní dotaz pomocí ISNULL:
SELECT
P.LastName + ', ' + P.FirstName + ' ' + ISNULL(P.MiddleName + ' ','') AS FullName
FROM Person.Person pPoté si prohlédněte Prováděcí plán XML pro skalární operátor:
[AdventureWorks].[Person].[Person].[LastName] as [p].[LastName]+N', '
+[AdventureWorks].[Person].[Person].[FirstName] as [p].[FirstName]+N' '
+isnull([AdventureWorks].[Person].[Person].[MiddleName] as [p].[MiddleName]+N' ',N'')ISNULL je stále ISNULL.
(5) Datový typ výsledného výrazu je odlišný
Určení datového typu výsledného výrazu se také liší mezi COALESCE a ISNULL:
- ISNULL používá datový typ prvního parametru.
- COALESCE vrátí datový typ hodnoty s nejvyšší prioritou.
Seznam priorit datových typů naleznete na tomto odkazu.
Uveďme příklad:
SELECT
employee_id
,COALESCE(CAST(weekly_rate * 4 AS MONEY),0.0000) AS monthly_rate
FROM EmployeeWagesPoté zkontrolujte převod na CASE v Execution Plan XML :
CASE WHEN CONVERT(money,[TestDatabase].[dbo].[EmployeeWages].[weekly_rate]
*CONVERT_IMPLICIT(smallmoney,[@1],0),0) IS NOT NULL
THEN CONVERT_IMPLICIT(numeric(19,4), CONVERT(money,[TestDatabase].[dbo].[EmployeeWages].[weekly_rate]
*CONVERT_IMPLICIT(smallmoney,[@1],0),0),0)
ELSE (0.0000)
ENDVe výše uvedeném výrazu CASE bude datový typ výsledku numeric(19,4).
Proč? Má vyšší prioritu než peníze a malé peníze i když je ODELÍTE do peněz . Proč numerické a ne peníze ? Kvůli konstantní hodnotě 0,0000.
V případě, že vás zajímá, co je @1, Execution Plan XML má odpověď. Je to konstanta číslo 4.
<ParameterList>
<ColumnReference Column="@1" ParameterDataType="int" ParameterCompiledValue="(4)"
ParameterRuntimeValue="(4)" />
</ParameterList>Zkusme to s ISNULL:
SELECT
employee_id
,ISNULL(CAST(weekly_rate * 4 AS MONEY),0.0000) AS monthly_rate
FROM EmployeeWagesZnovu vyhledejte skalární operátor 's ScalarString :
ISNULL(CONVERT(MONEY,[TestDatabase].[dbo].[EmployeeWages].[weekly_rate]*($4.0000),0),($0.0000))Nakonec datový typ výsledného výrazu bude peníze . Je to datový typ prvního argumentu.
Jak přechytračit prioritu dat
Přednost dat můžete „přechytračit“ přidáním několika změn do kódu. Dříve měl výsledek numerický datový typ. Pokud chcete, aby výsledkem byly peníze datový typ a zbavit se CONVERT_IMPLICIT, proveďte následující:
SELECT
employee_id
,COALESCE(CAST(weekly_rate AS MONEY) * ($4.0000),($0.0000)) AS monthly_rate
FROM EmployeeWagesVšimli jste si konstant (4 000 $) a (0 0000 $)? To jsou peníze konstanty. Co se stane dále, se zobrazí v Prováděcím plánu XML 's ScalarString :
CASE WHEN CONVERT(money,[TestDatabase].[dbo].[EmployeeWages].[weekly_rate],0)*($4.0000) IS NOT NULL
THEN CONVERT(money,[TestDatabase].[dbo].[EmployeeWages].[weekly_rate],0)*($4.0000)
ELSE ($0.0000)
ENDto je mnohem lepší. Je kratší a CONVERT_IMPLICIT je pryč. A výsledný datový typ jsou peníze .
(6) Možnost NULL výsledného výrazu je různá
ISNULL(NULL, 1) a COALESCE(NULL, 1) mají podobné výsledky, ale jejich hodnoty nullability se liší. COALESCE má hodnotu null. ISNULL není. Můžete to vidět při použití na počítaných sloupcích.
Podívejme se na příklad. Níže uvedený příkaz spustí chybu, protože PRIMÁRNÍ KLÍČ nemůže přijmout hodnoty NULL. Současně je možnost nullability výrazu COALESCE pro sloupec2 vyhodnotí jako NULL.
CREATE TABLE NullabilityDemo
(
column1 INTEGER NULL,
column2 AS COALESCE(column1, 0) PRIMARY KEY,
column3 AS ISNULL(column1, 0)
);Tento příkaz je úspěšný, protože možnost null funkce ISNULL je vyhodnocena jako NOT NULL.
CREATE TABLE NullabilityDemo
(
column1 INTEGER NULL,
column2 AS COALESCE(column1, 0),
column3 AS ISNULL(column1, 0) PRIMARY KEY
);(7) Levý argument ISNULLa je vyhodnocen jednou. Je to opak s COALESCE
Zvažte znovu předchozí příklad:
SELECT
employee_id,
COALESCE(
hourly_rate*22.00*8.00,
weekly_rate*4.00,
monthly_rate
) AS monthly_salary
FROM
EmployeeWages;Poté zkontrolujte ScalarString pro toto:
CASE WHEN CONVERT_IMPLICIT(numeric(10,4),[TestDatabase].[dbo].[EmployeeWages].[hourly_rate],0)
*(22.00)*(8.00) IS NOT NULL
THEN CONVERT_IMPLICIT(numeric(23,8),CONVERT_IMPLICIT(numeric(10,4),
[TestDatabase].[dbo].[EmployeeWages].[hourly_rate],0)
*(22.00)*(8.00),0)
ELSE CASE WHEN CONVERT_IMPLICIT(numeric(10,4),[TestDatabase].[dbo].[EmployeeWages].[weekly_rate],0)
*(4.00) IS NOT NULL
THEN CONVERT_IMPLICIT(numeric(23,8),CONVERT_IMPLICIT(numeric(10,4),
[TestDatabase].[dbo].[EmployeeWages].[weekly_rate],0)*(4.00),0)
ELSE CONVERT_IMPLICIT(numeric(23,8),[TestDatabase].[dbo].[EmployeeWages].[monthly_rate],0)
END
ENDKdyž je funkce COALESCE v SQL převedena na CASE, každý výraz je vyhodnocen dvakrát (kromě posledního). Jak můžete vidět výše, hodinová_sazba*22,00*8,00 se objevil dvakrát. Totéž s weekly_rate*4.00 . Poslední výraz, měsíční_sazba , objevilo se jednou.
Protože COALESCE vyhodnotí výrazy dvakrát, může dojít k omezení výkonu. Více o tom později.
Podívejte se však na ekvivalent ISNULL:
SELECT
employee_id,
ISNULL(hourly_rate * 22.00 * 8.00,ISNULL(weekly_rate * 4.00,monthly_rate)) AS
monthly_salary
FROM EmployeeWagesPoté zkontrolujeme ScalarString v Prováděcím plánu XML :
isnull(CONVERT_IMPLICIT(numeric(10,4),[TestDatabase].[dbo].[EmployeeWages].[hourly_rate],0)*(22.00)*(8.00),
CONVERT_IMPLICIT(numeric(19,8),
isnull(CONVERT_IMPLICIT(numeric(10,4),[TestDatabase].[dbo].[EmployeeWages].[weekly_rate],0)*(4.00),
CONVERT_IMPLICIT(numeric(14,6),[TestDatabase].[dbo].[EmployeeWages].[monthly_rate],0)),0))Jak můžete vidět výše, hourly_rate , týdenní_sazba a měsíční_sazba se objevil pouze jednou. Nemusíte se tedy obávat, že výrazy budou pomocí ISNULL vyhodnocovány dvakrát.
Můžeme použít COALESCE v doložce WHERE?
Jasná věc. Není lepší způsob, než ukázat příklad, který to dokazuje.
-- Query all the names in Person table with no middle name
USE AdventureWorks
GO
SELECT
p.LastName
,p.FirstName
FROM person.Person p
WHERE COALESCE(p.MiddleName,'') = ''COALESCE vrátí prázdný řetězec, pokud MiddleName je NULL. Samozřejmě existuje kratší způsob, jak dosáhnout výsledku. Ale to ukazuje, že COALESCE funguje v klauzuli WHERE.
Co je rychlejší:COALESCE nebo ISNULL?
Konečně jsme se dostali k horkému tématu:Výkon!
Získáte mnoho stránek s testy a srovnáními, ale v komentářích bude bitva zastánců COALESCE a ISNULL. Vyčistíme prach a kouř z těchto válek.
Co je rychlejší:COALESCE nebo ISNULL? Dovolte mi začít tím, že odpověď zní:
(valení bubnů)
ZÁLEŽÍ!
(spadla čelist)
Zklamaný? Za chvíli to vysvětlím.
Za prvé, souhlasím s tím, že se zdá, že oba mají rozdíly ve výkonu, pokud jako metriku použijete uplynulý čas. Někteří lidé tuto skutečnost podpořili, když SQL Server překládá příkazy COALESCE na CASE. Mezitím ISNULL zůstane tak, jak je.
Jiní mohou uvažovat jinak kvůli různým výsledkům. Také pro ně je převod COALESCE na CASE rychlejší, než mrkneme očima. Stejně jako to, co je zdůrazněno v tomto vláknu, rozdíl ve výkonu ‚je nepatrný.‘ Souhlasím. Zde je další článek, který říká, že rozdíl ‚je menší.‘
Je tu však velký problém:můžeme věřit nepatrnému uplynulému času jako metrice? Opravdu záleží na tom, kolik logických čtení má dotaz. To je to, na co poukážeme v našich dalších příkladech.
(Podívejte se na můj další článek o logickém čtení a proč tento faktor zpožďuje vaše dotazy.)
Příklad 1
Podívejme se na stejný příklad a porovnejme jejich logické čtení a plány provádění. Před spuštěním se ujistěte, že je ZAPNUTO STATISTICS IO a Zahrnout skutečný plán provedení je povoleno.
SET STATISTICS IO ON
SELECT
P.LastName + ', ' + P.FirstName + ' ' + COALESCE(P.MiddleName + ' ','') AS FullName
FROM Person.Person p
SELECT
P.LastName + ', ' + P.FirstName + ' ' + ISNULL(P.MiddleName + ' ','') AS FullName
FROM Person.Person pZde jsou fakta:
Logické čtení pro oba dotazy jsou stejné. Oba mají 107 * 8 kB stránek. Pokud máme milion záznamů, logická čtení se samozřejmě zvýší. Ale logické čtení pro oba dotazy budou stejné. To platí, i když se COALESCE převede na CASE:
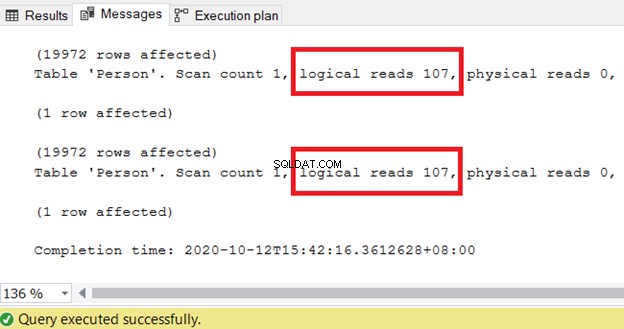
Podívejme se na plán realizace. Zde je návod, jak to uděláme:
- Proveďte 1. příkaz SELECT s výrazem COALESCE.
- Klikněte na Prováděcí plán kartu ve výsledcích. Klikněte na něj pravým tlačítkem a vyberte možnost Uložit plán provádění jako . A pojmenujte soubor plan1.sqlplan .
- Proveďte 2. příkaz SELECT s funkcí ISNULL.
- Klikněte na Prováděcí plán kartu ve výsledcích.
- Klikněte na něj pravým tlačítkem a vyberte možnost Porovnat plán představení .
- Vyberte soubor plan1.sqlplan . Zobrazí se nové okno.
Takto prověříme plán provádění u všech příkladů.
Vraťme se k našemu prvnímu příkladu, podívejte se na obrázek 6, kde je srovnání prováděcího plánu:
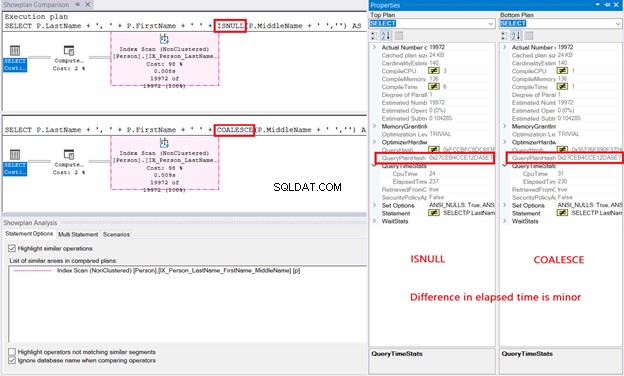
Všimli jste si těchto důležitých bodů na obrázku 6?
- Stínovaná část 2 plánů (Index Scans) znamená, že SQL Server použil stejné operace pro 2 dotazy.
- QueryPlanHash pro 2 plány je 0x27CEB4CCE12DA5E7, což znamená, že plán je pro oba stejný.
- Těch několik milisekundových rozdílů za uplynulý čas je zanedbatelných.
Takové věci
Je to jako srovnávat jablka s jablky, ale různých druhů. Jedno je jablko Fuji z Japonska, další je červené jablko z New Yorku. Přesto jsou obě jablka.
Podobně SQL Server vyžaduje stejné prostředky a zvolený plán provádění pro oba dotazy. Jediným rozdílem je použití COALESCE nebo ISNULL. Drobné rozdíly, protože konečný výsledek je stejný.
Příklad 2
Velký rozdíl se objeví, když použijete poddotaz jako argument pro COALESCE i ISNULL:
USE AdventureWorks
GO
SELECT COALESCE(
(SELECT
SUM(th.ActualCost)
FROM Production.TransactionHistory th
WHERE th.ProductID = 967)
,0)
SELECT ISNULL(
(SELECT
SUM(th.ActualCost)
FROM Production.TransactionHistory th
WHERE th.ProductID = 967)
,0)Výše uvedený kód bude mít stejný výsledek, ale uvnitř je velmi odlišný.
Začněme logickým čtením:
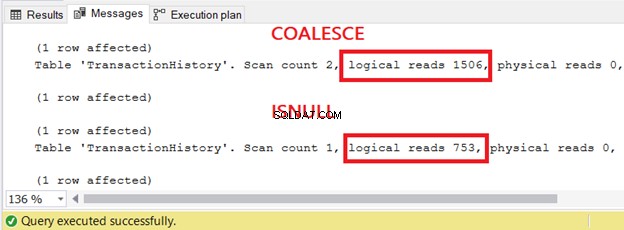
Příkaz SELECT s výrazem COALESCE má dvojnásobné logické čtení než ten, který používal ISNULL.
Ale proč zdvojnásobit logické čtení? Srovnání prováděcího plánu odhalí ještě více:
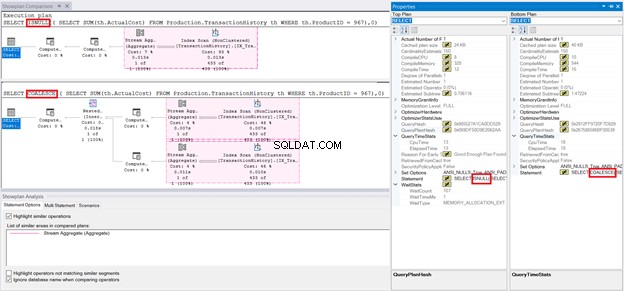
Obrázek 8 vysvětluje, proč jsou logická čtení dvojitá pomocí COALESCE. Podívejte se na 2 uzly Stream Aggregate v dolním plánu:jedná se o duplikáty. Další otázkou je, proč byla duplikována?
Připomeňme si bod, který souvisí s tím, kdy se COALESCE převede na CASE. Kolikrát jsou výrazy vyhodnoceny v argumentech? DVAKRÁT!
Poddotaz je tedy vyhodnocen dvakrát. Zobrazuje se v prováděcím plánu s duplicitními uzly.
To také vysvětluje dvojité logické čtení pomocí COALESCE ve srovnání s ISNULL. Pokud se plánujete podívat na plán provádění XML dotazu pomocí COALESCE, je to poměrně dlouhé. Ale ukazuje, že poddotaz bude proveden dvakrát.
Co teď? Můžeme to přelstít? Samozřejmě! Pokud jste někdy čelili něčemu takovému, což je podle mého názoru vzácné, možná náprava je rozdělení a panování. Nebo použijte ISNULL, pokud se jedná pouze o jeden dílčí dotaz.
Jak se vyhnout hodnocení výrazu poddotazu dvakrát
Zde je návod, jak se vyhnout hodnocení poddotazu dvakrát:
- Deklarujte proměnnou a přiřaďte k ní výsledek dílčího dotazu.
- Potom předejte proměnnou jako argument COALESCE.
- Opakujte stejné kroky v závislosti na počtu dílčích dotazů.
Jak jsem řekl, mělo by to být vzácné, ale pokud se to stane, víte, co teď dělat.
Pár slov na úrovni izolace
Vyhodnocení poddotazu dvakrát může způsobit další problém. V závislosti na úrovni izolace vašeho dotazu se může výsledek prvního vyhodnocení lišit od druhého v prostředí s více uživateli. Je to šílené.
Chcete-li zajistit návrat stabilních výsledků, můžete zkusit použít SNAPSHOT ISOLATION. Můžete také použít ISNULL. Nebo to může být přístup rozděl a panuj, jak bylo uvedeno výše.
Takové věci
Co je tedy podstatou?
- Vždy zkontrolujte logická čtení. Záleží více než na uplynulém čase. Využijte uplynulý čas a vezměte si zdravý rozum. Váš stroj a produkční server budou mít vždy různé výsledky. Dejte si pauzu.
- Vždy zkontrolujte plán provádění, abyste věděli, co se děje pod pokličkou.
- Uvědomte si, že při překladu COALESCE do CASE jsou výrazy vyhodnoceny dvakrát. Pak může být problémem poddotaz nebo něco podobného. Řešením může být přiřazení výsledku poddotazu proměnné před jeho použitím v COALESCE.
- Co je rychlejší, závisí na výsledcích logických čtení a plánech provádění. Neexistuje žádné obecné pravidlo, které by určovalo, zda je rychlejší COALESCE nebo ISNULL. Jinak by o tom mohl Microsoft informovat, jako to udělal v HierarchyID a SQL Graph.
Nakonec to opravdu záleží.
Závěr
Doufám, že se vám tento článek vyplatilo číst. Zde jsou body, o kterých jsme diskutovali:
- COALESCE je jedním ze způsobů, jak zpracovat hodnoty null. Je to záchranná síť, která zabraňuje chybám v kódu.
- Přijme seznam argumentů a vrátí první nenulovou hodnotu.
- Během zpracování dotazu se převede na výraz CASE, ale nezpomalí dotaz.
- I když existuje několik podobností s ISNULL, existuje 7 významných rozdílů.
- Lze ji použít s klauzulí WHERE.
- Konečně, není rychlejší ani pomalejší než ISNULL.
Pokud se vám tento příspěvek líbí, tlačítka sociálních sítí čekají na vaše kliknutí. Sdílení je starostlivé.
Děkuji.
Přečtěte si také
Efektivní zpracování hodnot NULL pomocí funkce SQL COALESCE pro začátečníky
Praktické použití funkce SQL COALESCE