Tabulky – Excel, Tabulky Google nebo jiný list – jsou opravdu skvělé a výkonné nástroje. Ale to jsou i databáze. Kdy byste měli zůstat u tabulky? Kdy byste měli přejít na databázi?
Toto je pokračování mého předchozího článku „Tabulky vs. databáze:Je čas přejít?“ kde jsme diskutovali o nejčastějších nevýhodách používání tabulek k uspořádání velkého množství dat. V tomto článku zjistíme, jak databáze tyto problémy řeší.
Použití databáze k uspořádání dat
Mým mottem je „použijte vhodnou technologii pro vaše potřeby“. Pokud můžete podnikat prostřednictvím listů, skvělé! Pokud potřebujete jednoduchou databázi, MS Access není špatná volba. Ale pokud vám tyto produkty nefungují, pravděpodobně budete potřebovat přizpůsobenou databázi a webovou aplikaci. Databáze bude uchovávat vaše data; webová aplikace bude uživatelsky přívětivý způsob interakce s databází a komunikace s datovou vrstvou.
Naše fiktivní podnikání nebylo příliš komplikované, takže jsme jej mohli napájet pomocí poměrně jednoduchého datového modelu. Pokud se podíváte na obrázek níže, uvidíte, že vše, co potřebujeme, je uloženo v pouhých pěti tabulkách:client_type , client , service , replacement a has_service .
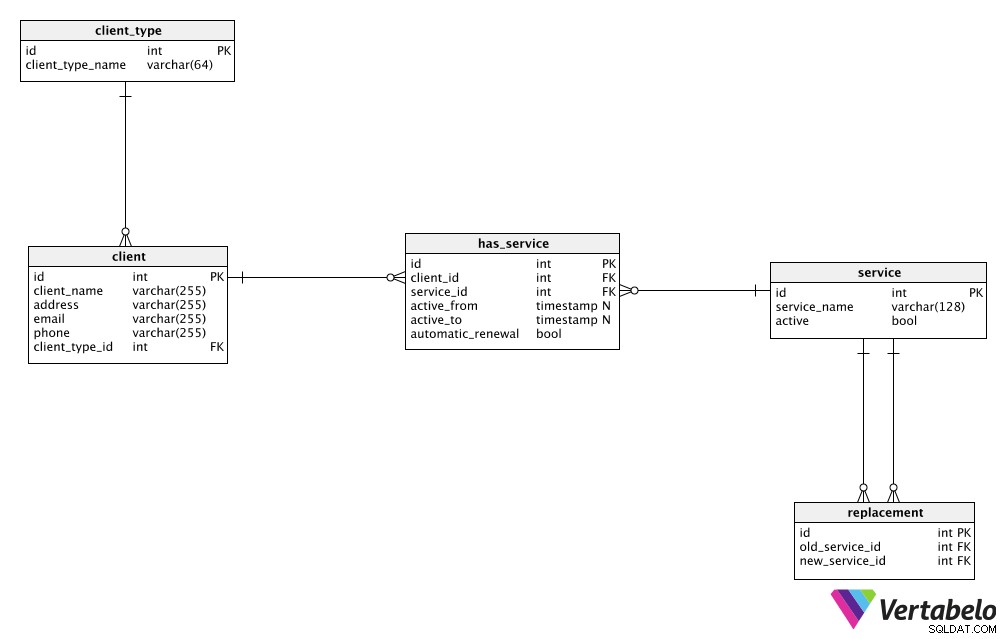
Klíčovým pravidlem návrhu databáze je uchovávat související data z reálného světa na jednom místě . V tomto případě si ponecháme všechny naše client data v klientské tabulce. Tímto způsobem se vyhneme ukládání stejných dat na více místech (špatný druh redundance zmíněný dříve). Pokud změníme cokoli související s klientem, uděláme to pouze jednou, v této tabulce. To výrazně zlepší kvalitu dat a bude dobré pro výkon.
Další tabulkou, která obsahuje data ze skutečného světa, je service stůl. Opět zde můžeme ukládat všechny detaily související s našimi službami a můžeme poměrně efektivně provádět změny v datech.
client tabulky a service tabulka jsou entity reálného světa, které by mohly existovat bez druhé. Vytváření databáze s nesouvisejícími entitami však nedává příliš smysl – je to jako mít zákazníky bez produktů nebo služeb bez kupujících. Tyto dvě tabulky tedy spojíme pomocí has_service stůl. K ukládání informací o tom, kteří klienti mají kterou službu, použijeme cizí klíče, které fungují jako reference na daného klienta a službu. Tyto cizí klíče ukazují zpět na záznamy v tabulkách služeb a klientů. V této tabulce můžeme také uchovávat jakékoli další informace související s každým vztahem mezi klienty a službami.
client_type tabulka se používá jako slovník, který ukládá všechny možné typy klientů. Nejlepší je uchovávat různé segmentace v samostatných tabulkách slovníku (např. pokud bychom měli typy zákazníků a typy rolí zaměstnanců, uložili bychom je do různých tabulek). Potřebujeme však pouze jednu tabulku, protože se jedná o jednoduchý model.
Poslední tabulkou v našem modelu je replacement stůl. Použijeme jej ke spojení dvou služeb:služby, kterou chceme nahradit, a náhradní služby. To nám dává flexibilitu nabízet klientům náhrady za stávající služby (podobně jako přechod z jednoho mobilního tarifu na jiný).
Výhody databáze
Nastavení databází je složitější než nastavení tabulek, ale ve skutečnosti jim to poskytuje některé významné výhody z hlediska integrity a zabezpečení dat:
Klíče a omezení
Databáze mají vestavěná pravidla a ovládací prvky, které při správném použití zabrání většině problémů s kvalitou dat a výkonem. Primární klíče (sloupce, které jednoznačně identifikují každý záznam v tabulce) a cizí klíče (sloupce, které odkazují na záznam v jiné tabulce) jsou zásadní pro bezpečnost dat, ale definují alternativní nebo UNIQUE klíče (které obsahují data jedinečná pro každý záznam v tabulce ) je také velmi užitečné.
V relačních databázích klíče spojují data z různých tabulek. Primární klíč tabulky je vždy UNIKÁTNÍ, zatímco cizí klíč odkazuje na primární klíč z jiné tabulky. Tento odkaz souvisí s daty z těchto dvou tabulek (např. cizí klíče ve has_service tabulka spojuje údaje o zákaznících se službami, které mají). Upozorní nás také, pokud se chystáme smazat primární klíč odkazovaný v nějaké jiné tabulce. To nám zabrání smazat záznamy, které jsou stále potřebné (jako reference) v jiné tabulce.
Omezení definují druh dat, která lze zadat do pole. Můžeme určit, že data musí mít hodnotu (NOT NULL), definovat formát pro telefonní čísla, obsahovat pouze písmena a podobně. To znamená, že se můžeme vyhnout problémům s daty od lidí, kteří do pole zadávají nesprávný druh dat.
Zabezpečení a oprávnění
Další velmi důležitou funkcí databáze je řízení přístupu k vašim datům . To vám dává možnost nejen nastavit, kdo může přistupovat k vaší databázi, ale také řídit, co může vidět nebo upravovat. To je velká část zabezpečení dat. Můžete například definovat uživatelskou roli, která umožní zaměstnanci měnit podrobnosti o zákaznících, ale ne podrobnosti o službě. Můžete také nastavit pravidla, podle kterých mohou zaměstnanci měnit nebo mazat data. Je dobrým standardním postupem zajistit, aby lidé měli přístup pouze k údajům, které potřebují ke své práci.
Samozřejmě bychom se mohli pokusit znovu vytvořit tyto funkce v listech (alespoň nějakým způsobem), ale to by rozhodně bylo „znovuobjevení kola“.
Nemohli bychom prostě použít tabulku?
Samozřejmě, že bychom mohli. Mohli bychom vytvořit listy podle stejného vzoru použitého v datovém modelu. To by vyřešilo mnoho problémů s daty, ale…
Replikace datového modelu v listech rozhodně není ideální varianta. Přišli bychom o všechny výhody, které nám databázový systém poskytuje, o všechna pravidla a omezení, která udržují data „v pořádku“, o všechny věci, které zabraňují náhodnému smazání a dalším chybám. Přišli bychom o optimalizaci, a pokud by byla datová sada dostatečně velká, výkon by byl zasažen.
I kdybychom to vyřešili, co třeba sdílení dat, např. více uživatelů používá stejný list současně? Jaké problémy s integritou dat a výkonem by to způsobilo? To by byl opak toho, aby věci byly jednoduché.
Takže pokud si myslíte, že listy nedokážou zvládnout vaše obchodní potřeby, pravděpodobně už míříte k databázi. Pokud zjistíte, že jste uvízli u dat uložených v listech a chcete se přesunout do databáze, měli byste:
- Vytvořte databázový model, který optimálně ukládá vaše data.
- Vytvořte aplikaci s databází na pozadí.
- Vymažte svá data, transformujte je (v případě potřeby) a importujte je do databáze.
- Pokračujte pouze v práci s databází.
Co byste si měli vybrat – tabulka nebo databáze?
V dnešním článku jsme se dozvěděli, jak databáze řeší problémy s používáním listů k uspořádání velkého množství dat. Moje rada je vždy jděte na nejjednodušší řešení svého problému . Pokud tabulky odvedou svou práci správně, použijte je. Ale pokud jste společnost založená na datech, měli byste začít používat databázi ASAP. Čím déle budete čekat na vyčištění a migraci dat, tím bolestnější bude proces.