Svatby jsou často doprovázeny veselím a oslavami s mnoha hosty, jídlem, pitím, hudbou a tancem. To vše se ale neobejde bez náležité přípravy a koordinace. Pojďme se blíže podívat na to, jak nám datové modelování může pomoci lépe zorganizovat svatbu, aby vše probíhalo hladce.
Předběžné pozadí
Přestože si většinou všichni uvědomujeme, jak vypadá typický svatební obřad, neuškodí krátce zvážit některé aspekty, které by mohly potenciálně ovlivnit náš datový model.
Svatební partneři
Ačkoli většina tradičních kultur bude mít obřady mezi mužem a ženou, sňatky osob stejného pohlaví se konají i v jiných společnostech. Náš datový model by měl být navržen tak, aby vyhovoval všem možnostem.
Měřítko a složitost
Svatební obřady se velmi liší svou velikostí, délkou trvání a složitostí. Některé jsou malé, skromné příležitosti, ale jiné jsou velkolepé oslavy. Například v Chorvatsku můžete uspořádat jednoduchý svatební obřad, kdy se pár vezme na radnici, vymění si prsteny a sliby před svými hosty a buď se zúčastní večeře po obřadu, nebo se vrátí domů. V jiných zemích mohou být svatby poměrně komplikované:mohou zahrnovat večírky se svobodou/bakalářkou, jednání, večeře, vícenásobné obřady a tak dále. V některých případech mohou tyto obřady trvat několik dní a mohou se konat na několika různých místech! Náš datový model by měl být opět připraven na zvládnutí těchto situací.
Konečný výsledek a výdaje
Ve většině případů se pár po oslavě vezme a obdrží fakturu na všechny náklady (nájemné, jídlo a nápoje, kapela atd.). Mohou se rozhodnout, že si najmou agenturu, která se za ně postará o všechny tyto náklady, nebo se mohou rozhodnout, že vše vyřídí sami. V každém případě bychom s těmito situacemi měli počítat.
Datový model:Přehled
Náš datový model pro tento článek se skládá z pěti částí:
- Místa
- Partneři, produkty a služby
- Svatby
- Účastníci
- Faktury
Každou z těchto oblastí důkladně probereme ve výše uvedeném pořadí. Zatímco pracujeme na vývoji našeho datového modelu, převezmeme roli agentury, která svatbu organizuje.
Část 1:Umístění
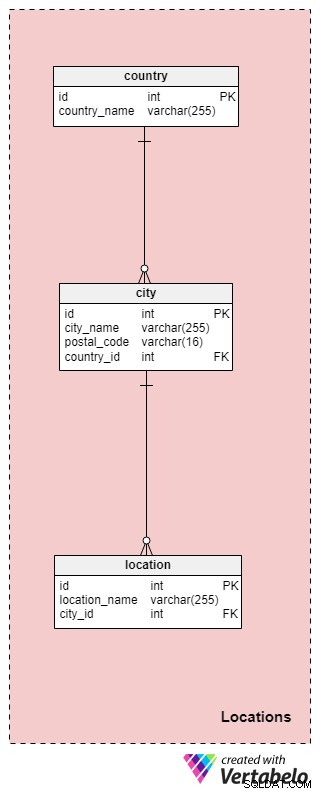
Locations sekce obsahuje univerzální tabulky, které lze použít v mnoha dalších datových modelech. Jak jsme již dříve poznamenali, celý svatební obřad by se mohl odehrávat pouze na jednom místě, nebo by mohl potenciálně zahrnovat více míst. Pojďme diskutovat o tabulkách této sekce podrobněji.
country tabulka ukládá informace o zemi, ve které se svatba koná. Ve většině případů bude tato země odpovídat umístění naší agentury, ale nemusí tomu tak být, pokud působíme mezinárodně. Každá země v této tabulce je jednoznačně definována svým country_name .
Dále musíme uložit seznam všech měst a/nebo vesnic, kde bude svatba organizována. Tyto informace budou uloženy v city stůl. U každého města uložíme jeho název a PSČ a také zemi, ve které se nachází.
Poslední tabulka v této oblasti je location . Lokality jsou konkrétnější, jako jsou radnice, kostely, parky a podobně. U každého místa uložíme jeho název a odkaz na ID města, ve kterém se nachází. Kombinace těchto dvou atributů tvoří jedinečný klíč pro tuto tabulku.
Pokud jde o místa, vezměte na vědomí, že jsme zde zvolili konzervativní přístup, abychom se vyhnuli pokrytí neobvyklých případů, kdy se obřad koná například ve vlaku nebo v letadle (v takovém případě může „místo“ zahrnovat více měst). Pokud bychom chtěli pokrýt tyto případy, museli bychom v našem modelu provést nějaké změny.
Část 2:Partneři, produkty a služby

Než přejdeme k centrální části našeho datového modelu, musíme si uložit seznam všech partnerů, se kterými spolupracujeme, a také produkty a služby, které nabízejí. Abychom toho dosáhli, použijeme pět tabulek.
Za prvé, seznam všech partnerů, se kterými spolupracujeme, je uložen v partner slovník. U každého partnera uložíme jeho jedinečný partner_code a partner_name .
Naši partneři samozřejmě zajistí služby spojené se svatbou, mezi které může patřit catering, organizace kapel, nastavení audio a video techniky, zajištění podpory pronájmu a mnoho dalšího. V podstatě vše, na co si vzpomenete, může nějakým způsobem souviset se svatbou. Tento seznam služeb uložíme ve service slovník. Pro každou službu uložíme:
service_code– hodnotu, kterou budeme interně používat k jedinečnému označení konkrétní služby.service_name– název služby. Všimněte si, že různé služby mohou sdílet stejný název. K tomu by došlo, pokud by dva naši partneři náhodou nabízeli stejnou službu, což je docela pravděpodobné. Bylo by dokonce žádoucí, kdyby používali stejný název pro stejný typ služby, protože by to výrazně usnadnilo porovnávání cen za stejné služby.description– volitelný textový popis služby.picture– odkaz na místo, kde je uložen příslušný obrázek služby.price– aktuální cena za tuto službu. Může obsahovat hodnotu NULL, pokud cenu nelze určit bez předchozího vyhodnocení různých faktorů, například kolik lidí se plánuje zúčastnit obřadu.
provides_service tabulka uvádí partnery do vztahu k seznamu služeb, které poskytují. Pro každou jedinečnou kombinaci partner_id a service_id , uložíme podrobný textový popis povahy služby poskytované partnerem a zda je služba aktuálně dostupná.
Potřebujeme také tabulky pro ukládání informací o produktech a jejich vztazích k partnerům. product tabulka má stejnou logiku jako service stůl, kromě toho, jak název napovídá, je specifický pro produkty. V této tabulce uložíme všechny možné produkty, které jsou nezbytné pro většinu svatebních obřadů, jako jsou prsteny, oblečení, dekorace, květiny, nábytek a další.
Poslední tabulkou v této sekci je provides_product stůl. Funguje stejně jako provides_service tabulka, kromě toho, že je specifická pro produkty na rozdíl od služeb. Uvádí, který z našich partnerů daný produkt nabízí.
Část 3:Svatby
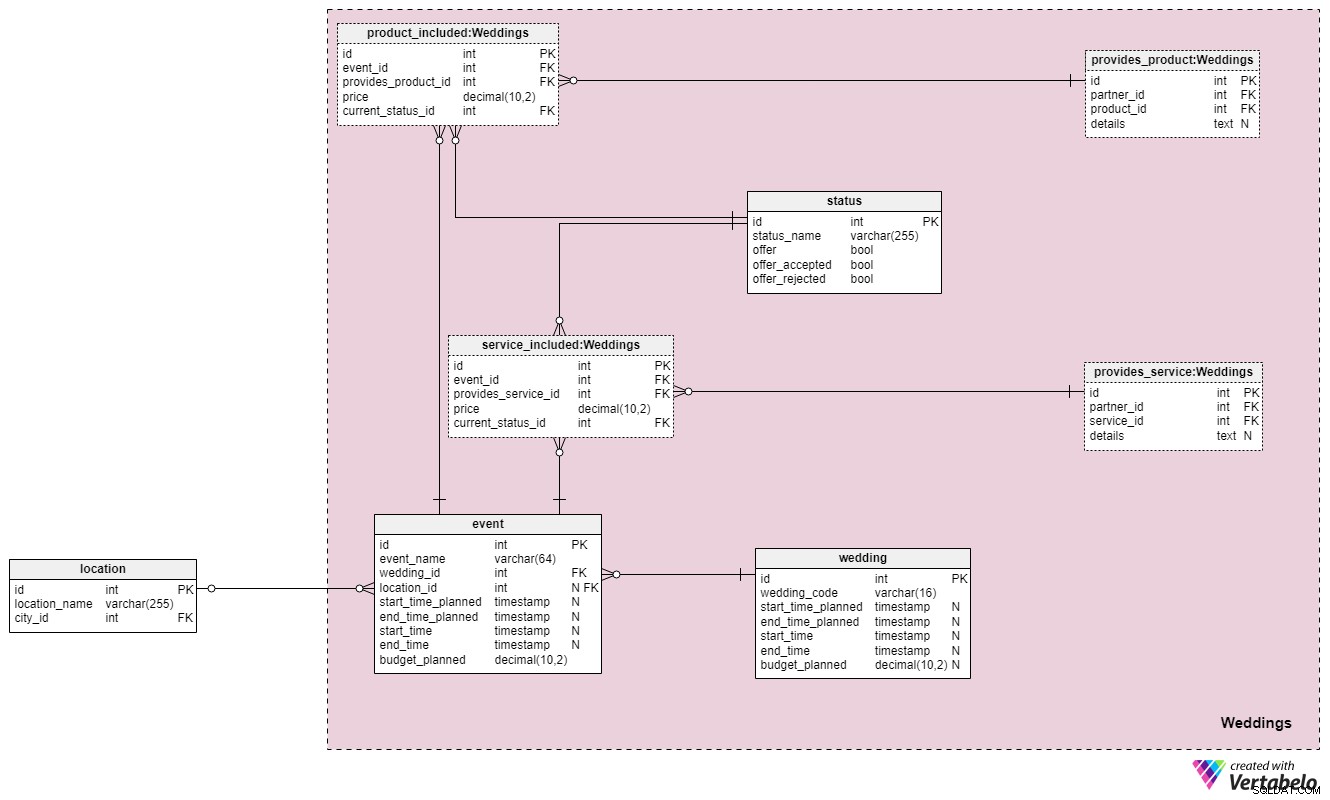
Konečně jsme se dostali k jádru našeho datového modelu – Weddings sekce. Obsahuje pět nových tabulek, které odkazují na tabulky jiných sekcí. Všimněte si, že na vlastní tabulky této části bude odkazováno také v nadcházejících částech našeho modelu.
Na wedding stůl, uložíme kompletní seznam všech svateb, na jejichž organizaci jsme/byli zapojeni. Každá svatba bude mít svůj vlastní jedinečný wedding_code . Uložíme také plánované časy začátku a konce celého obřadu a skutečné časy začátku a konce aktualizujeme, kdykoli budou tyto informace k dispozici. Kromě toho uložíme budget_planned hodnotu, takže máme alespoň odhad, kolik to všechno bude stát. Všechny další podrobnosti související se svatbou jsou uloženy v jiných oblastech datového modelu, takže to je vše, co nyní opravdu potřebujeme.
Smyslem je pojmout každou svatbu jako sérii událostí. Události se zase budou týkat nabídek požadovaných produktů/služeb, odmítnutých a přijatých nabídek a dalších relevantních podrobností. Abyste měli lepší představu o tom, jak to celé funguje, mohli bychom celou svatbu rozdělit do následujících akcí:plánovací fáze, rozlučka se svobodou/bakalářkou, obřad a afterparty/večeře. To jsou samozřejmě jen některé z nejčastějších svatebních událostí. Všechny svatební události jsou uloženy v tabulce událostí. event bude mít jedinečné ID.
Každá událost je spojena s jednou svatbou a bude se týkat buď jednoho místa, nebo žádné. Druhý případ nastává, pokud je událost více koncepční , jako je fáze plánování (protože neexistuje jediné místo, kde se musí uskutečnit). Stejně jako u samotného svatebního obřadu bude mít událost plánovaný a skutečný začátek/konec a také plánovaný rozpočet. Všimněte si, že jsme zde věci zjednodušili, pokud jde o umístění. Pokud se události týkají více míst, budeme muset upravit náš datový model.
Dále chceme uložit všechny služby a produkty, které souvisejí s událostí. K tomu použijeme tři tabulky:status , product_included a service_included .
status tabulka je slovník, který sleduje všechny stavy související s produkty a službami pro konkrétní událost. Zahrnuje proměnné příznaků, které označují, zda byl produkt/služba nabídnuta, přijata nebo odmítnuta. Pro každý záznam v této tabulce uložíme jedinečný status_name .
Zbývající dvě tabulky v této části s názvem product_included a service_included , se podobají navzájem strukturálně a koncepčně. Pro každou událost uložíme seznam produktů a služeb, které byly nabízeny, a změníme jejich stavy, pokud budou přijaty nebo odmítnuty. Pro každý záznam v těchto dvou tabulkách uložíme následující společné atributy:
event_id– odkaz na související událost.provides_product_id/provides_service_id– odkazy na tabulky s produkty/službami, které naši partneři nabízejí.price– navrhovaná cena za produkt/službu. Tato cena se může lišit od standardní ceny, kterou máme v záznamech, pokud navrhneme speciální nabídku.current_status_id– odkaz nastatusslovník označující, zda byl tento záznam nabídnut, přijat nebo odmítnut.
Část 4:Účastníci
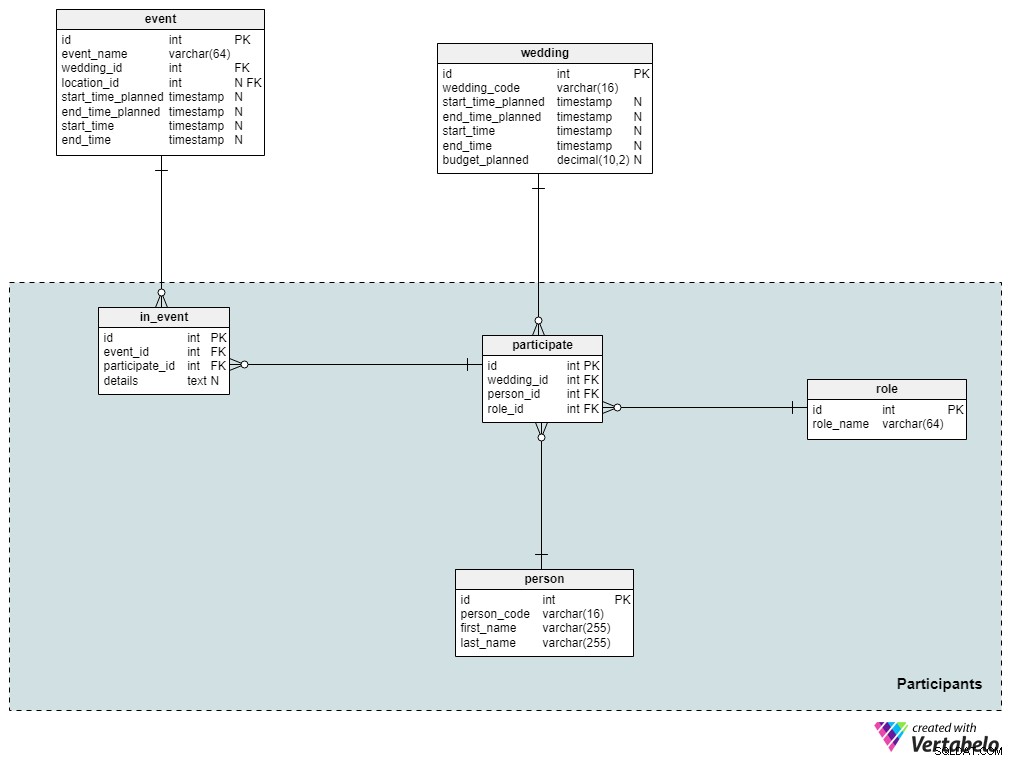
Pokud pořádáte velkou svatbu, je pravděpodobné, že znáte většinu hostů, kteří se plánují zúčastnit. Hosté, které pozvete – ať už jsou to vaši přátelé nebo příbuzní – samozřejmě přivedou další lidi, které osobně neznáte, například jejich přátele nebo kolegy. V této sekci uložíme kompletní seznam hostů, kteří byli pozváni na svatbu, a také jejich role.
person tabulka obsahuje seznam všech osob, které jsou součástí svatby. U každého jednotlivce uložíme jeho jedinečný person_code a jména a příjmení. Pokud budeme chtít, můžeme samozřejmě přidat další podrobnosti.
Dále definujeme všechny možné role, které by člověk mohl během svatby převzít. Mezi tyto role patří „host“, „nejlepší muž“, „družba“, „družička“, „nevěsta“, „ženich“ a tak dále. Pro každou roli uložíme pouze jedinečný role_name v této tabulce. Osoba může na konkrétní svatbě převzít pouze jednu roli.
Dále propojíme svatby s jejich účastníky. Všimněte si, že se participate tabulka obsahuje pouze odkazy na tabulky wedding , person a role . Kombinace wedding_id a person_id slouží jako alternativní klíč pro tuto tabulku.
Svatba se bude skládat z několika akcí, ale ne všichni účastníci se do nich zapojí. Proto musíme tyto informace ukládat samostatně. V in_event tabulky, uložíme jedinečné páry cizích klíčů odkazujících na tabulky event a participate . Všechny dodatečné informace budou uloženy v details přiřazený text.
Část 5:Faktury
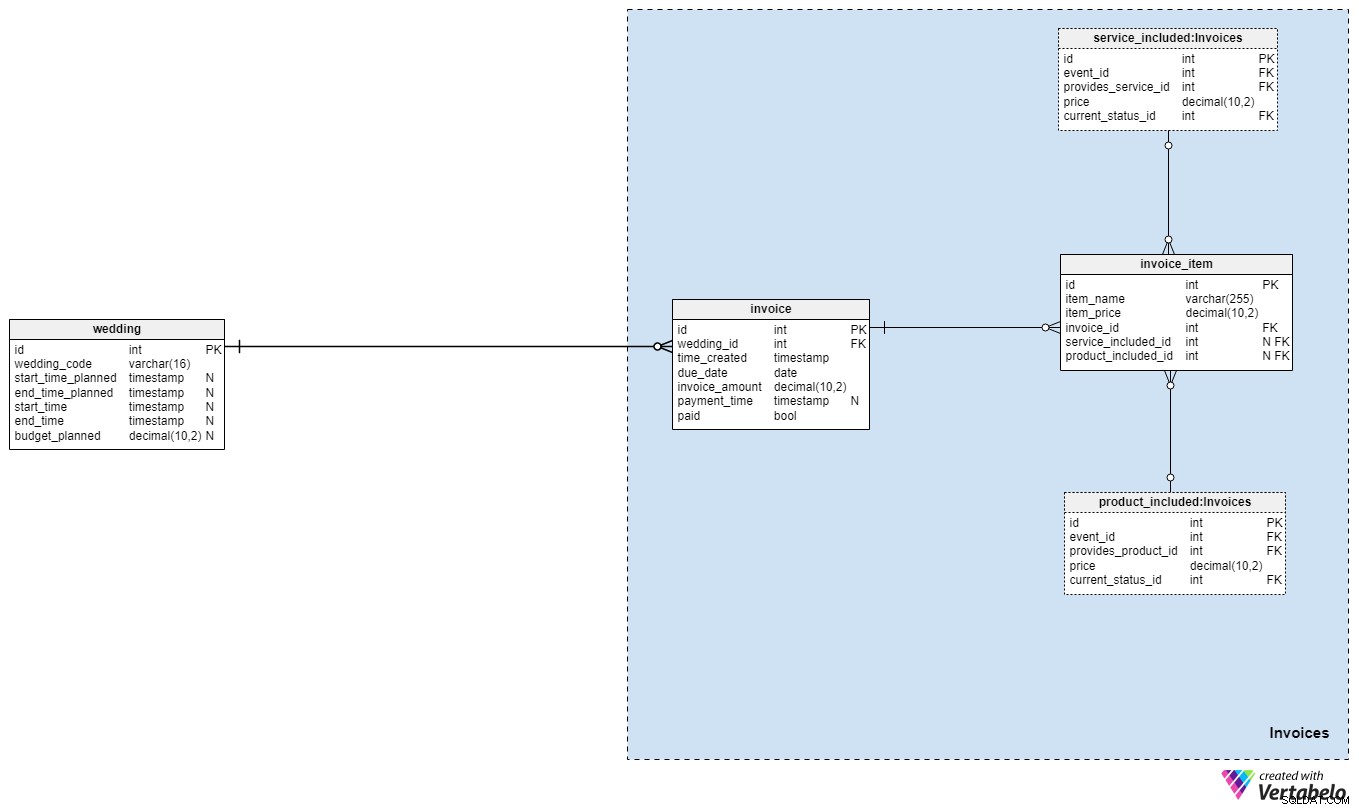
Jsme téměř hotovi! Poslední sekce našeho datového modelu nám umožňuje sledovat výdaje související se svatbou. Vzrušující, že?
Obvykle vygenerujeme jednu invoice na svatbu, ale mohli bychom také vygenerovat více, pokud bychom potřebovali. Doufejme, že celková částka, kterou páru fakturujeme, bude těsně odpovídat našemu plánovanému rozpočtu, ale nemusí to tak být vždy. U každé faktury uložíme následující informace:
wedding_id– odkaz na svatbu, na kterou byla vystavena faktura.time_created– časové razítko, kdy byla faktura vygenerována.due_date– datum, do kterého musí být faktura uhrazena.invoice_amount– celková částka, která musí být zaplacena.payment_time– časové razítko, kdy byla platba skutečně vystavena. Tento atribut bude samozřejmě obsahovat hodnotu NULL, dokud nebude platba provedena.paid– příznak označující, zda byla faktura zaplacena. Tento atribut bude nastaven na hodnotu „True“, jakmile budepayment_timeje aktualizován.
Poslední tabulka v našem modelu se týká samotných fakturovaných položek. Uložíme je do invoice_item stůl. Pro každý záznam uložíme následující podrobnosti:
item_name– námi zvolený název pro konkrétní položku.item_price– cena, která se vztahuje k dané konkrétní položce.invoice_id– ID související faktury.service_included_id– ID služby, ke které se položka faktury vztahuje. Tento atribut lze nastavit na hodnotu NULL, pokud daná položka ve skutečnosti nesouvisí s žádnou službou nebo pokud se jedná pouze o dodatečný poplatek, který jsme naúčtovali na fakturu.product_included_id– ID produktu, ke kterému se položka faktury vztahuje. Tento atribut lze nastavit na hodnotu NULL, pokud daná položka ve skutečnosti nesouvisí s žádným produktem nebo pokud se jedná pouze o dodatečný poplatek, který jsme naúčtovali na faktuře.
Shrnutí
To docela vystihuje tento datový model! Opět vidíme, jak užitečné je datové modelování při organizování firemních informací.
Jak jsme poznamenali, existuje mnoho věcí, které jsme z našeho datového modelu pro jednoduchost vynechali. Náš model by měl například ideálně sledovat historii nabídek, finanční podrobnosti a další.
Pokud máte nějaké návrhy, dejte nám vědět níže. Rádi bychom slyšeli váš názor!