Životní pojištění je něco, o čem všichni doufáme, že ho nebudeme potřebovat, ale jak víme, život je nepředvídatelný. V tomto článku se zaměříme na formulování datového modelu, který může životní pojišťovna použít k ukládání svých informací.
Životní pojištění jako koncept
Než začneme diskutovat o skutečném datovém modelu pro životní pojišťovnu, krátce si připomeneme, co pojištění je a jak funguje, abychom měli lepší představu o tom, s čím pracujeme.
Pojištění je docela starý koncept, který sahá ještě před středověk, kdy mnoho cechů nabízelo pojistky na ochranu svých členů v neočekávaných situacích. Dokonce i slavný astronom, matematik, vědec a vynálezce Edmund Halley fušoval do pojištění, pracoval na statistikách a úmrtnosti, které tvořily páteř moderních pojistných modelů.
Proč byste měli platit za pojištění? Myšlenka je celkem jednoduchá – zaplatíte určitou částku (pojistné) výměnou za záruku pojišťovny, že vy nebo vaše rodina budou finančně odškodněni, pokud se vám nebo vašemu majetku stane něco neočekávaného. V případě životního pojištění určíte oprávněnou osobu, která v případě vaší smrti obdrží peněžní částku (dávku). Myšlenka je, že tyto peníze jim pomohou zotavit se ze ztráty, zvláště pokud vaše smrt způsobí nějaké finanční problémy.
Pojišťovny samozřejmě obvykle vyplácejí na dávkách mnohem méně, než vydělají z pojistného a z investování vašich peněz, řekněme, na akciovém trhu. Jinak by zkrachovali a celý systém by se rozpadl!
To je zhruba podstata věci. Teď, když to máme z cesty, pojďme se podívat na datový model pro typickou životní pojišťovnu.
Datový model:Přehled
Datový model, se kterým budeme pracovat, se skládá z pěti tematických oblastí:
- Zaměstnanci
- Produkty
- Klienti
- Nabídky
- Platby
Každou z těchto sekcí probereme podrobněji v pořadí, v jakém jsou uvedeny výše.
Předmět č. 1:Zaměstnanci
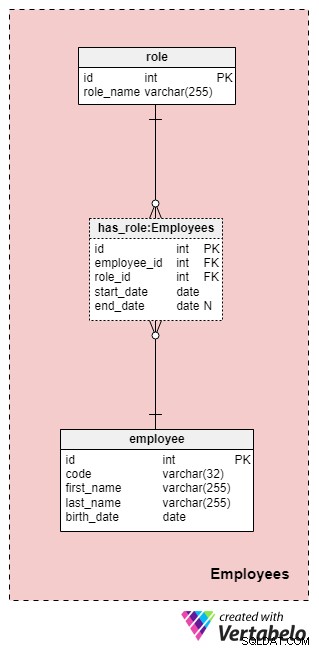
Tato oblast není nutně specifická pro tento datový model, ale je stále velmi důležitá, protože na tabulky obsažené v tomto dokumentu budou odkazovat jiné předmětné oblasti. Pro účely našeho datového modelu pojišťovny budeme samozřejmě potřebovat vědět, kdo jaký úkon provedl (např. kdo zastupoval naši společnost při práci se zákazníkem/klientem, kdo podepsal pojistku atd.).
Seznam všech zaměstnanců společnosti je uložen v employee stůl. Pro každého zaměstnance uložíme následující informace:
code— jedinečný klíč, který identifikuje jednoho zaměstnance. Protože kód bude použit jako atribut v jiných tabulkách, bude v této tabulce sloužit jako alternativní klíč.first_namealast_name— jméno a příjmení zaměstnance.birth_date— datum narození zaměstnance.
Do této tabulky bychom samozřejmě mohli zahrnout mnoho dalších atributů souvisejících se zaměstnanci, ale tyto čtyři jsou prozatím více než dostačující. Tímto vzorem se budeme řídit v celém článku a budeme se snažit, aby věci byly co nejjednodušší, ale nezapomeňte, že tento datový model můžete rozhodně rozšířit o další informace.
Vzhledem k tomu, že zaměstnanci mohou své role v naší společnosti kdykoli změnit, budeme potřebovat tabulku slovníku pro reprezentaci rolí společnosti a tabulku pro ukládání hodnot. Seznam všech možných rolí, které mohou zaměstnanci u naší životní pojišťovny zastávat, je uložen v role slovník. Má pouze jeden atribut s názvem role_name který obsahuje jednoznačně identifikující hodnoty.
Propojíme zaměstnance a role pomocí has_role stůl. Kromě cizích klíčů employee_id a role_id , uložíme dvě hodnoty:start_date a end_date . Tyto dvě hodnoty označují rozsah, ve kterém byla tato firemní role aktivní pro konkrétního zaměstnance. end_date bude obsahovat hodnotu null, dokud nebude určeno datum ukončení role tohoto zaměstnance. Alternativní klíč pro tuto tabulku je kombinace employee_id , role_id a start_date . Abychom se vyhnuli duplikování stejné role pro stejného zaměstnance, budeme muset programově kontrolovat, zda nedochází k překrývání pokaždé, když do tabulky přidáme nový záznam nebo aktualizujeme existující.
Předmět č. 2:Produkty
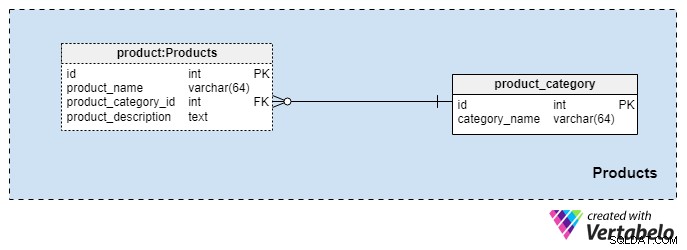
Tato oblast je poměrně malá a obsahuje pouze dvě tabulky. Hodnoty z těchto tabulek jsou nezbytnými předpoklady pro naše další obory, proto je krátce probereme.
product_category slovník ukládá nejobecnější kategorie produktů, které plánujeme nabízet našim klientům. Jediná hodnota, kterou v této tabulce uložíme, je jedinečný category_name k označení typu pojištění, které nabízíme, což může být osobní životní pojištění, rodinné životní pojištění a tak dále.
Pomocí product stůl. Tato tabulka představuje skutečné produkty, které prodáváme, nikoli jejich kategorie. Jak si dokážete představit, můžeme produkty seskupit podle délky trvání (např. 10 nebo 20 let nebo dokonce životnost). Pokud se tak rozhodneme udělat, pravděpodobně budeme mít produkty se stejným product_category_id ale různá jména a popisy. U každého produktu uložíme následující základní informace:
product_name— název tohoto produktu. Používá se jako alternativní klíč pro tuto tabulku v kombinaci sproduct_category_idatribut. Je nepravděpodobné, že budeme mít dva produkty se stejným názvem, které patří do různých kategorií, ale přesto je to možné.product_category_id— označuje kategorii, do které tento produkt patří.product_description— textový popis tohoto produktu.
Předmět č. 3:Klienti
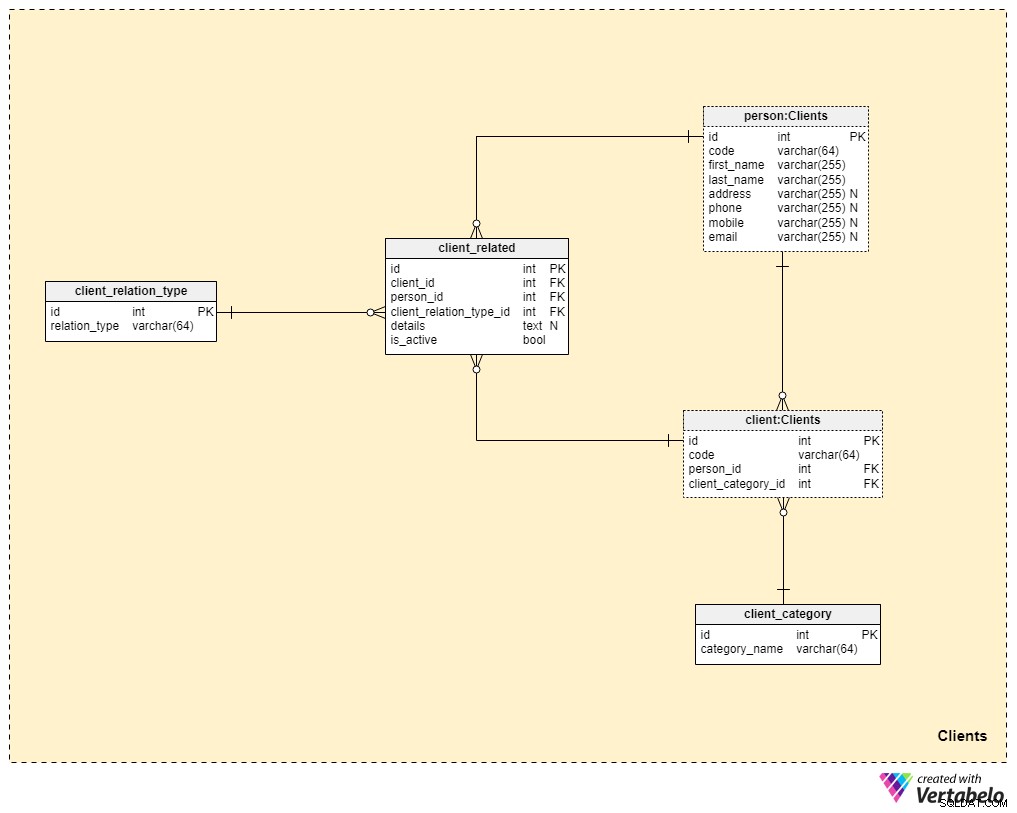
Nyní se dostáváme mnohem blíže k jádru našeho datového modelu, ale ještě tam úplně nejsme. Životní pojištění je jedinečné, protože pojistku lze převést na člena rodiny nebo někoho jiného, zatímco pojistky pro jiné formy pojištění (jako je zdravotní pojištění nebo pojištění auta) patří jedinému klientovi a nelze je převést. Z tohoto důvodu budeme muset uchovávat nejen informace o klientovi, kterému zásady patří, ale také informace o všech souvisejících lidech a jejich vztahu ke klientovi.
Začneme client stůl. Pro každého klienta uložíme jedinečný kód vygenerovaný nebo ručně vložený pro daného klienta a také cizí klíče odkazující na tabulku s jeho osobními údaji (person_id ) a tabulku obsahující naši interní kategorizaci (client_category_id ).
client_category slovník nám umožňuje seskupit klienty na základě jejich demografických a finančních údajů. Kategorie klientů pak budou použity k určení pojistné smlouvy, kterou jsme připraveni nabídnout konkrétnímu klientovi. Zde uložíme pouze seznam jedinečných hodnot, které pak přiřadíme klientům.
Jelikož se bavíme o životním pojištění, budeme předpokládat, že klientem je jednotlivec. Jak jsme však uvedli dříve, mohou existovat další osoby spřízněné s klientem, na které může být pojistka převedena nebo kteří mohou po smrti klienta získat pojistnou výhodu. Z tohoto důvodu jsme vytvořili samostatnou person stůl. Pro každý záznam v této tabulce uložíme následující informace:
code— automaticky vygenerovaná nebo ručně vložená hodnota používaná k jednoznačné identifikaci související osoby.first_namealast_name– jméno a příjmení dané osoby.address,phone,mobileaemail— kontaktní údaje této osoby, z nichž všechny obsahují libovolné hodnoty.
Zbývající dvě tabulky v této oblasti jsou potřebné pro popis povahy vztahu mezi klienty a ostatními lidmi.
Seznam všech možných typů vztahů je uložen v client_relation_type slovník. Stejně jako u jiných slovníků bude tento obsahovat seznam jedinečných jmen, která později použijeme při popisu vztahu mezi konkrétním klientem a jinou osobou.
Aktuální relační data jsou uložena v client_related stůl. Pro každý záznam v této tabulce uložíme odkazy na klienta (client_id ), související osoba (person_id ), povahu tohoto vztahu (client_relation_type_id ), všechny podrobnosti o přidání (details ), pokud existuje, a příznak udávající, zda je vztah aktuálně aktivní (is_active ). Alternativní klíč v této tabulce je definován kombinací client_id , person_id a client_relation_type_id .
Předmět č. 4:Nabídky
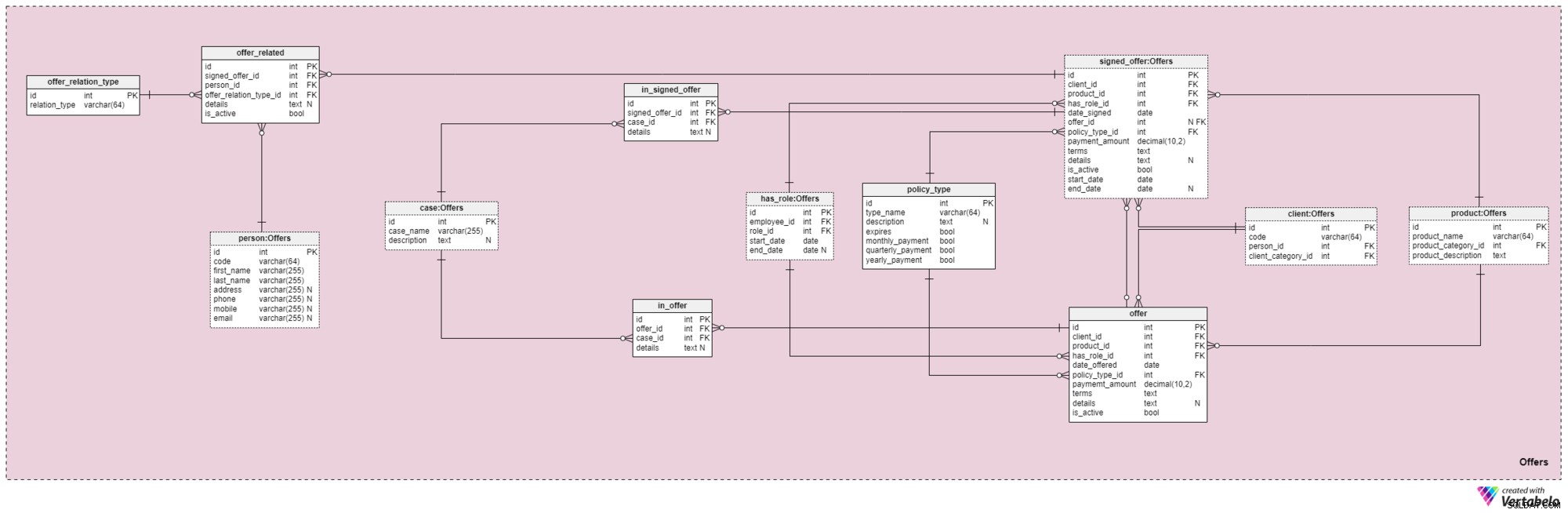
Tato předmětná oblast a následující oblast jsou jádrem tohoto datového modelu. Zahrnují nabídky a podepsané zásady a také platby související s nabídkami. Nejprve popíšeme předmět nabídky. Může se zdát složitý, protože obsahuje 12 tabulek. Nicméně čtyři z těchto 12 (has_role , product , client a person ) byly popsány v předchozích tematických oblastech, takže zde naši diskuzi opakovat nebudeme.
offer a signed_offer tabulky mají podobnou strukturu, protože budou použity k ukládání velmi podobných dat v našem modelu. Zatímco však offer bude sloužit především k uložení jakýchkoli zásad (a jejich podrobností), které jsme našim klientům nabídli, signed_offer tabulka bude striktně používána k ukládání informací o klientech, kteří skutečně podepsali smlouvy s naší společností. Tyto tabulky pokryjeme společně a všímáme si všech rozdílů, kde se vyskytují. Atributy v těchto dvou tabulkách jsou následující:
client_id— odkaz na jedinečný identifikátor klienta, který podepsal konkrétní nabídku.product_id— odkaz na jedinečný identifikátor produktu, který byl součástí podepsané nabídky.has_role_id— odkaz na ID zaměstnance a roli, kterou zastával v době, kdy byla nabídka předložena/podepsána.date_offeredadate_signed— aktuální data označující, kdy byla tato nabídka klientovi předložena a kdy byla podepsána.offer_id— odkaz na předchozí nabídku pro tohoto klienta. To může obsahovat hodnotu null, protože klient mohl podepsat smlouvu, aniž by měl předchozí nabídku od společnosti, jako kdyby se na nás obrátil sám. Tento atribut striktně patří dosigned_offerstůl.policy_type_id— odkaz na slovník typů zásad označující typ zásad, které jsme klientovi nabídli nebo je nechali podepsat.payment_amount— částka, kterou musí klient za pojistku pravidelně platit.terms— všechny podmínky smlouvy v textovém (XML) formátu. Cílem je uložit všechny důležité podrobnosti týkající se finanční části politiky do tohoto atributu. Příklady textu, který bychom mohli uložit, jsou celková částka pojistky, počet plateb, které musí klient provést, a tak dále.details— jakékoli další podrobnosti v textovém formátu.is_active— příznak označující, zda je záznam stále aktivní.start_dateaend_date— označte časový rozsah, ve kterém je/byla tato politika aktivní. Pokud byla zásada podepsána na celý život, pak end_date bude obsahovat hodnotu null.
Je zde také policy_type slovník, o kterém jsme se již krátce zmínili. Potřebujeme určitou míru flexibility v tom, jak nabízíme stejný produkt různým klientům, na základě faktorů, jako je věk, zdravotní stav, rodinný stav, úvěrové riziko a tak dále. Pro každý typ zásad uložíme type_name identifikátor, další textový description , příznak s názvem vyprší označující, zda může platnost pojistky vypršet, a další příznak označující, zda je nutné pojistné tohoto typu pojistky platit měsíčně, čtvrtletně nebo ročně. Některé očekávané typy pojistek jsou:doživotní, doživotní, univerzální, zaručené univerzální, variabilní, variabilní univerzální a životní pojištění po odchodu do důchodu.
Nyní musíme definovat všechny případy a situace, které může konkrétní politika pokrývat. Tyto případy musíme propojit s konkrétními nabídkami a podepsanými nabídkami.
Seznam všech možných případů, které naše zásady pokrývají, je uložen v case slovník. Každý záznam v této tabulce lze jednoznačně identifikovat podle svého case_name a má další description , pokud je potřeba.
in_offer a in_signed_offer tabulky sdílejí stejnou strukturu, protože ukládají stejná data. Jediný rozdíl mezi těmito dvěma je, že první ukládá případy zahrnuté v zásadě, která byla pouze nabídnuta klientovi, zatímco druhá ukládá případy v zásadě podepsané klientem. Pro každý záznam v těchto dvou tabulkách uložíme jedinečný pár offer_id /signed_offer_id a case_id , z nichž druhý označuje případ nebo incident, na který se vztahuje pojistka. Všechny ostatní podrobnosti budou v případě potřeby uloženy v textovém atributu.
Jak jsme již zmínili, životní pojistky se téměř vždy týkají nejen klientů, ale i jejich rodinných příslušníků či příbuzných. Tyto vztahy musíme uložit i v této oblasti. Budou definovány v době podpisu zásady, ale mohou být také změněny po celou dobu trvání zásady.
První věc, kterou musíme udělat, je vytvořit slovník obsahující všechny možné hodnoty, které lze vztahu přiřadit. V našem modelu se jedná o offer_relation_type slovník. Kromě primárního klíče tato tabulka obsahuje pouze jeden atribut – relation_type – který může obsahovat pouze jedinečné hodnoty.
Už tam skoro jsme! Poslední tabulka v této oblasti má název offer_related . Vztahuje se podepsaná nabídka na kohokoli, kdo je ve spojení s klientem. Proto budeme muset ukládat odkazy na podepsané zásady (signed_offer_id ) a související osoba (person_id ) a také specifikujte povahu tohoto vztahu (offer_relation_type_id ). Kromě toho budeme muset uložit details související s tímto záznamem a vytvořte příznak pro kontrolu, zda je v našem systému stále platný.
Předmět č. 5:Platby
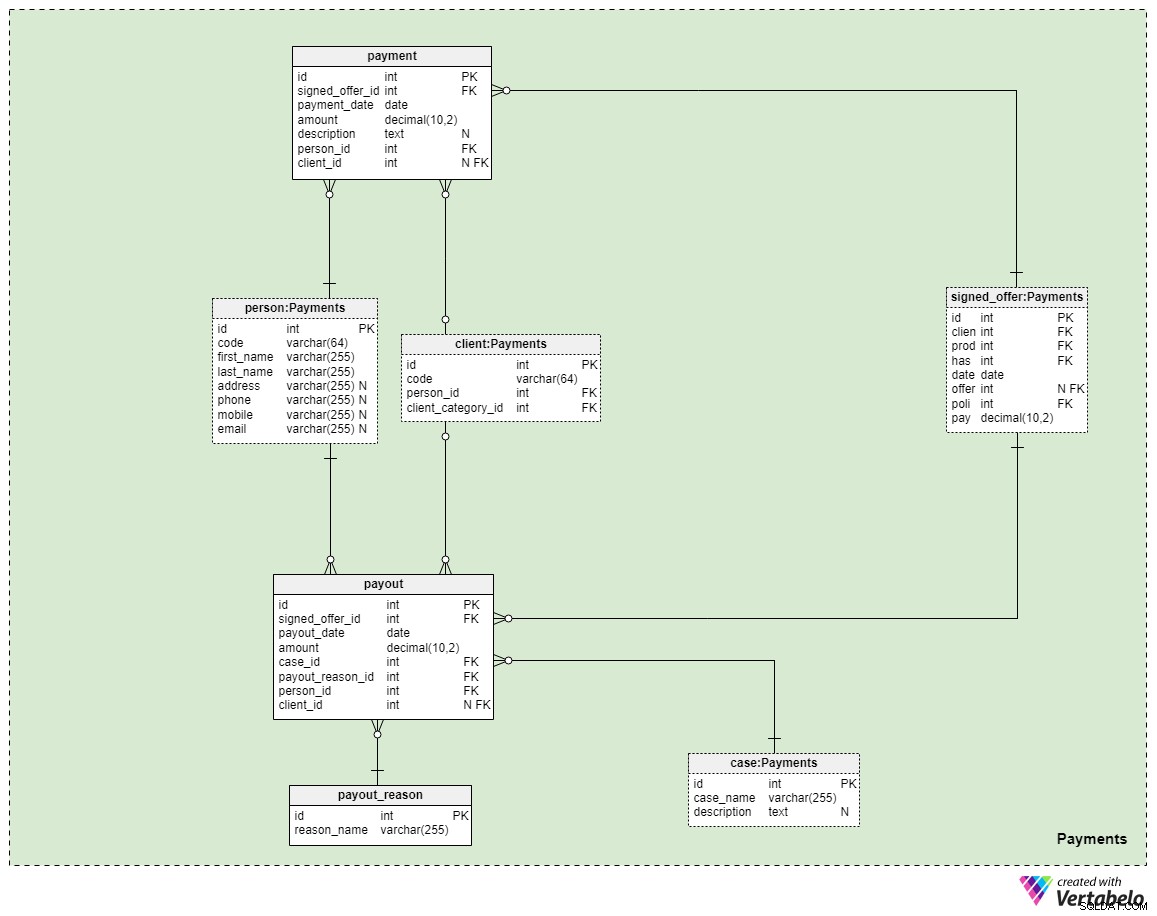
Poslední předmět v našem modelu se týká plateb. Zde představujeme pouze tři nové tabulky:payment , payout_reason a payout .
Všechny platby související se zásadami jsou uloženy v payment stůl. Zde jsme zahrnuli pouze nejdůležitější atributy:
signed_offer_id— odkaz na jedinečný identifikátor podepsané nabídky (zásady).payment_date— datum, kdy byla tato platba provedena.amount— skutečná částka, která byla zaplacena.description— volitelný popis platby v textovém formátu.person_id— odkaz na jedinečný identifikátor osoby, která platbu provedla. Všimněte si, že klient, který nabídku podepsal, nemusí být nutně jedinou osobou, která může provést platbu.client_id— odkaz na jedinečný identifikátor klienta, který provedl platbu. Tento atribut bude obsahovat hodnotu pouze v případě, že platbu provedl sám klient.
Zbývající dvě tabulky představují snad nejdůležitější důvod, proč si platíme životní pojištění — to, že v případě, že by se nám něco stalo, budou výplaty vyplaceny našim rodinným příslušníkům nebo životním/obchodním partnerům. Jak se to stane, vše závisí na vaší situaci a podmínkách konkrétních zásad, které jste podepsali. K pokrytí těchto případů použijeme dvě jednoduché tabulky.
První je slovník s názvem payout_reason a vyznačuje se klasickou slovníkovou strukturou. Kromě atributu primárního klíče máme pouze jeden atribut – reason_name – to bude uchovávat seznam jedinečných hodnot označujících, proč byla tato platba provedena.
Poslední tabulkou v modelu je payout stůl. Je to velmi podobné payment tabulka, ale nejdůležitější rozdíly jsou uvedeny níže:
payout_date— datum, kdy byla platba provedena.case_id— odkaz na jedinečný identifikátor souvisejícího případu nebo incidentu, který platbu spustil. Toto by mělo odpovídat jednomu z ID zahrnutých v zásadách.payout_reason_id— odkaz na slovník, který podrobněji popisuje důvod výplaty. I když je případ výplaty kratší a obecnější, důvod výplaty nabídne konkrétnější podrobnosti o tom, co se stalo.person_idaclient_id— odkazuje na osobu a klienta související s výplatou.
Shrnutí
Úžasný! Úspěšně jsme vybudovali datový model životního pojištění. Než zakončíme naši diskusi, stojí za zmínku, že v tomto modelu lze pokrýt mnohem více. V tomto článku jsme chtěli pokrýt především základy modelu, abyste měli představu, jak vypadá a funguje. Zde jsou některé další podrobnosti, které by bylo možné začlenit do takového datového modelu:
- Na další upgrady zásad se náš současný model nevztahuje (např. pokud chcete nabízet roční nabídky pro stávající zásady, s touto strukturou to nebudete moci provést). Měli bychom přidat několik dalších tabulek pro uložení všech změn zásad pro prezentované/podepsané nabídky.
- Veškeré papírování je záměrně vynecháno. S konkrétní životní pojistkou bude samozřejmě spojeno poměrně hodně papírování, zejména s procesem podpisu a výplatami. Mohli bychom přiložit dokumenty, které popisují stav klienta v době, kdy byla podepsána pojistka, a jakékoli změny, které se během této doby změnily, a také jakékoli dokumenty související s výplatami.
- Tento model nezahrnuje strukturu potřebnou pro výpočet politického rizika. Měli bychom mít všechny parametry, které potřebujeme otestovat, a jakékoli rozsahy, které určují, jak hodnota klienta ovlivní celkový výpočet. Výsledky těchto výpočtů by bylo nutné uložit pro každou nabídku a podepsané zásady.
- Struktura faktury je ve skutečnosti mnohem složitější než to, co jsme pokrývali v oblasti plateb. V našem modelu jsme nikde ani nezmiňovali finanční účty.
Je zřejmé, že pojišťovnictví je poměrně složité. V tomto článku jsme diskutovali pouze o datovém modelu pro životní pojištění – dokážete si představit, jak by se tento datový model vyvíjel, kdybychom provozovali společnost, která nabízí řadu různých typů pojištění? Představit organizovaný datový model pro takovou společnost by jistě vyžadovalo mnoho plánování a přemýšlení.
Máte-li nějaké návrhy nebo nápady na vylepšení našeho datového modelu, neváhejte nám je sdělit v komentářích níže!