Kevin Kline (@kekline) a já jsme nedávno uspořádali webový seminář o ladění dotazů (no, vlastně jeden ze série), a jednou z věcí, které se objevily, je tendence lidí vytvářet jakýkoli chybějící index, o kterém jim SQL Server řekne, že bude dobrá věc™ . O těchto chybějících indexech se mohou dozvědět z Database Engine Tuning Advisor (DTA), chybějící indexové DMV nebo plán provádění zobrazený v Management Studio nebo Plan Explorer (všechny pouze předávají informace přesně ze stejného místa):
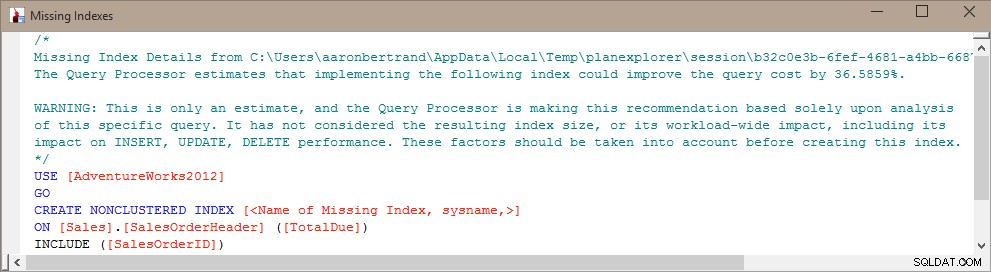
Problém s pouhým slepým vytvářením tohoto indexu je v tom, že SQL Server se rozhodl, že je užitečný pro konkrétní dotaz (nebo několik dotazů), ale zcela a jednostranně ignoruje zbytek zátěže. Jak všichni víme, indexy nejsou „zdarma“ – platíte za indexy jak v nezpracovaném úložišti, tak i za údržbu požadovanou při operacích DML. V pracovní zátěži náročné na zápis nedává smysl přidávat index, který pomáhá zefektivnit jeden dotaz, zvláště pokud tento dotaz není spouštěn často. V těchto případech může být velmi důležité porozumět vaší celkové pracovní zátěži a najít správnou rovnováhu mezi zefektivněním vašich dotazů a tím, že za to nebudete platit příliš mnoho z hlediska údržby indexu.
Takže jsem měl nápad „namíchat“ informace z chybějících indexových DMV, statistik využití indexu DMV a informací o plánech dotazů, abych určil, jaký typ zůstatku aktuálně existuje a jak by přidání indexu mohlo celkově fungovat.
Chybějící indexy
Nejprve se můžeme podívat na chybějící indexy, které SQL Server aktuálně navrhuje:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
To ukazuje tabulky a sloupce, které by byly užitečné v indexu, kolik kompilací/hledání/skenování by bylo použito a kdy k poslední takové události došlo u každého potenciálního indexu. Můžete také zahrnout sloupce jako s.avg_total_user_cost a s.avg_user_impact pokud chcete tato čísla použít k upřednostnění.
Plánovat operace
Dále se podívejme na operace používané ve všech plánech, které jsme uložili do mezipaměti s objekty, které byly identifikovány našimi chybějícími indexy.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Kamarád na dba.SE, Mikael Eriksson, navrhl následující dva dotazy, které na větším systému budou fungovat mnohem lépe než dotaz XML / UNION, který jsem sestavil výše, takže s těmi můžete experimentovat jako první. Jeho závěrečná poznámka byla, že "nepřekvapivě zjistil, že méně XML je dobrá věc pro výkon. :)" Opravdu.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Nyní v #planops tabulka, máte spoustu hodnot pro plan_handle takže můžete jít a prozkoumat každý z jednotlivých plánů ve hře proti objektům, které byly identifikovány jako postrádající nějaký užitečný index. Momentálně to k tomu nepoužijeme, ale můžete to snadno odkázat pomocí:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Nyní můžete kliknout na kterýkoli z výstupních plánů a zjistit, co aktuálně dělají s vašimi objekty. Všimněte si, že některé plány se budou opakovat, protože plán může mít více operátorů, kteří odkazují na různé indexy ve stejné tabulce.
Statistiky využití indexu
Dále se podívejme na statistiky využití indexu, abychom viděli, kolik skutečné aktivity aktuálně běží proti našim kandidátským tabulkám (a zejména aktualizacím).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Neznepokojujte se, pokud velmi málo nebo žádné plány v mezipaměti zobrazují aktualizace pro konkrétní index, přestože statistiky využití indexu ukazují, že tyto indexy byly aktualizovány. To jen znamená, že plány aktualizací nejsou aktuálně uloženy v mezipaměti, což může být z různých důvodů – například to může být velmi náročné na čtení a jsou zastaralé nebo jsou všechny jedno- používat a optimize for ad hoc workloads je povoleno.
Dáme vše dohromady
Následující dotaz vám pro každý navrhovaný chybějící index ukáže počet čtení, kterým mohl index pomoci, počet zápisů a čtení, která byla aktuálně zachycena oproti existujícím indexům, jejich poměr, počet plánů souvisejících s tento objekt a celkový počet použití se počítá pro tyto plány:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Pokud je váš poměr zápisu a čtení k těmto indexům již> 1 (nebo> 10!), myslím, že to dává důvod k pauze před slepým vytvořením indexu, který by mohl tento poměr pouze zvýšit. Počet potential_read_ops zobrazeno, to však může kompenzovat, když se číslo zvětší. Pokud potential_read_ops číslo je velmi malé, pravděpodobně budete chtít doporučení zcela ignorovat, než se vůbec obtěžujete prozkoumat další metriky – můžete tedy přidat WHERE klauzule k odfiltrování některých z těchto doporučení.
Pár poznámek:
- Jedná se o operace čtení a zápisu, nikoli jednotlivě měřená čtení a zápisy 8K stránek.
- Poměr a srovnání jsou z velké části vzdělávací; velmi dobře se mohlo stát, že 10 000 000 operací zápisu ovlivnilo jeden řádek, zatímco 10 operací čtení mohlo mít podstatně větší dopad. To je myšleno pouze jako hrubé vodítko a předpokládá, že operace čtení a zápisu mají zhruba stejnou váhu.
- Můžete také použít drobné variace na některé z těchto dotazů, abyste zjistili – kromě chybějících indexů, které SQL Server doporučuje –, kolik vašich aktuálních indexů je plýtvavých. Na internetu je o tom spousta nápadů, včetně tohoto příspěvku od Paula Randala (@PaulRandal).
Doufám, že to poskytne několik nápadů, jak získat lepší přehled o chování vašeho systému, než se rozhodnete přidat index, který vám nějaký nástroj řekl, abyste vytvořili. Mohl jsem to vytvořit jako jeden masivní dotaz, ale myslím, že jednotlivé části vám poskytnou nějaké králičí nory k prozkoumání, pokud si to přejete.
Další poznámky
Můžete to také rozšířit, abyste zachytili aktuální metriky velikosti, šířku tabulky a počet aktuálních řádků (a také jakékoli předpovědi budoucího růstu); to vám může poskytnout dobrou představu o tom, kolik místa nový index zabere, což může být problém v závislosti na vašem prostředí. Možná se tomu budu věnovat v budoucím příspěvku.
Samozřejmě musíte mít na paměti, že tyto metriky jsou užitečné pouze do té míry, do jaké vám diktuje dostupnost. DMV se vymažou po restartu (a někdy i v jiných, méně rušivých scénářích), takže pokud si myslíte, že tyto informace budou užitečné po delší dobu, můžete zvážit pořizování pravidelných snímků.