Tento článek je třetí částí série o složitosti NULL. V části 1 jsem popsal význam značky NULL a jak se chová při srovnání. V části 2 jsem popsal nekonzistence zacházení s NULL v různých jazykových prvcích. Tento měsíc popíšu výkonné standardní funkce pro zpracování NULL, které se teprve dostaly do T-SQL, a zástupná řešení, která lidé v současné době používají.
Pokračuji v používání ukázkové databáze TSQLV5 jako minulý měsíc v některých mých příkladech. Skript, který vytváří a naplňuje tuto databázi, najdete zde a její ER diagram zde.
DISTINCT predikát
V 1. části seriálu jsem vysvětlil, jak se NULL chovají při porovnávání a složitosti kolem trojhodnotové predikátové logiky, kterou SQL a T-SQL používají. Zvažte následující predikát:
X =YPokud je některý predikand NULL – včetně případů, kdy jsou oba NULL – výsledkem tohoto predikátu je logická hodnota UNKNOWN. S výjimkou operátorů IS NULL a IS NOT NULL platí totéž pro všechny ostatní operátory, včetně jiných než (<>):
X <> YV praxi často chcete, aby se hodnoty NULL pro účely srovnání chovaly stejně jako hodnoty jiné než hodnoty NULL. To platí zejména v případě, kdy je použijete k označení chybějící, ale nepoužitelné hodnoty. Norma má pro tuto potřebu řešení ve formě vlastnosti zvané DISTINCT predikát, která používá následující tvar:
Namísto použití sémantiky rovnosti nebo nerovnosti používá tento predikát při porovnávání predikandů sémantiku založenou na odlišnosti. Jako alternativu k operátoru rovnosti (=) byste použili následující formulář k získání PRAVDA, když jsou dva predikandy stejné, včetně případů, kdy jsou oba NULL, a NEPRAVDA, pokud nejsou, včetně případů, kdy je jeden NULL a jiný není:
X NENÍ ODLIŠNÉ OD YJako alternativa k jinému než operátor (<>), použijete následující formulář k získání TRUE, když se dva predikandy liší, včetně toho, když jeden je NULL a druhý ne, a FALSE, když jsou stejné, včetně toho, když jsou oba NULL:
X SE LIŠÍ OD YAplikujme predikát DISTINCT na příklady, které jsme použili v 1. části série. Připomeňme, že jste potřebovali napsat dotaz, který daný vstupním parametrem @dt vrátí objednávky, které byly odeslány k datu vstupu, pokud není NULL, nebo které nebyly odeslány vůbec, pokud je vstup NULL. Podle standardu byste ke zpracování této potřeby použili následující kód s predikátem DISTINCT:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate NENÍ ODLIŠTĚNÉ OD @dt;
Prozatím si připomeňme z části 1, že můžete použít kombinaci predikátu EXISTS a operátoru INTERSECT jako SARGable řešení v T-SQL, například takto:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Chcete-li vrátit objednávky, které byly odeslány v jiné datum než (odlišné od) vstupní datum @dt, použijte následující dotaz:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate IS DISTINECT OD @dt;
Řešení, které funguje v T-SQL, používá kombinaci predikátu EXISTS a operátoru EXCEPT, například takto:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
V části 1 jsem také probíral scénáře, kdy potřebujete spojit tabulky a použít sémantiku založenou na odlišnosti v predikátu spojení. V mých příkladech jsem použil tabulky nazvané T1 a T2, se sloupci spojení s možností NULL nazvanými k1, k2 a k3 na obou stranách. Podle standardu byste ke zpracování takového spojení použili následující kód:
VYBERTE T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1INNER JOIN dbo.T2 NA T1.k1 NENÍ ODLIŠNÁ OD T2.k1 A T1.k2 NENÍ ODLIŠNÁ OD T2 .k2 A T1.k3 SE NEODLIŠUJE OD T2.k3;
Pro tuto chvíli, podobně jako v předchozích úlohách filtrování, můžete použít kombinaci predikátu EXISTS a operátoru INTERSECT v klauzuli ON spojení k emulaci odlišného predikátu v T-SQL, například takto:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1 , T2.k2, T2.k3);
Při použití ve filtru je tento formulář SARGable a při použití ve spojení se tento formulář může potenciálně spoléhat na pořadí indexu.
Pokud byste chtěli vidět DISTINCT predikát přidaný do T-SQL, můžete pro něj hlasovat zde.
Pokud se po přečtení této části stále cítíte trochu nesví ohledně predikátu DISTINCT, nejste sami. Možná je tento predikát mnohem lepší než jakékoli stávající řešení, které v současnosti máme v T-SQL, ale je trochu podrobný a trochu matoucí. Využívá negativní formu k uplatnění toho, co v našich myslích představuje pozitivní srovnání, a naopak. Nikdo neřekl, že všechny standardní návrhy jsou dokonalé. Jak Charlie poznamenal v jednom ze svých komentářů k 1. části, lépe by fungovala následující zjednodušená forma:
Je to stručné a mnohem intuitivnější. Místo X IS NOT DISTINCT FROM Y byste použili:
X JE YA místo X IS DISTINCT FROM Y byste použili:
X NENÍ YTento navrhovaný operátor je ve skutečnosti sladěn s již existujícími operátory IS NULL a IS NOT NULL.
Aplikováno na naši úlohu dotazu, k vrácení objednávek, které byly odeslány ve vstupní datum (nebo které nebyly odeslány, pokud je vstup NULL), byste použili následující kód:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate IS @dt;
Chcete-li vrátit objednávky, které byly odeslány v jiné datum, než je zadané datum, použijte následující kód:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate NENÍ @dt;
Pokud se Microsoft někdy rozhodne přidat odlišný predikát, bylo by dobré, kdyby podporoval jak standardní verbózní formu, tak tuto nestandardní, ale stručnější a intuitivnější formu. Je zajímavé, že procesor dotazů SQL Server již podporuje interní porovnávací operátor IS, který používá stejnou sémantiku jako požadovaný operátor IS, který jsem zde popsal. Podrobnosti o tomto operátorovi najdete v článku Paula Whitea Undocumented Query Plans:Equality Comparisons (vyhledání „IS místo EQ“). Co chybí, je vystavit jej externě jako součást T-SQL.
Klauzule zacházení s NULL (ignorovat NULLS | RESPECT NULLS)
Při použití funkcí offsetového okna LAG, LEAD, FIRST_VALUE a LAST_VALUE někdy potřebujete ovládat chování ošetření NULL. Ve výchozím nastavení tyto funkce vracejí výsledek požadovaného výrazu na požadované pozici, bez ohledu na to, zda je výsledkem výrazu skutečná hodnota nebo NULL. Někdy však chcete pokračovat v pohybu příslušným směrem (zpět pro LAG a LAST_VALUE, dopředu pro LEAD a FIRST_VALUE) a vrátit první hodnotu, která není NULL, pokud je přítomna, a jinak NULL. Standard vám dává kontrolu nad tímto chováním pomocí klauzule ošetření NULL s následující syntaxí:
offset_function(Výchozí v případě, že klauzule ošetření NULL není specifikována, je možnost RESPECT NULLS, což znamená vrátit vše, co je na požadované pozici přítomno, i když je NULL. Bohužel tato klauzule zatím není v T-SQL dostupná. Poskytnu příklady standardní syntaxe pomocí funkcí LAG a FIRST_VALUE a také zástupná řešení, která fungují v T-SQL. Podobné techniky můžete použít, pokud takovou funkcionalitu potřebujete s LEAD a LAST_VALUE.
Jako ukázková data použiji tabulku s názvem T4, kterou vytvoříte a naplníte pomocí následujícího kódu:
DROP TABLE IF EXISTS dbo.T4;GO CREATE TABLE dbo.T4( id INT NOT NULL CONSTRAINT PK_T4 PRIMÁRNÍ KLÍČ, col1 INT NULL); INSERT INTO dbo.T4(id, col1) VALUES( 2, NULL),( 3, 10),( 5, -1),( 7, NULL),(11, NULL),(13, -12),( 17, NULL),(19, NULL),(23, 1759);
Běžným úkolem je vrátit poslední relevantní hodnota. Hodnota NULL v col1 označuje žádnou změnu hodnoty, zatímco hodnota bez hodnoty NULL označuje novou relevantní hodnotu. Musíte vrátit poslední hodnotu col1, která není NULL, na základě řazení ID. Pomocí standardní léčebné klauzule NULL byste úlohu zvládli takto:
SELECT id, col1,COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastvalFROM dbo.T4;
Zde je očekávaný výstup z tohoto dotazu:
id col1 lastval----------- ----------- -----------2 NULL NULL3 10 105 -1 -17 NULL - 111 NULL -113 -12 -1217 NULL -1219 NULL -1223 1759 1759
V T-SQL existuje řešení, ale zahrnuje dvě vrstvy okenních funkcí a tabulkový výraz.
V prvním kroku použijete funkci okna MAX k výpočtu sloupce nazvaného grp, který má zatím maximální hodnotu id, když col1 není NULL, například takto:
VYBERTE id, col1,MAX(PŘÍPAD, KDYŽ col1 NENÍ NULL THEN id END) OVER (POŘADÍ PODLE id ŘÁDKŮ BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) AS grpFROM dbo.T4;
Tento kód generuje následující výstup:
id col1 grp----------- ----------- -----------2 NULL NULL3 10 35 -1 57 NULL 511 NULL 513 -12 1317 NULL 1319 NULL 1323 1759 23
Jak můžete vidět, jedinečná hodnota grp se vytvoří vždy, když dojde ke změně hodnoty col1.
Ve druhém kroku definujete CTE na základě dotazu z prvního kroku. Poté ve vnějším dotazu vrátíte dosud maximální hodnotu col1 v rámci každého oddílu definovaného pomocí grp. To je poslední hodnota col1, která nemá NULL. Zde je úplný kód řešení:
WITH C AS(SELECT id, col1, MAX(CASE, KDYŽ col1 NENÍ NULL THEN id END) OVER (POŘADÍ PODLE id ŘÁDKŮ BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) AS grpFROM dbo.T4)SELECT id, col1,MAX(col1) OVER( ROZDĚLENÍ PODLE grp OBJEDNÁVKA PODLE ID ŘÁDKŮ BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) AS lastvalFROM C;
Je zřejmé, že je to mnohem více kódu a práce ve srovnání s pouhým vyslovením IGNORE_NULLS.
Další běžnou potřebou je vrátit první relevantní hodnotu. V našem případě předpokládejme, že potřebujete vrátit první hodnotu col1, která není NULL, zatím na základě řazení id. Pomocí standardní klauzule ošetření NULL byste úlohu zpracovali pomocí funkce FIRST_VALUE a možnosti IGNOROVAT NULLS takto:
VYBRAT id, col1,FIRST_VALUE(col1) IGNOROVAT NULOVÉ PŘEDCHOZÍ (POŘADÍ PODLE ŘÁDKŮ ID BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) JAKO firstvalFROM dbo.T4;
Zde je očekávaný výstup z tohoto dotazu:
id col1 firstval----------- ----------- -----------2 NULL NULL3 10 105 -1 107 NULL 1011 NULL 1013 -12 1017 NULL 1019 NULL 1023 1759 10
Řešení v T-SQL používá podobnou techniku, jaká se používá pro poslední hodnotu, která není NULL, pouze místo přístupu double-MAX použijete funkci FIRST_VALUE nad funkcí MIN.
V prvním kroku použijete funkci okna MIN k výpočtu sloupce nazvaného grp, který má zatím minimální hodnotu id, když col1 není NULL, například takto:
VYBERTE id, col1,MIN(PŘÍPAD, KDYŽ sloupec1 NENÍ NULL THEN id END) OVER (POŘADÍ PODLE ŘÁDKŮ id BEZ OMEZENÍ PŘEDCHOZÍM) JAKO grpFROM dbo.T4;
Tento kód generuje následující výstup:
id col1 grp----------- ----------- -----------2 NULL NULL3 10 35 -1 37 NULL 311 NULL 313 -12 317 NULL 319 NULL 323 1759 3
Pokud před první relevantní hodnotou existují nějaké hodnoty NULL, skončíte se dvěma skupinami – první s NULL jako hodnotou grp a druhá s prvním nenulovým id jako hodnotou grp.
Ve druhém kroku umístíte kód prvního kroku do tabulkového výrazu. Poté ve vnějším dotazu použijete funkci FIRST_VALUE, rozdělenou podle grp, ke shromáždění první relevantní hodnoty (jiné než NULL), pokud existuje, a v opačném případě NULL, například takto:
WITH C AS(SELECT id, col1, MIN(CASE WHEN col1 NENÍ NULL THEN id END) OVER(ORDER BY id ŘÁDKŮ BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) AS grpFROM dbo.T4)SELECT id, col1,FIRST_VALUE(col1) OVER( ROZDĚLENÍ PODLE grp POŘADÍ PODLE id ŘÁDKŮ BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) AS firstvalFROM C;
Opět je to hodně kódu a práce ve srovnání s jednoduchým použitím možnosti IGNORE_NULLS.
Pokud máte pocit, že tato funkce může být pro vás užitečná, můžete zde hlasovat pro její zařazení do T-SQL.
PRVNÍ OBJEDNÁVKA PODLE NULL | NULOVÉ POSLEDNÍ
Když si objednáváte data, ať už pro účely prezentace, okna, filtrování TOP/OFFSET-FETCH nebo pro jakýkoli jiný účel, vyvstává otázka, jak by se v tomto kontextu měly chovat hodnoty NULL? Standard SQL říká, že hodnoty NULL by se měly třídit společně buď před nebo po jiných než NULL, a ponechávají na implementaci, aby určila jeden nebo druhý způsob. Ať už si však prodejce vybere cokoliv, musí být konzistentní. V T-SQL jsou při použití vzestupného pořadí nejprve seřazeny hodnoty NULL (před nenulovými hodnotami). Jako příklad zvažte následující dotaz:
SELECT orderid, shippeddateFROM Sales.OrdersORDER BY shippeddate, orderid;
Tento dotaz generuje následující výstup:
objednací datum odeslání----------- -----------11008 NULL11019 NULL11039 NULL...10249 2017-07-1010252 2017-07-1110-0250 2017 ...11063 2019-05-0611067 2019-05-0611069 2019-05-06
Výstup ukazuje, že neodeslané objednávky, které mají NULL datum odeslání, se objednají před odeslanými objednávkami, které mají existující platné datum odeslání.
Ale co když potřebujete NULL, aby se při použití vzestupného pořadí objednávaly jako poslední? Standard ISO/IEC SQL podporuje klauzuli, kterou použijete na objednávkový výraz určující, zda se hodnoty NULL řadí první nebo poslední. Syntaxe této klauzule je:
Abychom vyřídili naši potřebu, vracení objednávek seřazených podle data odeslání, vzestupně, ale s neodeslanými objednávkami vrácenými jako poslední, a poté podle jejich ID objednávek jako nerozhodný výsledek, byste použili následující kód:
SELECT orderid, shippeddateFROM Sales.OrdersORDER BY shippeddate NULLS LAST, orderid;
Bohužel tato klauzule pro objednání NULLS není v T-SQL dostupná.
Běžným řešením, které lidé používají v T-SQL, je předřazení objednávkového výrazu výrazu CASE, který vrací konstantu s nižší objednávkovou hodnotou pro jiné než NULL hodnoty než pro NULL, jako je to (toto řešení budeme nazývat Dotaz 1):
SELECT orderid, shippeddateFROM Sales.OrdersORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Tento dotaz generuje požadovaný výstup s hodnotami NULL zobrazenými jako poslední:
V tabulce Sales.Orders je definován krycí index, jehož klíčem je sloupec shippeddate. Avšak podobně jako sloupec manipulovaného filtrování brání SARGability filtru a možnosti použít vyhledávací index, sloupec manipulovaného řazení brání možnosti spoléhat se na řazení indexu pro podporu klauzule ORDER BY dotazu. Proto SQL Server vygeneruje plán pro dotaz 1 s explicitním operátorem řazení, jak je znázorněno na obrázku 1.
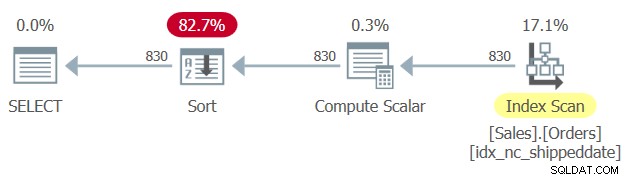 Obrázek 1:Plán pro dotaz 1
Obrázek 1:Plán pro dotaz 1
Někdy není velikost dat tak velká, aby bylo explicitní řazení problémem. Ale někdy to tak je. S explicitním řazením se škálovatelnost dotazu stává extralineární (čím více řádků máte, platíte více za řádek) a doba odezvy (doba, za kterou je vrácen první řádek) je zpožděna.
Existuje trik, který můžete použít, abyste se v takovém případě vyhnuli explicitnímu řazení s řešením, které je optimalizováno pomocí operátoru Merge Join Concatenation zachovávajícího pořadí. Podrobné pokrytí této techniky používané v různých scénářích naleznete v SQL Server:Vyhýbání se řazení pomocí sloučení spojení spojení. První krok v řešení sjednocuje výsledky dvou dotazů:jeden dotaz vrací řádky, kde sloupec řazení není NULL, se sloupcem výsledků (budeme to nazývat sortcol) na základě konstanty s nějakou hodnotou řazení, řekněme 0, a další dotaz vrací řádky s hodnotami NULL, s sortcol nastaveným na konstantu s vyšší hodnotou řazení než v prvním dotazu, řekněme 1. Ve druhém kroku pak definujete tabulkový výraz založený na kódu z prvního kroku a poté ve vnějším dotazu řadíte řádky z tabulkového výrazu nejprve podle sortcol a poté podle zbývajících prvků řazení. Zde je kompletní kód řešení implementující tuto techniku (toto řešení budeme nazývat Dotaz 2):
WITH C AS(SELECT orderid, shippeddate, 0 AS sortcolFROM Sales.OrdersWHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcolFROM Sales.OrdersWHERE shippeddate IS NULL)SELECT orderid, shippeddateFROM CORDER BY sortcol, shippeddate, order;
Plán pro tento dotaz je znázorněn na obrázku 2.
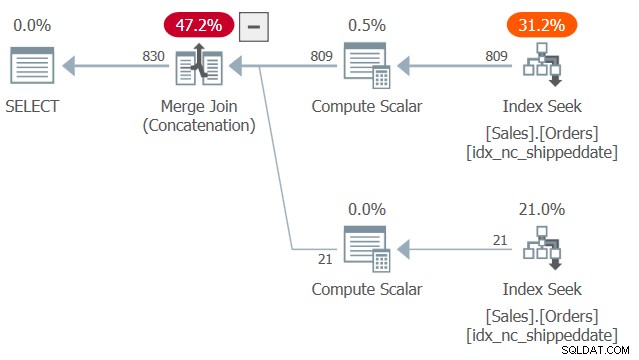 Obrázek 2:Plán pro dotaz 2
Obrázek 2:Plán pro dotaz 2
Všimněte si dvou hledání a prohledávání uspořádaných rozsahů v krycím indexu idx_nc_shippeddate – jedno stahuje řádky, kde shippeddateis není NULL, a druhé vytahuje řádky, kde shippeddate je NULL. Poté, podobně jako ve spojení funguje algoritmus Merge Join, algoritmus Merge Join (Concatenation) sjednotí řádky ze dvou uspořádaných stran způsobem podobným zipu a zachová zpracované pořadí, aby podpořil potřeby uspořádání prezentací dotazu. Neříkám, že tato technika je vždy rychlejší než typičtější řešení s výrazem CASE, který využívá explicitní řazení. První má však lineární škálování a druhý má n log n škálování. Takže první bude mít tendenci pracovat lépe s velkým počtem řádků a druhý s malým počtem.
Je zřejmé, že je dobré mít řešení pro tuto běžnou potřebu, ale bude mnohem lepší, když T-SQL v budoucnu přidá podporu pro standardní klauzuli o uspořádání NULL.
Závěr
Standard ISO/IEC SQL má poměrně hodně funkcí pro zpracování NULL, které se do T-SQL teprve dostaly. V tomto článku jsem se zabýval některými z nich:predikátem DISTINCT, léčebnou klauzulí NULL a řízením toho, zda se hodnoty NULL řadí první nebo poslední. Poskytl jsem také řešení pro tyto funkce, které jsou podporovány v T-SQL, ale jsou zjevně těžkopádné. Příští měsíc pokračuji v diskusi popisem standardního jedinečného omezení, jak se liší od implementace T-SQL a řešení, která lze implementovat v T-SQL.