[ Část 1 | Část 2 | Část 3 ]
V části 1 této série jsem vyzkoušel několik způsobů, jak komprimovat 1TB tabulku. I když jsem ve svém prvním pokusu dosáhl slušných výsledků, chtěl jsem zjistit, zda bych mohl zlepšit výkon v části 2. Tam jsem nastínil několik věcí, o kterých jsem si myslel, že by mohly být problémy s výkonem, a nastínil, jak bych mohl lépe rozdělit cílovou tabulku. pro optimální kompresi columnstore. Už jsem:
- rozdělili tabulku na 8 oddílů (jeden na jádro);
- umístit datový soubor každého oddílu do vlastní skupiny souborů; a,
- nastavit kompresi archivu na všech oddílech kromě "aktivního".
Ještě to musím udělat tak, aby každý plánovač zapisoval výhradně na svůj vlastní oddíl.
Nejprve musím provést změny v tabulce dávek, kterou jsem vytvořil. Potřebuji sloupec pro uložení počtu řádků přidaných na dávku (druh samoauditní kontroly zdravého rozumu) a počáteční/koncové časy pro měření pokroku.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Dále musím vytvořit tabulku, která zajistí afinitu – nikdy nechceme, aby na libovolném plánovači běžel více než jeden proces, i když to znamená ztrátu času na opakování logiky. Potřebujeme tedy tabulku, která bude sledovat jakoukoli relaci na konkrétním plánovači a zabrání skládání:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Myšlenka je taková, že bych měl osm instancí aplikace (SQLQueryStress), z nichž každá by běžela na vyhrazeném plánovači a zpracovávala pouze data určená pro konkrétní oddíl / skupinu souborů / datový soubor, ~ 100 milionů řádků najednou (kliknutím zvětšíte) :
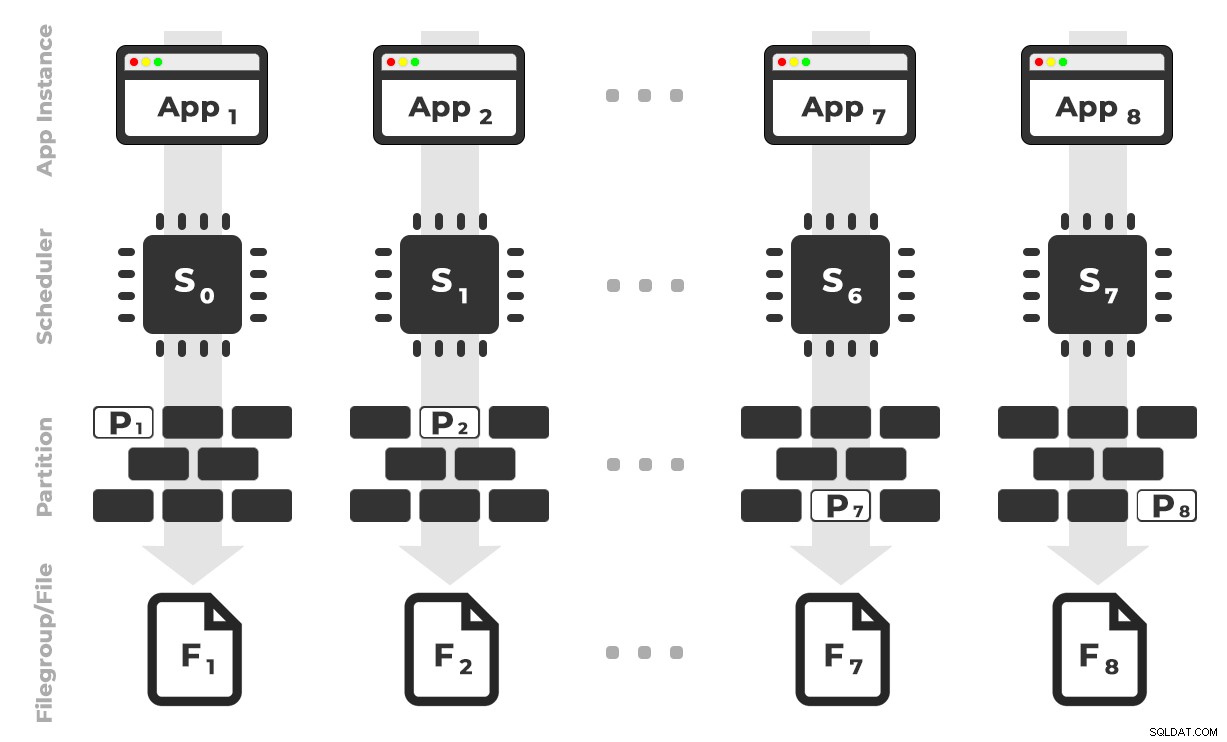 Aplikace 1 získá plánovač 0 a zapíše do oddílu 1 ve skupině souborů 1 a tak dále …
Aplikace 1 získá plánovač 0 a zapíše do oddílu 1 ve skupině souborů 1 a tak dále …
Dále potřebujeme uloženou proceduru, která umožní každé instanci aplikace rezervovat čas na jediném plánovači. Jak jsem zmínil v předchozím příspěvku, není to můj původní nápad (a nikdy bych ho v tom průvodci nenašel, nebýt Joea Obbishe). Zde je postup, který jsem vytvořil v Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Jednoduché, že? Spusťte 8 instancí SQLQueryStress a vložte tuto dávku do každé:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
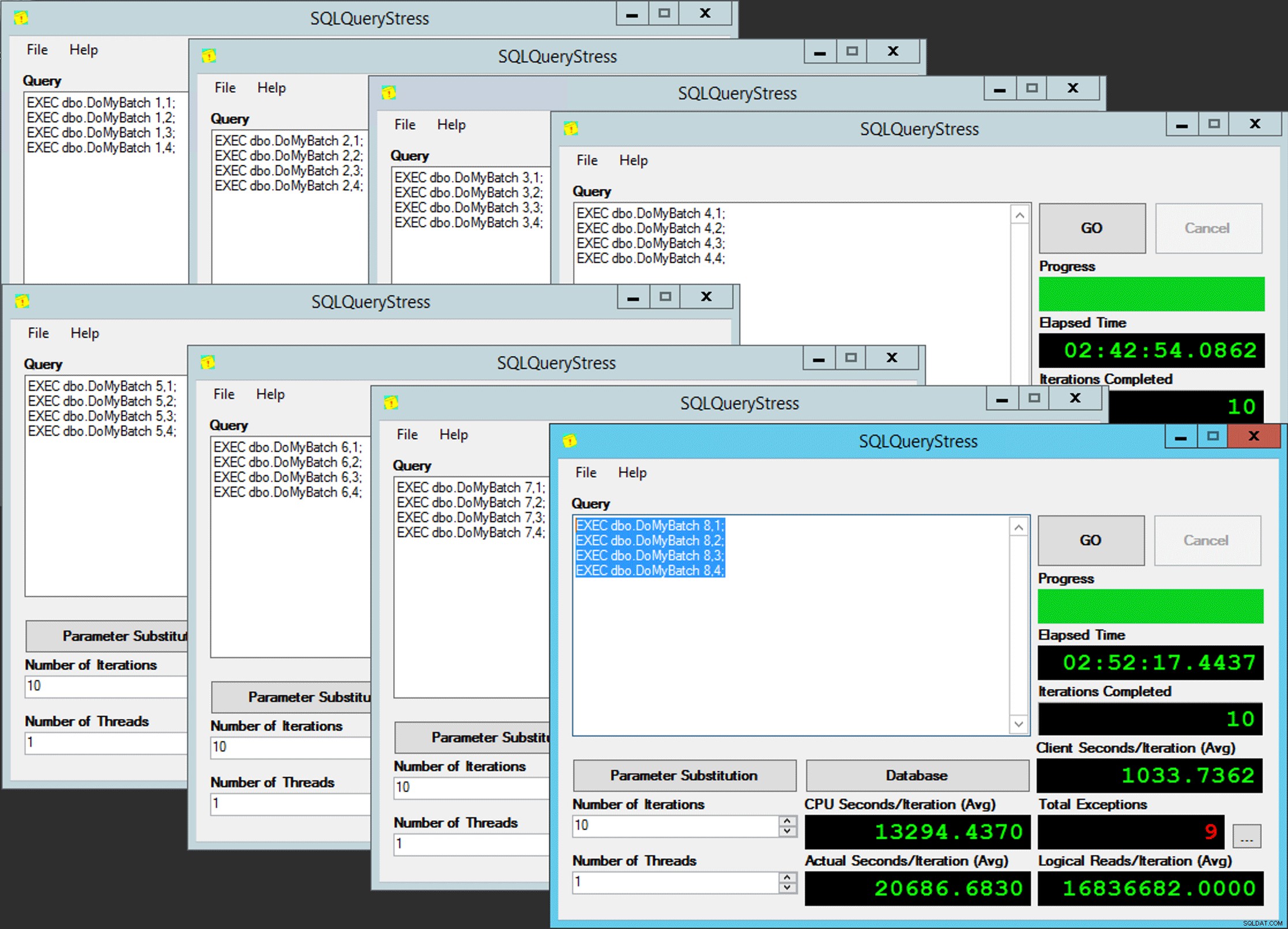 Paralelismus chudáka
Paralelismus chudáka
Až na to, že to není tak jednoduché, protože přiřazení plánovače je něco jako bonboniéra. Trvalo mnoho pokusů, než se každá instance aplikace dostala do očekávaného plánovače; Zkontroloval bych výjimky v jakékoli dané instanci aplikace a změnil bych PartitionID shodovat se. To je důvod, proč jsem použil více než jednu iteraci (ale stále jsem chtěl pouze jedno vlákno na instanci). Například tato instance aplikace očekávala, že bude na plánovači 3, ale dostala plánovač 4:
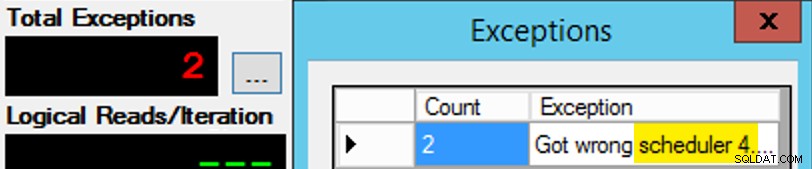 Pokud napoprvé neuspějete...
Pokud napoprvé neuspějete...
Změnil jsem 3s v okně dotazu na 4s a zkusil jsem to znovu. Kdybych byl rychlý, úkol plánovače byl dostatečně „lepkavý“ na to, aby ho hned zvedl a začal odjíždět. Ale nebyl jsem vždy dost rychlý, takže to bylo něco jako rána do krtka. Pravděpodobně jsem mohl vymyslet lepší rutinu opakování/zacyklení, aby byla práce méně manuální, a zkrátit zpoždění, abych okamžitě věděl, zda to funguje nebo ne, ale pro mé potřeby to bylo dost dobré. Také to umožnilo neúmyslné posunutí časů zahájení pro každý proces, což je další rada od pana Obbishe.
Monitorování
Zatímco je spřízněná kopie spuštěna, mohu získat nápovědu o aktuálním stavu pomocí následujících dvou dotazů:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Pokud jsem udělal vše správně, oba dotazy by vrátily 8 řádků a zobrazily by rostoucí logická čtení a trvání. Typy čekání se budou přepínat mezi PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD a příležitostně RESERVED_MEMORY_ALLOCATION_EXT. Když byla dávka dokončena (mohu je zkontrolovat zrušením komentáře -- AND EndTime IS NULL , Potvrdil bych, že RowsAdded = RowsInRange .
Jakmile bylo dokončeno všech 8 instancí SQLQueryStress, mohl jsem pouze provést SELECT INTO <newtable> FROM dbo.BatchQueue zaznamenat konečné výsledky pro pozdější analýzu.
Další testování
Kromě zkopírování dat do již existujícího rozděleného klastrovaného indexu columnstore pomocí afinity jsem chtěl vyzkoušet také několik dalších věcí:
- Kopírování dat do nové tabulky bez pokusu řídit spřažení. Z postupu jsem vyloučil afinitní logiku a celou věc „doufám-dostaneš-správný-plánovač“ jsem nechal náhodě. Trvalo to déle, protože skládání plánovače proběhlo nastat. Například v tomto konkrétním okamžiku plánovač 3 spouštěl dva procesy, zatímco plánovač 0 měl přestávku na oběd:
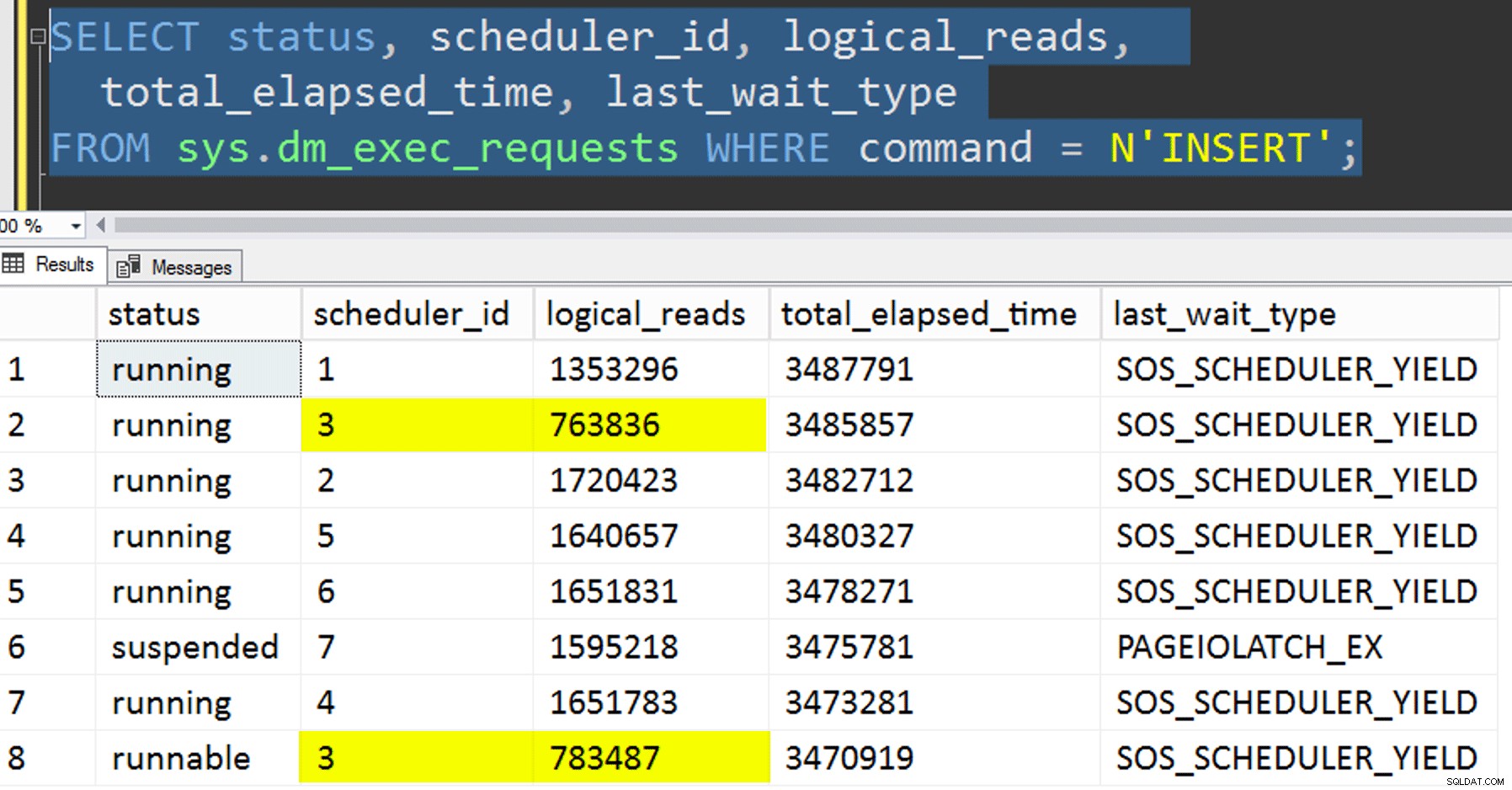 Kde jsi, plánovač číslo 0?
Kde jsi, plánovač číslo 0? - Použití stránky nebo řádek komprese (online i offline) do zdroje před afinitní kopii (offline), abyste zjistili, zda by komprimace dat jako první mohla urychlit cíl. Všimněte si, že kopírování lze provést také online, ale jako
intAndyho Mallona nabigintkonverze, vyžaduje to trochu gymnastiky. Všimněte si, že v tomto případě nemůžeme využít afinitu CPU (ačkoli bychom mohli, pokud by zdrojová tabulka již byla rozdělena). Byl jsem chytrý a vzal jsem zálohu původního zdroje a vytvořil postup pro vrácení databáze zpět do původního stavu. Mnohem rychlejší a jednodušší, než se pokoušet ručně vrátit do určitého stavu.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- A nakonec nejprve přebudujte seskupený index na schéma oddílů a poté na něj vytvořte index seskupeného sloupcového úložiště. Nevýhodou posledně jmenovaného je, že v SQL Server 2017 to nemůžete spustit online... ale budete to moci v roce 2019.
Zde musíme nejprve zrušit omezení PK; nemůžete použít
Msg 1907, Level 16, State 1DROP_EXISTING, protože původní jedinečné omezení nemůže být vynuceno seskupeným indexem columnstore a nemůžete nahradit jedinečný seskupený index nejedinečným seskupeným indexem.
Nelze znovu vytvořit index 'pk_tblOriginal'. Nová definice indexu neodpovídá omezení vynucovanému existujícím indexem.Všechny tyto podrobnosti dělají z tohoto procesu tříkrokový, pouze druhý krok online. První krok jsem výslovně testoval pouze
OFFLINE; který běžel za tři minuty, zatímcoONLINEPo 15 minutách jsem přestal. Jedna z věcí, která by možná ani v jednom případě neměla být operace velikosti dat, ale to si nechám na jindy.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Výsledky
Časování a kompresní poměry:
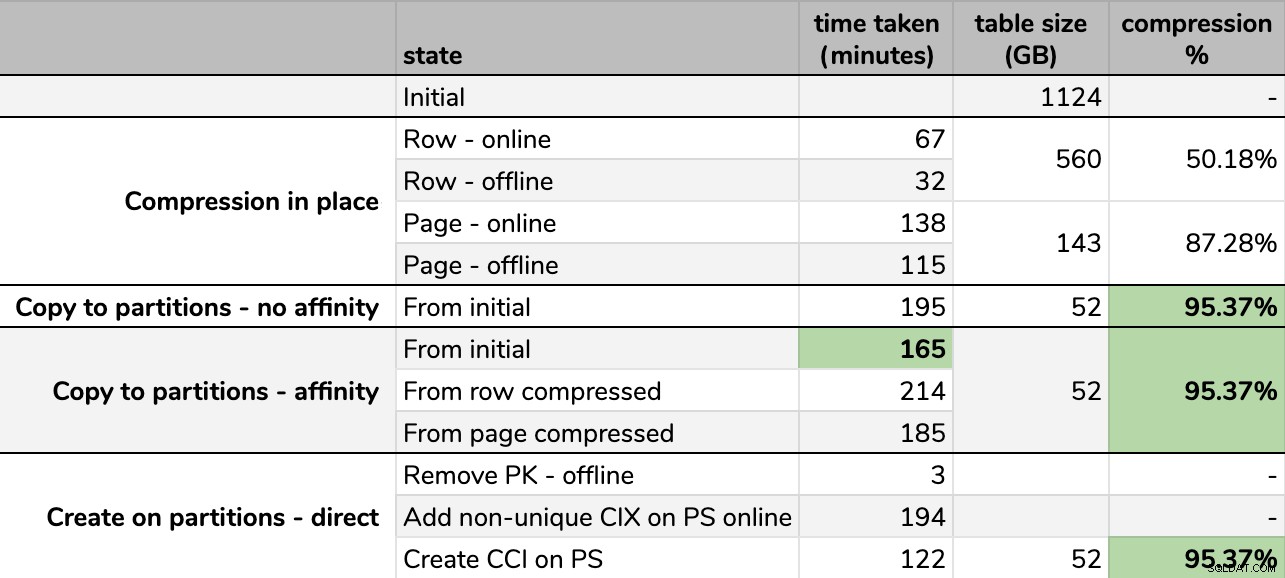 Některé možnosti jsou lepší než jiné
Některé možnosti jsou lepší než jiné
Všimněte si, že jsem zaokrouhlil na GB, protože by po každém spuštění byly malé rozdíly ve finální velikosti, a to i při použití stejné techniky. Také načasování pro afinitní metody bylo založeno na průměru individuální plánovač/dávkové běhové prostředí, protože některé plánovače skončily rychleji než jiné.
Je těžké si představit přesný obrázek z tabulky, jak je znázorněno, protože některé úkoly mají závislosti, takže se pokusím zobrazit informace jako časovou osu a ukázat, jak velkou kompresi získáte v porovnání s vynaloženým časem:
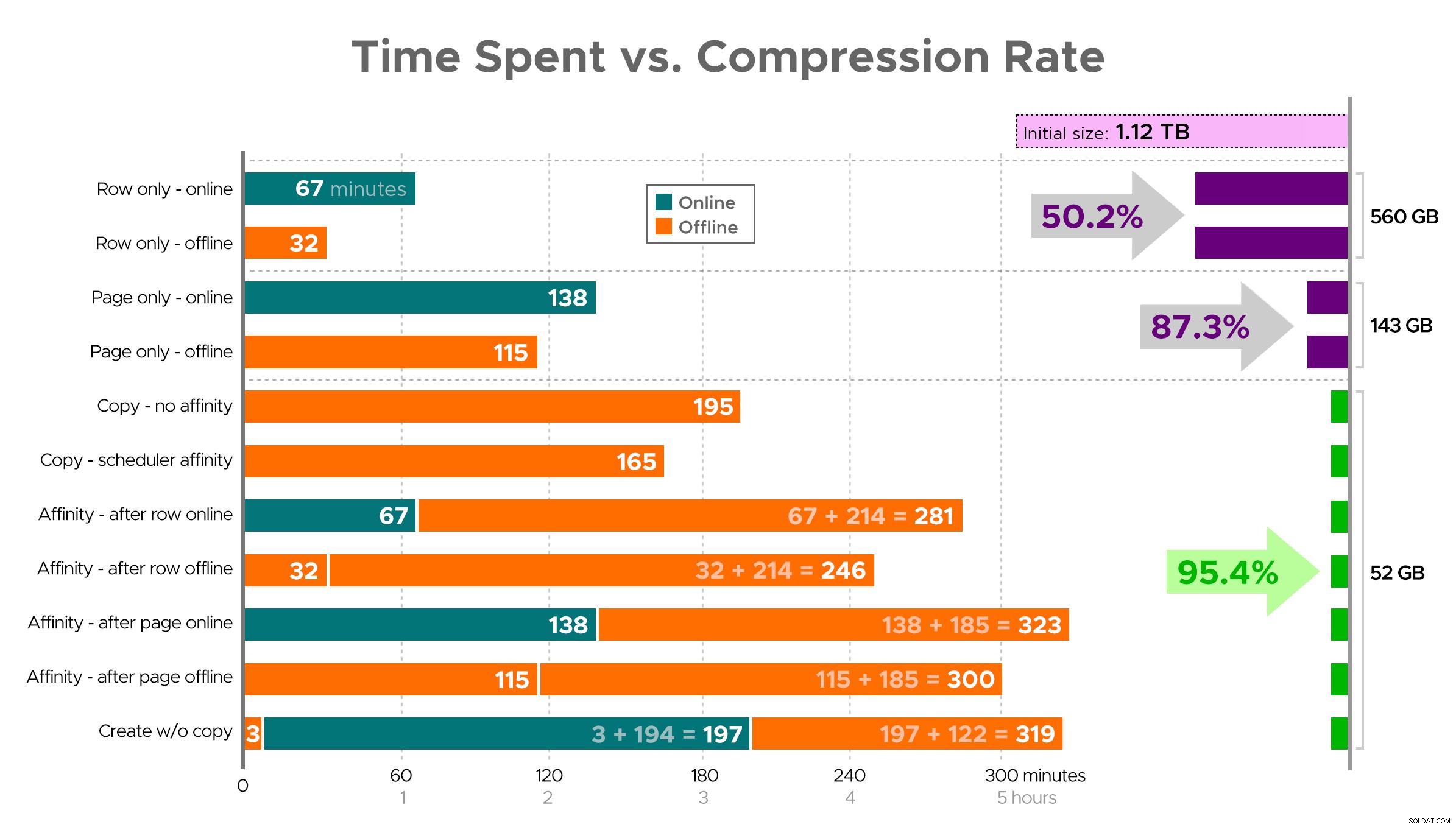 Čas strávený (minuty) vs. míra komprese
Čas strávený (minuty) vs. míra komprese
Několik postřehů z výsledků s upozorněním, že vaše data se mohou komprimovat odlišně (a že online operace se vás týkají pouze v případě, že používáte Enterprise Edition):
- Pokud je vaší prioritou co nejrychleji ušetřit místo , nejlepším řešením je použít kompresi řádků na místě. Pokud chcete minimalizovat rušení, použijte online; pokud chcete optimalizovat rychlost, použijte offline.
- Pokud chcete maximalizovat kompresi s nulovým narušením , můžete dosáhnout 90% snížení úložiště bez jakéhokoli přerušení pomocí komprese stránky online.
- Pokud chcete maximalizovat kompresi a narušení, je to v pořádku , zkopírujte data do nové, rozdělené verze tabulky s klastrovaným indexem columnstore a k migraci dat použijte výše popsaný proces spřažení. (A znovu, toto narušení můžete odstranit, pokud jste lepší plánovač než já.)
Poslední možnost fungovala nejlépe pro můj scénář, i když stále budeme muset nakopnout pneumatiky na pracovní zátěž (ano, množné číslo). Všimněte si také, že v SQL Server 2019 tato technika nemusí fungovat tak dobře, ale můžete tam vytvořit clusterované indexy columnstore online, takže na tom nemusí tolik záležet.
Některé z těchto přístupů mohou být pro vás více či méně přijatelné, protože můžete upřednostňovat „zůstat k dispozici“ před „dokončením co nejrychleji“ nebo „minimalizace využití disku“ před „zůstat k dispozici“ nebo jen vyvažovat výkon při čtení a režii zápisu. .
Pokud chcete více podrobností o jakémkoli aspektu tohoto, zeptejte se. Ukrojil jsem část tuku, abych vyvážil detaily se stravitelností, a dříve jsem se v této rovnováze mýlil. Myšlenka na rozloučenou je, že jsem zvědavý, jak lineární to je – máme další stůl s podobnou strukturou, který má více než 25 TB, a jsem zvědavý, jestli tam můžeme udělat nějaký podobný dopad. Do té doby přejeme příjemnou kompresi!
[ Část 1 | Část 2 | Část 3 ]