„Waitstats nám pomáhá identifikovat počítadla související s výkonem. Samotné informace o čekání však k přesné diagnostice problémů s výkonem nestačí. Komponenta front naší metodiky pochází z čítačů Performance Monitor, které poskytují pohled na výkon systému z hlediska zdrojů.“Tom Davidson, Otevírání Microsoft Performance-Tuning Toolbox
SQL Server Pro Magazine, prosinec 2003
Čekání a fronty se používají jako metodika ladění výkonu SQL Serveru od doby, kdy Tom Davidson publikoval výše uvedený článek a také známý whitepaper SQL Server 2005 Waits and Queues v roce 2006. Při použití v kombinaci s metrikami zdrojů může být čekání cenné pro posouzení určitých výkonnostních charakteristik pracovního zatížení a pomoc při řízení úsilí o ladění. Čekací data se objevují v mnoha řešeních sledování výkonu SQL Serveru a já jsem od začátku zastáncem vyladění pomocí této metodiky. Tento přístup měl vliv na návrh řídicího panelu výkonu SQL Sentry, který představuje čekání lemovaná frontami (klíčové metriky zdrojů) s cílem poskytnout komplexní pohled na výkon serveru.
Zdá se však, že někteří přehlédli Davidsonovu pointu týkající se důležitosti zdrojů a spoléhají téměř výhradně na čekání, aby předložili obrázek o výkonu dotazů a stavu systému. Statistiky čekání pocházejí přímo z enginu SQL Serveru a lze je snadno konzumovat a kategorizovat. Čekací dotazy znamenají čekající aplikace a uživatelé a nikdo nerad čeká! Je snazší evangelizovat ladění pomocí čekání jako jedinečného řešení pro rychlejší vytváření dotazů a aplikací, než vyprávět celý příběh, což je mnohem složitější.
Naneštěstí přístup zaměřený na čekání k vyloučení analýzy zdrojů může být zavádějící a v nejhorším případě vás nechat slepě létat. Členové týmu SentryOne Kevin Kline a Steve Wright se toho již dříve dotkli zde a zde. V tomto příspěvku se hlouběji ponořím do nedávného výzkumu, který umožnil Query Store a který vrhl nové světlo na to, jak nedostatečné čekací exkluzivní ladění skutečně může být.
Nejčastější dotazy, které nebyly
Nedávno mě kontaktoval zákazník SentryOne ohledně problémů s výkonem jejich databáze SentryOne. V srdci každého monitorovacího prostředí SentryOne je jediná databáze SQL Server a tento zákazník pomocí našeho softwaru monitoroval přibližně 600 serverů. V tomto měřítku není neobvyklé vidět občasný problém s výkonem dotazů a provést malé vyladění a některé údajně nové dotazy v pracovní zátěži byly zdrojem jejich obav.
Připojil jsem se k relaci sdílení obrazovky, abych se podíval, a zákazník mi nejprve předložil data z jiného systému, který také monitoroval databázi SentryOne. Systém použil přístup čekání na úrovni dotazu a ukázal dvě uložené procedury jako zodpovědné za přibližně polovinu čekání na databázovém serveru SQL Sentry. To bylo neobvyklé, protože tyto dva postupy vždy běží velmi rychle a nikdy nenaznačovaly skutečný problém s výkonem v naší databázi. Zmateně jsem přešel na SQL Sentry, abych viděl, co nám ukáže, a překvapilo mě, že ve stejném intervalu byla procedura #1 v jiném systému #6, #7 a #8, pokud jde o celkovou dobu trvání, CPU a logické přečtení:
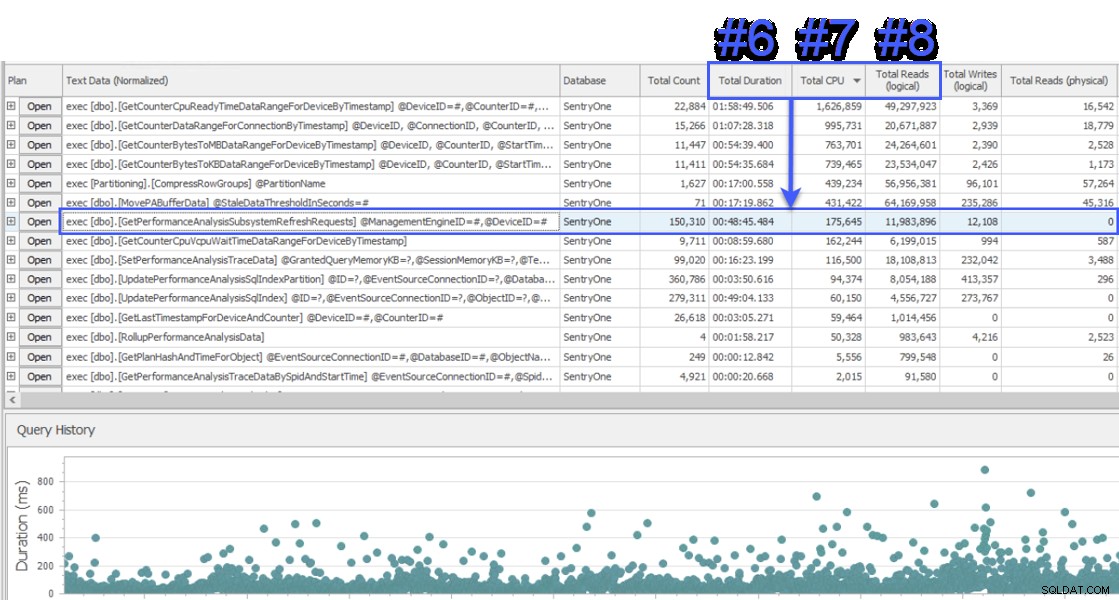 Zobrazení „Top SQL“ SQL Sentry
Zobrazení „Top SQL“ SQL Sentry
Z hlediska spotřeby zdrojů to znamenalo, že dotazy nad tím představovaly 75 % celkové doby trvání, 87 % celkového CPU a 88 % logických čtení. Navíc postup č. 2 v jiném systému nebyl v žádném případě ani v top 30 v SQL Sentry! Tyto dva dotazy byly daleko od prvních 2 a dotazy, které představovaly většinu skutečných spotřeba v systému byla výrazně nedostatečně zastoupena.
Vždy jsem předpokládal, že existuje silnější korelace mezi nejlepšími číšníky a hlavními spotřebiteli zdrojů, ale nikdy jsem takové přímé srovnání na úrovni dotazu neprováděl, takže tyto výsledky byly přinejmenším překvapivé. Můj zájem vzbudil zájem, rozhodl jsem se prozkoumat, zda je tato situace typická nebo anomální.
Query Store 2017 na záchranu
V SQL Server 2017 a novějších zachycuje Query Store kromě spotřeby prostředků dotazu i čekání na úrovni dotazu. Erin Stellato napsala skvělý příspěvek na Query Store čeká zde. Je to nižší režie a je přesnější než dotazování, na které DMV čeká každou sekundu a doufá, že zachytí dotazy za letu, což je standardní přístup používaný jinými nástroji včetně výše uvedeného.
SQL Sentry vždy zachycoval čekání, ale na úrovni instance SQL Server, kvůli těmto obavám o režii a přesnost. Podrobné čekání na dotazy jsou k dispozici na vyžádání prostřednictvím integrovaného Průzkumníka plánů a vyhodnocujeme rozšíření čekání na úrovni instance s údaji na úrovni dotazu z úložiště dotazů, budou-li k dispozici.
Pro toto úsilí jsem si na pomoc přizval SentryOne Product Advisory Council, skupinu zákazníků, partnerů a přátel SentryOne z oboru, kteří se účastní soukromého kanálu Slack. Sdílel jsem tento skript, abych vyložil předchozí 8 hodin dat z Query Store a obdržel jsem zpět výsledky pro 11 produkčních serverů v různých odvětvích, včetně finančních služeb, publikování her, sledování kondice a pojištění.
Kategorie čekání v Query Store jsou zdokumentovány zde. Do analýzy byly zahrnuty všechny kategorie kromě těchto, které byly odstraněny z uvedených důvodů:
- Paralelismus – Může divoce nafouknout čekací dobu dotazu daleko za jeho skutečnou dobu trvání, protože více vláken může shodit související čekání, což zmate korelaci s dobou trvání a dalšími metrikami. Dále, i když je rozdělení CXPACKET/CXCONSUMER užitečné, CXPACKET stále znamená pouze to, že máte paralelismus a není nutně problematické nebo použitelné.
- CPU – Doba čekání na signál může být užitečná pro zjišťování překážek CPU prostřednictvím korelace s čekáním na prostředky, ale Query Store v současné době zahrnuje pouze SOS_SCHEDULER_YIELD v této kategorii, což není čekání v tradičním smyslu, jak je zde popsáno. Nehodí se ke snadnému porovnávání nebo korelaci, zvláště když je SQL Server na virtuálním počítači, který žije na hostiteli s větším počtem předplatných. Například na jednom serveru byla čekání CPU na úložiště dotazů 227 % celkového času CPU ve všech dotazech bez paralelismu, což by nemělo být možné.
- Uživatel čeká a Nečinný – Tyto kategorie se skládají výhradně z časovače a čekání ve frontě a byly vyloučeny ze stejného důvodu, proč by se tyto typy měly vždy vyloučit – jsou neškodné a vytvářejí pouze šum.
Mimochodem, nedávno jsem mluvil s otcem Query Store, Conorem Cunninghamem, o pravděpodobnosti budoucích změn typů a kategorií čekání v Query Store a on naznačil, že je to určitě možné... takže budeme muset dávat pozor to.
Výsledky analýzy TL;DR
Po rozsáhlé analýze jsem potvrdil, že výsledky pozorované na zákaznickém systému nejsou anomální, ale spíše běžné. To znamená, že pokud jste závislí na nástroji zaměřeném na čekání pro sledování a ladění vaší pracovní zátěže, je vysoká pravděpodobnost, že se zaměřujete na špatné dotazy a postrádáte ty, kteří jsou zodpovědní za většinu doby trvání dotazu a spotřeby zdrojů v systému. Vzhledem k tomu, že spotřeba CPU a IO se přímo promítá do serverového hardwaru a výdajů na cloud, je to významné.
Většina dotazů nečeká
Zajímavým a důležitým zjištěním, kterému se budu věnovat jako první, je, že většina dotazů negeneruje vůbec žádné čekání. Z celkového počtu 56 438 dotazů na všech serverech mělo pouze 9 781 (17 %) nějakou čekací dobu a pouze 8 092 (14 %) mělo čekací dobu od významných typů. Pokud k určení dotazů, které chcete optimalizovat, používáte pouze čekání, zmeškáte většinu dotazů v pracovní zátěži.
Korelace čekání a zdrojů
Analyzoval jsem, jak čekání souvisí se spotřebou zdrojů, a to tak, že jsem seřadil všechny dotazy v každém systému podle čekání a zdrojů a použil jsem hodnocení k výpočtu Spearmanovy korelace. To, co se nakonec snažíme zjistit, je, zda špičkoví číšníci bývají hlavními spotřebiteli. Jak se ukázalo, nemají.
Tabulka 1 zobrazuje korelační koeficienty v barevné škále pro průměrné čekání na dotaz čas k ostatním měřítkům – hodnota 1,00 (tmavě modrá) představuje data, která jsou dokonale korelovaná. Jak můžete vidět, korelace s čekáním a dalšími měřeními na většině serverů není silná a u jednoho serveru existuje negativní korelace s většinou měření.
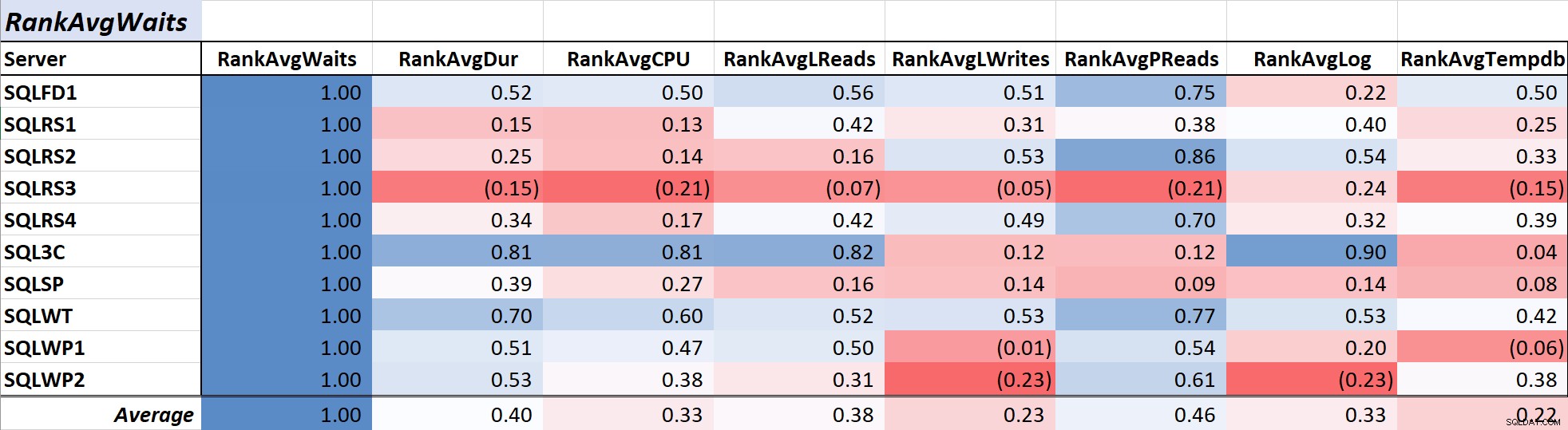 Tabulka 1:Korelace s průměrnou dobou čekání na dotaz (ms)
Tabulka 1:Korelace s průměrnou dobou čekání na dotaz (ms)
Trvání dotazu je často primárním zájmem administrátorů a vývojářů, protože se přímo promítá do uživatelského prostředí a Tabulka 2 ukazuje korelaci mezi průměrnou dobou trvání dotazu a další opatření. Korelace s dobou trvání a dvěma primárními zdroji, CPU a logickým čtením, je poměrně silná na 0,97 a 0,75.
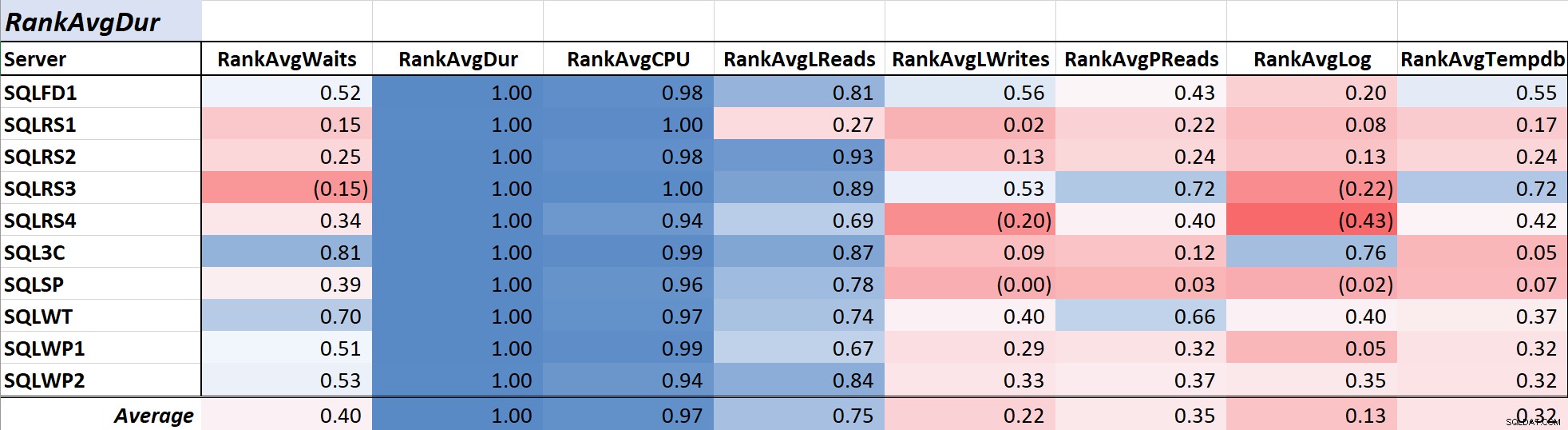 Tabulka 2:Korelace s průměrnou dobou trvání dotazu (ms)
Tabulka 2:Korelace s průměrnou dobou trvání dotazu (ms)
Protože logická čtení vždy využívají CPU a stejně jako doba trvání se CPU měří v milisekundách, není tento vztah překvapivý. Výsledky jsou v souladu s myšlenkou, že pokud chcete, aby vaše databázové aplikace běžely co nejrychleji, zaměření na snížení procesoru dotazů a logických čtení bude efektivnější při zkrácení doby trvání než použití samotného čekání. Naštěstí je to pomocí lepšího návrhu dotazu, indexování atd. obvykle přímočařejší než přímé zkrácení doby čekání na dotaz. Kolega Aaron Bertrand zde účinně prezentuje některá varování při ladění pomocí čekání.
% celkové doby čekání
Dále jsem se podíval na to, zda dotazy s nejvyšší dobou čekání obvykle představují největší spotřebu zdrojů. Chceme zjistit, zda to, co jsme viděli na zákaznickém systému, je atypické, kde 2 hlavní čekající dotazy představovaly relativně malé procento z celkové spotřeby zdrojů.
Graf 1 níže ukazuje % celkového CPU a logických čtení pro každý server, na které se vztahují dotazy představující 75 % celkové doby čekání. Pouze jeden server měl zdroj přesahující 75 % – čtení na SQLRS3. Ve zbytku spotřebovaly dotazy zodpovědné za 75 % čekací doby méně než 75 % zdrojů – často mnohem méně. To odráží to, co jsme viděli na zákaznickém systému, a je v souladu s korelační analýzou.
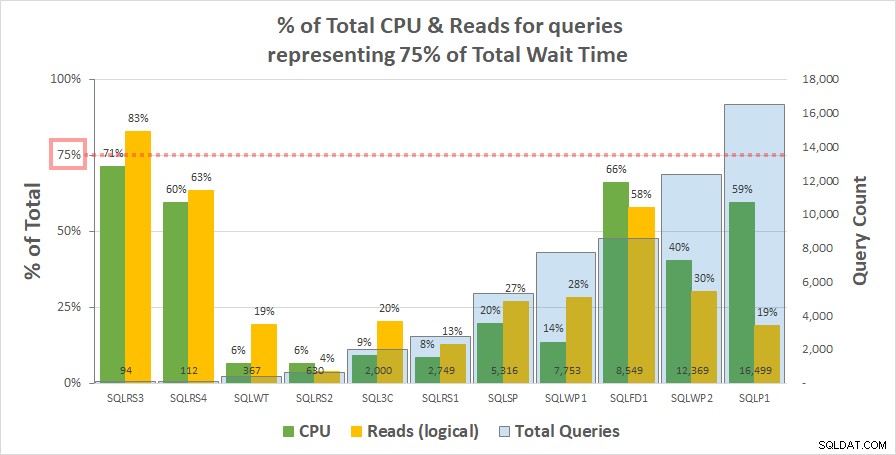 Graf 1
Graf 1
Všimněte si, že se zdá, že existuje vztah s celkovým počtem dotazů v pracovní zátěži. Ta je reprezentována řadou světle modrých sloupců na sekundární ose y a graf je podle této řady řazen vzestupně. Dva servery s nejvyšší mírou zdrojů při 75 % čekání měly také nejméně dotazů (SQLRS3 a SQLRS4). Čím menší je pracovní zátěž, tím větší je potenciální vliv malého počtu dotazů a jistě, na obou serverech představovaly většinu čekání a zdrojů pouze dva dotazy. Jedním ze způsobů, jak se na to podívat, je, že čekání nejvíce pomáhá identifikovat vaše nejtěžší dotazy, když to nejméně potřebujete.
Doba čekání a trvání dotazu
Nakonec jsem vyhodnotil % celkové doby čekání k celkové době trvání dotazu na každém systému. Tabulka 3 má sloupce pro:
- Celková doba trvání dotazu v ms
- Celková doba čekání ms – nezpracovaná
- Celková doba čekání ms – bez paralelismu, nečinnosti a čekání uživatelů (Rev1)
- Celková doba čekání ms – bez paralelismu, nečinnosti, čekání uživatelů a CPU (Rev2)
- Procento doby trvání pro 3 sloupce doby čekání s datovými pruhy
- Celkový počet jedinečných dotazů s datovými pruhy
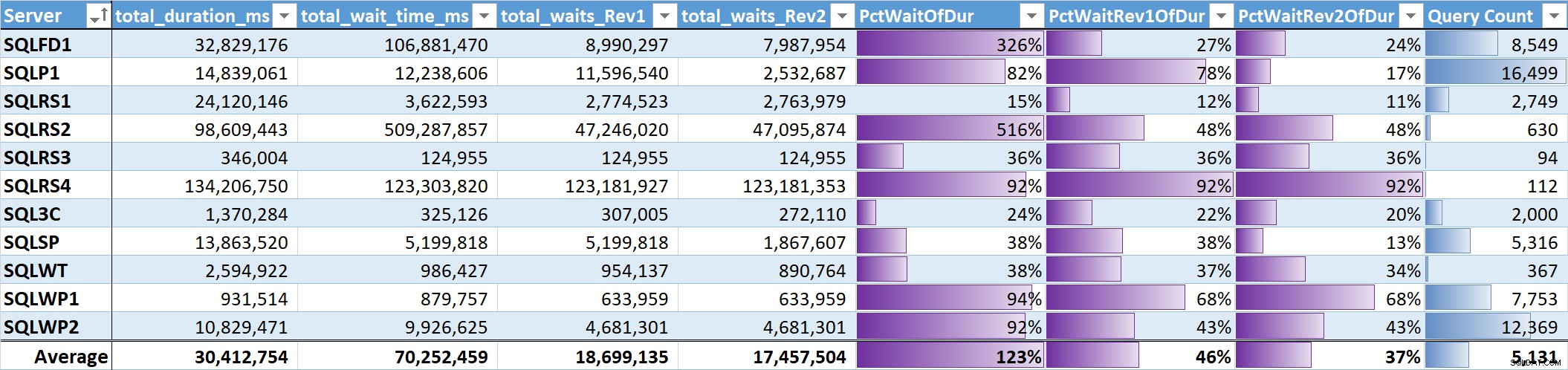 Tabulka 3
Tabulka 3
Nevážený průměr pro smysluplné čekání (Rev2) ve všech systémech je 37 % celkové doby trvání dotazu. U pěti systémů to bylo méně než 25 % a pouze u dvou systémů to bylo nad 50 %. V systému s 92 % čekací doby (SQLRS4), jeden s nejmenším počtem dotazů, představovaly dva dotazy 99 % čekání, 97 % trvání, 84 % CPU a 86 % čtení.
Ačkoli může čekací doba představovat značnou část doby běhu dotazu na určitých systémech a zdá se intuitivní, že pokud zkrátíte čekací dobu, zkrátí se i doba trvání dotazu, viděli jsme, že čekací doba a trvání spolu slabě korelují. Je nepravděpodobné, že by to bylo tak jednoduché a moje vlastní zkušenost to potvrzuje. Zde je zapotřebí další výzkum.
Komplexní ladění pomocí Plan Explorer a SQL Sentry
Jak tento vynikající dokument o SQLskills často naznačuje, kořenem vysokého čekání jsou často neoptimalizované dotazy a indexy. Bezplatný SentryOne Plan Explorer je účelově vytvořen ke snížení spotřeby zdrojů prostřednictvím efektivního ladění dotazů pomocí modulu Index Analysis a mnoha dalších inovativních funkcí. SQL Sentry integruje Plan Explorer přímo do modulů Top SQL, Blocking a Deadlocks, takže můžete automaticky zachytit a vyladit problematické dotazy na jednom místě. Můžete snadno vybrat rozsah zájmu na historickém čekacím panelu SQL Sentry, grafech CPU nebo IO a přejít na zobrazení Top SQL, kde najdete dotazy s nejvyšší spotřebou zdrojů během této doby. Poté můžete jediným kliknutím otevřít dotaz v Průzkumníku plánů a získat podrobné čekání na úrovni dotazu a zdroje na vyžádání v případě potřeby. Nemyslím si, že existuje lepší ztělesnění úplné metodiky ladění čekání a front než toto.
 Tabulka „Čekání“ řídicího panelu SQL Sentry
Tabulka „Čekání“ řídicího panelu SQL Sentry
 Bezplatný SentryOne Plan Explorer zobrazující čekání v průběhu času spolu s úrovní operace náklady a zdroje
Bezplatný SentryOne Plan Explorer zobrazující čekání v průběhu času spolu s úrovní operace náklady a zdroje
Závěr
Ladění pomocí čekání a front je dnes pro výkon SQL Server stejně použitelné jako v roce 2006. Zaměření se na čekání s vyloučením zdrojů je však nebezpečná záležitost, protože z dat je jasné, že to povede k obecně neoptimalizovaným a nákladově neefektivní systémy. Pokud jde o hardwarové prostředky a cloudové výdaje, nakonec platíte za výpočetní a IO zdroje, nikoli za čekací dobu, takže je vhodné optimalizovat přímo pro spotřebu. Podle mých zkušeností, jak se spotřeba zdrojů a související spory snižují, bude přirozeně následovat kratší čekací doba.
Potvrzení
Chtěl jsem poděkovat Fredu Frostovi, vedoucímu datovému vědci ze SentryOne, za jeho cenný příspěvek a kritické zhodnocení této analýzy.