Parametry s hodnotou tabulky existují od SQL Serveru 2008 a poskytují užitečný mechanismus pro odesílání více řádků dat na SQL Server, které jsou spojeny jako jediné parametrizované volání. Jakékoli řádky jsou pak k dispozici v proměnné tabulky, kterou lze poté použít ve standardním kódování T-SQL, což eliminuje potřebu psát specializovanou logiku zpracování pro opětovné rozdělení dat. Už svou definicí jsou parametry s hodnotou tabulky silně typovány na uživatelsky definovaný typ tabulky, který musí existovat v databázi, kde se volání provádí. Výraz se silným typem však není ve skutečnosti přísně „silně napsaný“, jak byste očekávali, jak ukazuje tento článek, a v důsledku toho může být ovlivněn výkon.
Abychom demonstrovali potenciální dopady na výkon nesprávně zadaných parametrů s hodnotou tabulky se serverem SQL Server, vytvoříme příklad uživatelsky definovaného typu tabulky s následující strukturou:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Potom budeme potřebovat aplikaci .NET, která bude používat tento uživatelsky definovaný typ tabulky jako vstupní parametr pro předávání dat do SQL Serveru. Chcete-li použít parametr s hodnotou tabulky z naší aplikace, objekt DataTable je obvykle naplněn a poté předán jako hodnota parametru s typem SqlDbType.Structured. DataTable lze v kódu .NET vytvořit několika způsoby, ale běžný způsob vytvoření tabulky je něco jako následující:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); DataTable můžete také vytvořit pomocí vložené definice takto:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; Kteroukoli z těchto definic objektu DataTable v .NET lze použít jako parametr s hodnotou tabulky pro uživatelem definovaný datový typ, který byl vytvořen, ale všimněte si definice typeof(string) pro různé sloupce řetězce; všechny mohou být „správně“ napsány, ale ve skutečnosti nejsou přesně zapsány do datových typů implementovaných v uživatelsky definovaném datovém typu. Můžeme naplnit tabulku náhodnými daty a předat je SQL Serveru jako parametr velmi jednoduchému příkazu SELECT, který vrátí přesně stejné řádky jako tabulka, kterou jsme předali, následovně:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
} Poté můžeme použít ladicí přestávku, abychom mohli zkontrolovat definici DefaultTable během provádění, jak je uvedeno níže:
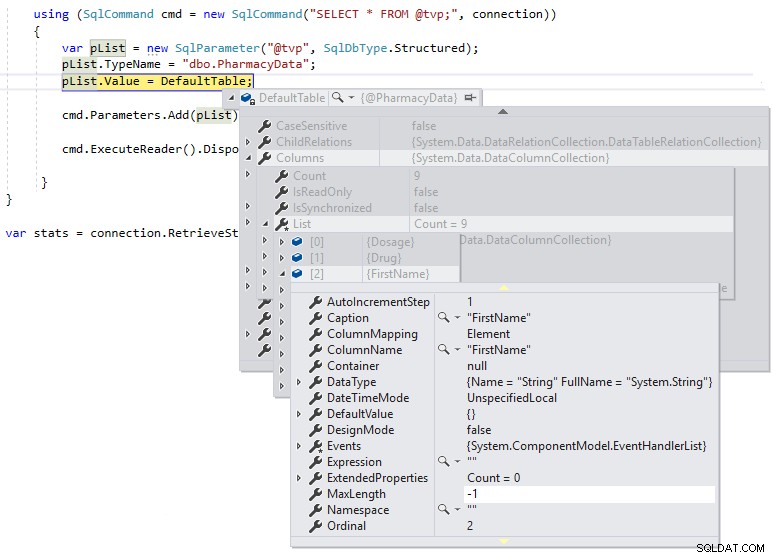
Vidíme, že MaxLength pro sloupce řetězce je nastavena na -1, což znamená, že jsou předávány přes TDS na SQL Server jako LOB (velké objekty) nebo v podstatě jako sloupce datového typu MAX, což může mít negativní dopad na výkon. Pokud změníme definici .NET DataTable tak, aby byla silně zadaná, na definici schématu uživatelem definovaného typu tabulky následovně a podíváme se na MaxLength stejného sloupce pomocí ladicí přestávky:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};
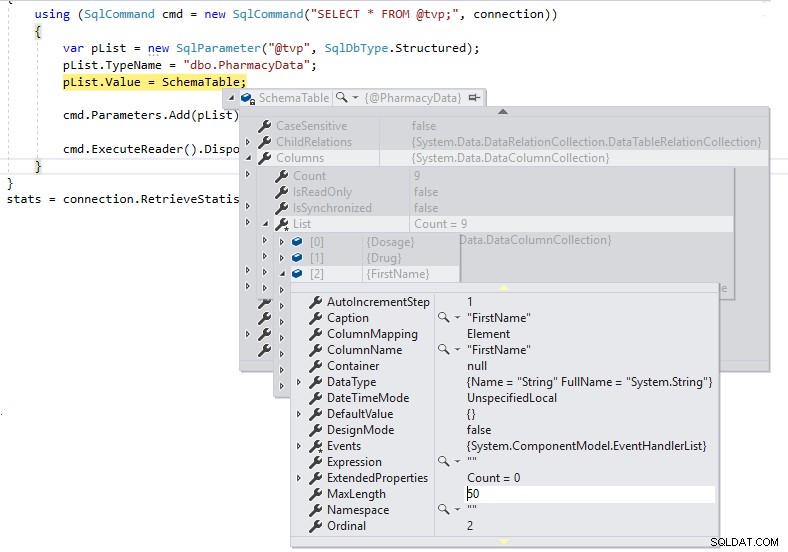
Nyní máme správné délky pro definice sloupců a nebudeme je předávat jako LOB přes TDS na SQL Server.
Možná by vás zajímalo, jak to ovlivňuje výkon? Ovlivňuje počet vyrovnávacích pamětí TDS, které jsou odesílány přes síť na SQL Server, a také ovlivňuje celkovou dobu zpracování příkazů.
Použití přesně stejné datové sady pro dvě datové tabulky a využití metody RetrieveStatistics na objektu SqlConnection nám umožňuje získat statistické metriky ExecutionTime a BuffersSent pro volání stejného příkazu SELECT a pouze pomocí dvou různých definic DataTable jako parametrů. a volání metody ResetStatistics objektu SqlConnection umožňuje vymazání statistik provádění mezi testy.
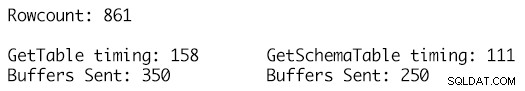
Definice GetSchemaTable specifikuje MaxLength pro každý sloupec řetězce správně, kde GetTable pouze přidává sloupce typu string, které mají hodnotu MaxLength nastavenou na -1, což má za následek odeslání 100 dalších vyrovnávacích pamětí TDS pro 861 řádků dat v tabulce a běhové prostředí 158 milisekund ve srovnání s pouze 250 odeslanými vyrovnávacími pamětmi pro silně typizovanou definici DataTable a doba běhu 111 milisekund. I když se to v celkovém schématu věcí nemusí zdát příliš mnoho, jedná se o jediné volání, jedinou exekuci a nahromaděný dopad v průběhu času pro tisíce nebo miliony takových exekucí je místo, kde se výhody začínají sčítat a mají znatelný dopad. na výkon pracovní zátěže a propustnost.
Tam, kde to skutečně může být rozdíl, jsou cloudové implementace, kde platíte za více než jen výpočetní a úložné zdroje. Kromě fixních nákladů na hardwarové prostředky pro Azure VM, SQL Database nebo AWS EC2 nebo RDS jsou zde další náklady na síťový provoz do a z cloudu, který je připojen k fakturaci za každý měsíc. Snížením vyrovnávacích pamětí procházejících kabelem se časem sníží TCO řešení a změny kódu potřebné k realizaci těchto úspor jsou relativně jednoduché.