Co je optimalizace dotazů v SQL Server? je to velké téma. Každá technika nebo problém potřebuje samostatný článek k pokrytí základů. Ale když právě začínáte zvyšovat úroveň své hry pomocí dotazů, potřebujete něco jednoduššího, na co se můžete spolehnout. To je cílem tohoto článku.
Můžete říci, že vaše dotazy jsou optimální, vše funguje dobře a uživatelé jsou spokojeni. Výkon samozřejmě není všechno. Výsledky by také měly být správné. Ať už jde o spojení, dílčí dotaz, synonymum, CTE, pohled nebo cokoli jiného, musí fungovat přijatelně.
A na konci dne můžete jít domů se svými uživateli. Nechcete zůstat přes noc v kanceláři a opravovat pomalu běžící dotazy.
Než začneme, dovolte mi vás ujistit, že cesta nebude náročná. Tohle bude jen základ. Budeme mít příklady, které vám nebudou příliš cizí. Nakonec, až budete připraveni na hlubší studium, představíme vám několik odkazů, které si můžete prohlédnout.
Začněme.
1. Optimalizace dotazů SQL začíná od návrhu a architektury
Překvapený? Optimalizace dotazů SQL není dodatečný nápad nebo náplast, když se něco pokazí. Váš dotaz běží tak rychle, jak to váš návrh umožňuje. Hovoříme o normalizovaných tabulkách, správných datových typech, použití indexů, archivaci starých dat a o všech osvědčených postupech, na které si vzpomenete.
Dobrý návrh databáze funguje v synergii se správným hardwarem a nastavením SQL Serveru. Navrhli jste jej tak, aby fungoval bez problémů několik let a stále se cítil jako nový? To je velký sen, ale na přemýšlení máme jen určitý (obvykle krátký) čas.
První den výroby to nebude dokonalé, ale měli bychom pokrýt základy. Minimalizujeme technický dluh. Pokud pracujete s týmem, je to skvělé ve srovnání s one-man show. Můžete zakrýt většinu zvonků a píšťalek.
Přesto, co když databáze běží živě a vy narazíte na výkonnostní zeď? Zde je několik tipů a triků pro optimalizaci dotazů SQL.
2. Odhalte problematické dotazy pomocí standardní zprávy SQL Server
Když kódujete, je snadné najít dlouhou řadu kódu nebo uloženou proceduru. Můžete to ladit řádek po řádku. Linka, která zaostává, je ta, kterou je třeba opravit.
Ale co když váš helpdesk vyhodí tucet lístků, protože je pomalý? Uživatelé nemohou určit přesné umístění v kódu a ani helpdesk. Čas je váš nejhorší nepřítel.
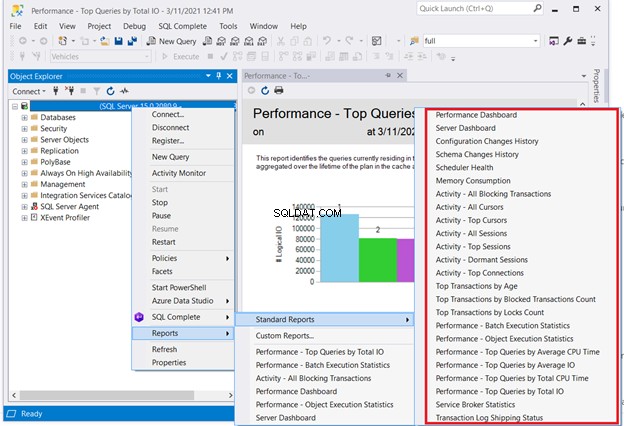
Jedním z řešení, které nebude vyžadovat kódování, je kontrola standardních sestav SQL Serveru. Klikněte pravým tlačítkem na potřebný server v SQL Server Management Studio> Přehledy> Standardní přehledy . Naším bodem zájmu může být Performance Dashboard nebo Výkon – Nejlepší dotazy podle celkových I/O . Vyberte první dotaz, který funguje špatně. Poté spusťte optimalizaci dotazu SQL nebo ladění výkonu SQL odtud.
3. Ladění dotazů SQL pomocí STATISTICS IO
Po určení příslušného dotazu můžete začít kontrolovat logická čtení ve STATISTICS IO. Toto je jeden z nástrojů pro optimalizaci dotazů SQL.
Existuje několik I/O bodů, ale měli byste se zaměřit na logické čtení. Čím vyšší jsou logická čtení, tím problematičtější je výkon dotazu.
Snížením následujících 3 faktorů můžete urychlit dotazy na ladění výkonu v SQL:
- vysoké logické čtení,
- logické čtení s vysokým LOB,
- nebo vysoké logické čtení WorkTable/WorkFile.
Chcete-li získat informace o logických čteních, zapněte STATISTICS IO v okně dotazu SQL Server Management Studio.
NASTAVTE STATISTIKY IO ZAPNUTO
Po dokončení dotazu můžete získat výstup na kartě Zprávy. Obrázek 2 zobrazuje ukázkový výstup:
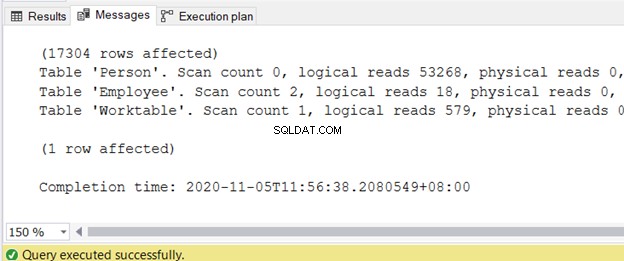
Napsal jsem samostatný článek o snížení logického čtení ve 3 Nasty I/O Statistics that Lag SQL Query Performance. Naleznete v něm přesné kroky a ukázky kódu s vysokým logickým čtením a způsoby, jak je snížit.
4. Ladění dotazů SQL pomocí plánů provádění
Samotné logické čtení vám neposkytne úplný obrázek. Série kroků zvolených optimalizátorem dotazů vypráví příběh vaší sady výsledků. Jak to všechno začne po provedení dotazu?
Obrázek 3 níže je schéma toho, co se stane poté, co spustíte provádění, až do okamžiku, kdy získáte sadu výsledků.
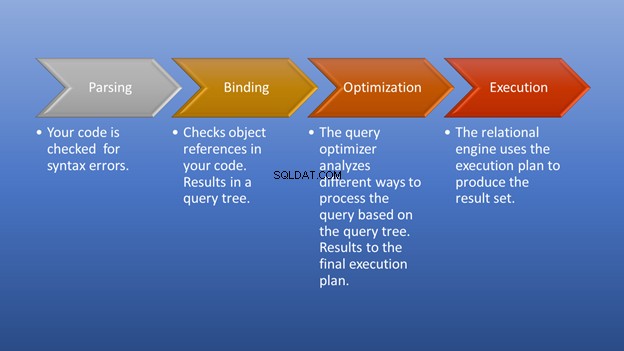
Analýza a vazba proběhne bleskově. Úžasná část je fáze optimalizace, na kterou se zaměřujeme. V této fázi hraje optimalizátor dotazů klíčovou roli při výběru nejlepšího možného plánu provádění. Ačkoli tato část potřebuje určité zdroje, ušetří spoustu času, když vybere účinný plán provádění. To se děje dynamicky, jak se databáze v průběhu času mění. Tímto způsobem se programátor může soustředit na to, jak vytvořit konečný výsledek.
Každý plán, který optimalizátor dotazů zvažuje, má své náklady na dotaz. Z mnoha možností vybere optimalizátor plán s nejpřijatelnějšími náklady. Poznámka :Přiměřené náklady se nerovnají nejnižším nákladům. Je třeba také zvážit, který plán přinese nejrychlejší výsledky. Plán s nejnižšími náklady není vždy nejrychlejší. Optimalizátor se může například rozhodnout využít několik procesorových jader. Říkáme tomu paralelní provádění. To spotřebovává více zdrojů, ale běží rychleji ve srovnání se sériovým prováděním.
Dalším bodem, který je třeba zvážit, je statistika. Optimalizátor dotazů na něj spoléhá při vytváření plánů provádění. Pokud jsou statistiky zastaralé, neočekávejte od optimalizátoru dotazů nejlepší rozhodnutí.
Když je plán rozhodnut a realizace pokračuje, uvidíte výsledky. Co teď?
Zkontrolujte plán provádění dotazů na serveru SQL Server
Když vytváříte dotaz, chcete nejprve vidět výsledky. Výsledky musí být správné. Až bude, máte hotovo.
Je to tak?
Pokud máte málo času a jde o práci, můžete s tím souhlasit. Navíc se vždycky můžeš vrátit. Pokud se však objeví další problémy, můžete na ně znovu a znovu zapomenout. A pak vás duch minulosti pronásleduje.
Co je teď nejlepší udělat, když získáte správné výsledky?
Prohlédněte si Plán skutečného provedení nebo Živé statistiky dotazů !
To druhé je dobré, pokud váš dotaz běží pomalu a chcete vidět, co se stane každou sekundu při zpracovávání řádků.
Občas vás situace donutí plán okamžitě zkontrolovat. Začněte stisknutím Control-M nebo klikněte na Zahrnout skutečný plán provádění z panelu nástrojů SQL Server Management Studio. Pokud dáváte přednost dbForge Studio pro SQL Server, přejděte na Query Profiler – poskytuje stejné informace + některé zvonky a píšťalky, které v SSMS nenajdete.
Viděli jsme Plán skutečného provedení . Pokračujme dále.
Chybí index nebo doporučení indexu?
Chybějící index lze snadno najít – varování se zobrazí okamžitě.
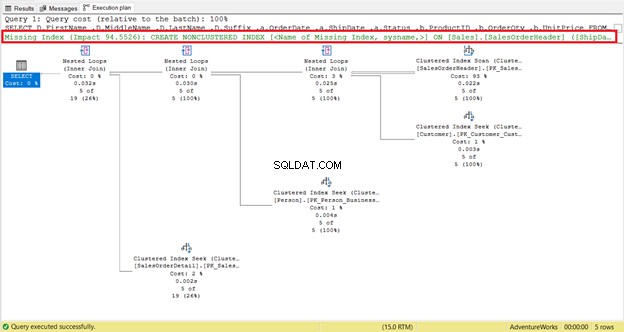
Chcete-li okamžitě získat kód pro vytvoření indexu, klikněte pravým tlačítkem na Chybějící index zpráva (rámeček červeně). Poté vyberte Chybějící podrobnosti indexu . Zobrazí se nové okno dotazu s kódem pro vytvoření chybějícího indexu. Vytvořte index.
Tato část je snadno sledovatelná. Je to dobrý výchozí bod pro dosažení rychlejšího provedení. Ale v některých případech to nebude mít žádný účinek. Proč? Některé sloupce potřebné pro váš dotaz nejsou v indexu. Proto se vrátí do Clustered Index Scan.
Po vytvoření indexu musíte znovu zkontrolovat plán provádění, abyste zjistili, zda jsou potřeba zahrnuté sloupce. Poté odpovídajícím způsobem upravte index a spusťte dotaz znovu. Poté znovu zkontrolujte plán provádění.
Co když ale žádný index nechybí?
Přečtěte si plán provádění
Abyste mohli začít, potřebujete vědět několik základních věcí:
- Operátoři
- Vlastnosti
- Směr čtení
- Upozornění
OPERÁTORY
Optimalizátor dotazů používá jakési miniprogramy zvané operátory. Některé z nich jste viděli na obrázku 4 – Hledání seskupeného indexu , Skenování seskupeného indexu , Vnořené smyčky a Vybrat .
Chcete-li získat úplný seznam s názvy, ikonami a popisy, můžete se podívat na tento odkaz od společnosti Microsoft.
VLASTNOSTI
Grafická schémata nestačí k pochopení toho, co se děje v zákulisí. Musíte se ponořit hlouběji do vlastností každého operátora. Například Clustered Index Scan na obrázku 4 má následující vlastnosti:
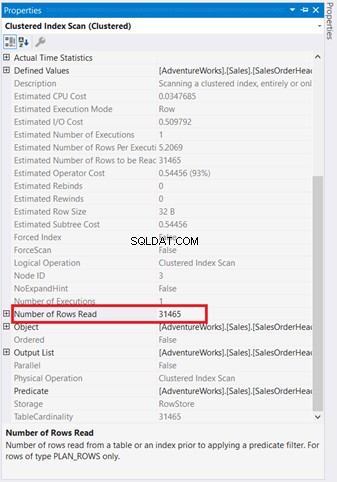
Pokud jej pečlivě prozkoumáte, Clustered Index Scan operátor je hrozný. Jak ukazuje obrázek 5, přečetla 31 465 řádků, ale konečná sada výsledků je pouze 5 řádků. Proto je na obrázku 4 doporučení indexu ke snížení počtu přečtených řádků. Logické čtení dotazu je také vysoké a to vysvětluje proč.
Chcete-li se dozvědět více o těchto vlastnostech, podívejte se na seznam běžných vlastností operátora a vlastností plánu.
Směr čtení
Obecně je to jako čtení japonské mangy – zprava doleva. Postupujte podle šipek, které směřují doleva. Zde je jednoduchý příklad z dbForge Studio pro SQL Server.
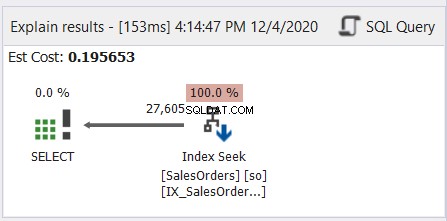
Jak ukazuje obrázek 6, šipka ukazuje doleva od operátoru Index Seek k operátoru SELECT.
Čtení zprava doleva však nemusí být vždy správné. Viz obrázek 7 s příkladem z SSMS:
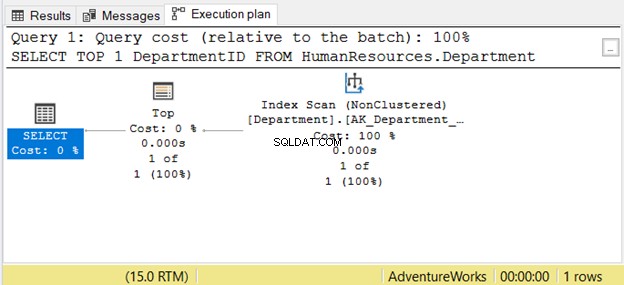
Pokud si jej přečtete zprava doleva, uvidíte, že Skenování indexu výstup operátora je 1 z 1 řádku. Jak může vědět, že má načíst jen 1 řádek? Je to kvůli Nahoře operátor. To nás zmást, pokud to čteme zprava doleva.
Abyste tomuto případu lépe porozuměli, přečtěte si jej jako „operátor SELECT používá Top k načtení 1 řádku pomocí Index Scan“. To je zleva doprava.
Co bychom měli použít? Zprava doleva nebo zleva doprava?
Jde o obojí – podle toho, co vám pomůže porozumět plánu.
Zatímco šipka nám udává směr toku dat, její tloušťka nám dává určité rady o velikosti dat. Podívejme se znovu na obrázek 4.
Skenování seskupeného indexu přechod do Vnořené smyčky má ve srovnání s ostatními silnější šipku. Vlastnosti podrobnosti o Skenování indexu na obrázku 5 nám řekněte, proč je tlustý (31 465 řádků přečtených pro konečný výsledek 5 řádků).
UPOZORNĚNÍ
Varovná ikona, která se objeví v operátoru prováděcího plánu, nám říká, že se v tomto operátoru stalo něco špatného. To může bránit optimalizaci dotazu SQL spotřebou více zdrojů.
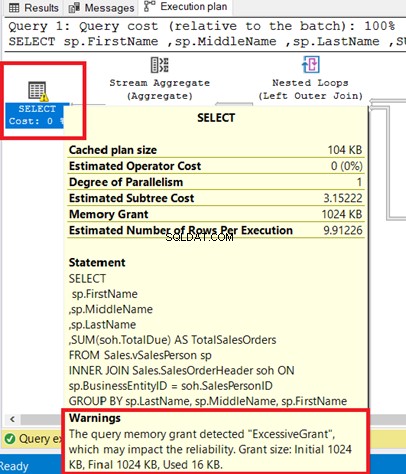
Varování můžete vidět v operátoru SELECT. Po najetí na tohoto operátora se zobrazí varovná zpráva. Nadměrný grant způsobilo toto varování.
ExcessiveGrant nastane, když je použito méně paměti, než bylo vyhrazeno pro dotaz. Další informace naleznete v této dokumentaci společnosti Microsoft.
Obrázek 8 ukazuje dotaz použitý jako INNER JOIN pohledu do tabulky. Varování můžete odstranit spojením základních tabulek namísto zobrazení.
Nyní, když máte základní představu o čtení plánů provádění, jak definovat, co zpomaluje váš dotaz?
Poznejte 5 obyčejných falešných operátorů plánu
Prodleva při provádění vašeho dotazu je jako zločin. Musíte tyto darebáky pronásledovat a zatknout.
1. Clustered or Non-clustered Index Scan
První lump, o kterém se každý dozví, je Clustered nebo Non-clustered Index Scan . V optimalizaci dotazů SQL je obecně známo, že skenování je špatné a vyhledávání je dobré. Jeden jsme viděli na obrázku 4. Kvůli chybějícímu indexu se Clustered Index Scan přečte 31 465 a získáte 5 řádků.
Není tomu však vždy tak. Uvažujme 2 dotazy ve stejné tabulce na obrázku 9. Jeden bude mít vyhledávání a druhý skenování.
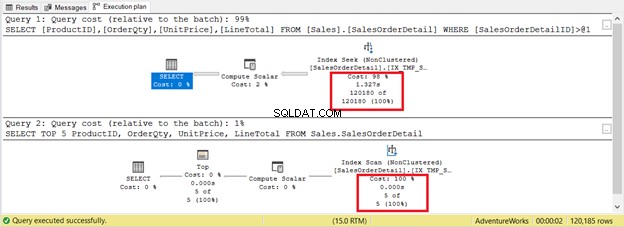
Pokud kritéria založíte pouze na počtu záznamů, indexové skenování vyhraje pouze s 5 záznamy oproti 120 180. Spuštění hledání indexu bude trvat déle.
Zde je další případ, kdy na skenování nebo hledání téměř nezáleží. Vrátí stejných 6 záznamů ze stejné tabulky. Logická čtení jsou stejná a uplynulý čas je v obou případech nulový. Tabulka je velmi malá, pouze 6 záznamů. Zahrňte skutečný plán provádění a spusťte níže uvedené příkazy.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Poté plán provádění uložte pro pozdější porovnání. Klikněte pravým tlačítkem na plán provádění> Uložit plán provádění jako .
Nyní spusťte níže uvedený dotaz.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Dále klikněte pravým tlačítkem myši na plán provádění a vyberte možnost Porovnat plán zobrazení . Poté vyberte soubor, který jste uložili dříve. Měli byste mít stejný výstup jako na obrázku 10 níže.
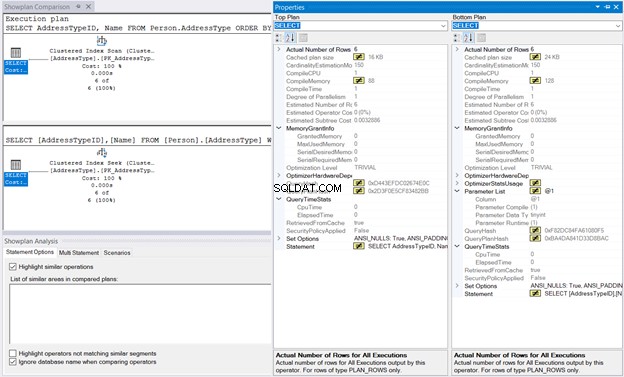
MemoryGrant a QueryTimeStats jsou stejní. CompileMemory o velikosti 128 kB používá se v Hledání seskupeného indexu ve srovnání s 88 kB skenování indexů clusterů je téměř zanedbatelný. Bez těchto čísel k porovnání bude provedení vypadat stejně.
2. Vyhýbání se prohledávání tabulek
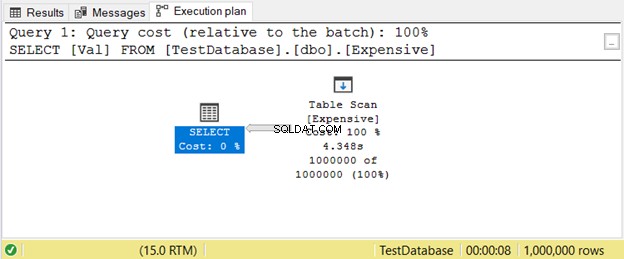
To se stane, když nemáte index. Namísto hledání hodnot pomocí indexu bude SQL Server skenovat řádky jeden po druhém, dokud v dotazu nezíská to, co potřebujete. To bude na velkých stolech hodně zaostávat. Jednoduchým řešením je přidat příslušný index.
Zde je příklad plánu provedení s Prohledáním tabulek operátor na obrázku 11.
3. Správa výkonu řazení
Jak vyplývá z názvu, mění pořadí řádků. To může být nákladná operace.
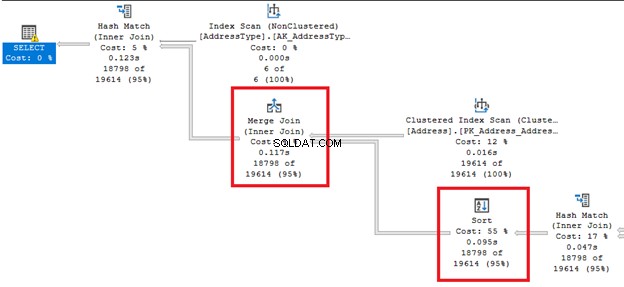
Podívejte se na ty tlusté šipky zprava a zleva od Řadit operátor. Protože se optimalizátor dotazů rozhodl provést sloučení spojení , a řazení je požadováno. Všimněte si také, že má nejvyšší procentuální náklady ze všech operátorů (55 %).
Třídění může být obtížnější, pokud SQL Server potřebuje seřadit řádky několikrát. Tomuto operátoru se můžete vyhnout, pokud je vaše tabulka předem setříděna na základě požadavku dotazu. Nebo můžete rozdělit jeden dotaz na více.
4. Eliminujte vyhledávání klíčů
Na obrázku 4 výše SQL Server doporučil přidat další index. Udělal jsem to, ale nedalo mi to přesně to, co jsem chtěl. Místo toho mi to poskytlo Vyhledávání indexu na nový index spárovaný s Vyhledáním klíčů operátor.
Takže nový index přidal další krok.
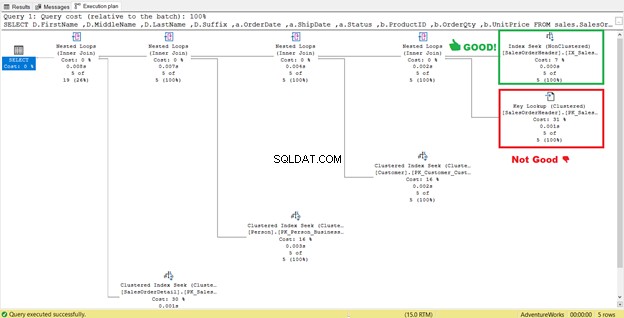
Co dělá toto Vyhledávání klíčů operátor ano?
Zpracovatel dotazů použil nový neshlukovaný index, který je na obrázku 13 označen zeleně. Protože náš dotaz vyžaduje sloupce, které nejsou v novém indexu, potřebuje tato data získat pomocí Vyhledávání klíčů ze seskupeného indexu. jak to víme? Umístěním myši na Vyhledání klíče odhaluje některé jeho vlastnosti a dokazuje náš názor.
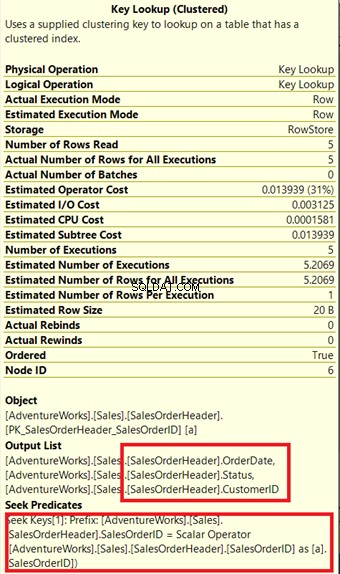
Na obrázku 14 si všimněte seznamu výstupů. Potřebujeme načíst 3 sloupce pomocí PK_SalesOrderHeader_SalesOrderID shlukovaný index. Chcete-li to odstranit, musíte tyto sloupce zahrnout do nového indexu. Zde je nový plán, jakmile budou tyto sloupce zahrnuty.
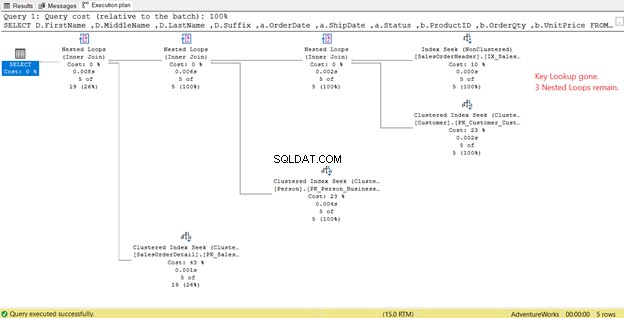
Na obrázku 14 jsme viděli 4 vnořené smyčky . Čtvrtý je potřeba pro přidané Vyhledání klíčů . Po přidání 3 sloupců jako zahrnutých sloupců do nového indexu však pouze 3 vnořené smyčky zůstat a Vyhledání klíče je odebrán. Nepotřebujeme žádné další kroky.
5. Paralelnost v SQL Server Execution Plan
Doposud jste viděli prováděcí plány v sériovém provedení. Ale tady je plán, který využívá paralelní provádění. To znamená, že optimalizátor dotazů využívá ke spuštění dotazu více než 1 procesor. Když použijeme paralelní provádění, vidíme Paralelismus operátorů v plánu a také další změny.
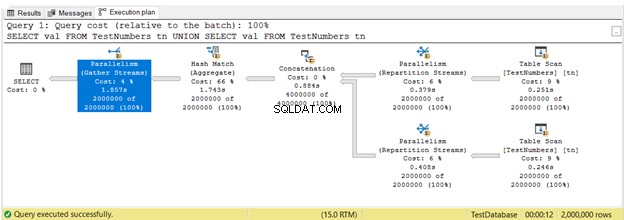
Na obrázku 16, 3 Paralelismus byly použity operátory. Všimněte si také, že Skenování tabulky ikona operátora je trochu jiná. K tomu dochází při použití paralelního provádění.
Paralelismus není ve své podstatě špatný. Zvyšuje rychlost dotazů využitím více procesorových jader. Využívá však více prostředků CPU. Když mnoho vašich dotazů používá paralelismus, zpomaluje to server. Možná budete chtít zkontrolovat prahovou hodnotu ceny pro nastavení paralelismu na vašem serveru SQL.
5. Nejlepší postupy pro optimalizaci dotazů SQL
Doposud jsme se zabývali optimalizací dotazů SQL pomocí metod, které odhalují těžko rozpoznatelné problémy. Ale existují způsoby, jak to v kódu najít. Zde jsou některé vůně kódu v SQL.
Pomocí SELECT *
Ve spěchu? Pak může být psaní * jednodušší než zadávání názvů sloupců. Má to však háček. Sloupce, které nepotřebujete, zpozdí váš dotaz.
Existuje důkaz. Ukázkový dotaz, který jsem použil pro obrázek 15, je tento:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Už jsme to optimalizovali. Ale změňme to na SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Je to kratší, dobře, ale podívejte se na prováděcí plán níže:
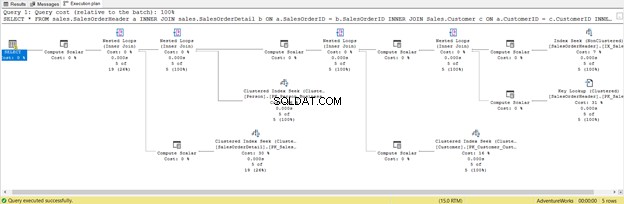
To je důsledek zahrnutí všech sloupců, dokonce i těch, které nepotřebujete. Vrátilo to Vyhledání klíče a spousta Výpočetního skaláru . Stručně řečeno, tento dotaz má velkou zátěž a ve výsledku se bude opožďovat. Všimněte si také varování v operátoru SELECT. Předtím to tam nebylo. Jaké plýtvání!
Funkce v klauzuli WHERE nebo JOIN
Dalším zápachem kódu je funkce v klauzuli WHERE. Zvažte následující 2 příkazy SELECT se stejnou sadou výsledků. Rozdíl je v klauzuli WHERE.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
První příkaz SELECT používá datové funkce YEAR a MONTH k označení data odeslání v červenci 2011. Druhý příkaz SELECT používá operátor BETWEEN s datovými literály.
První příkaz SELECT bude mít plán provádění podobný jako na obrázku 4, ale bez doporučení indexu. Druhý bude mít lepší plán provádění podobný obrázku 15.
Ten, který je lépe optimalizován, je zřejmý.
Použití zástupných znaků
Jak divoké mohou zástupné znaky ovlivnit naši optimalizaci dotazů SQL? Uveďme příklad.
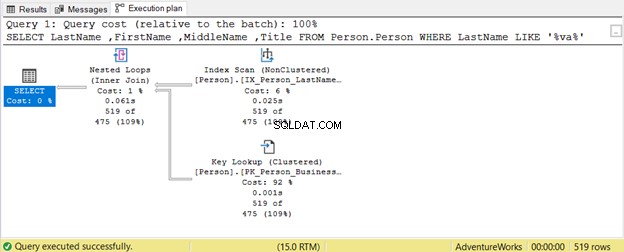
Dotaz se pokouší vyhledat přítomnost řetězce v Příjmení v jakékoli poloze. Proto Příjmení LIKE ‚%va%‘ . To je u velkých tabulek neefektivní, protože řádky budou kontrolovány jeden po druhém na přítomnost tohoto řetězce. Proto Skenování indexu se používá. Protože žádný index neobsahuje Titul Vyhledání klíče se také používá.
To lze opravit návrhem.
Vyžaduje to aplikace pro volání? Nebo bude stačit použít LIKE ‚va%‘?
LIKE ‚va%‘ používá Vyhledávání indexu protože tabulka má index na příjmení , křestní jméno a prostřední jméno .
Můžete také přidat další filtry do klauzule WHERE, abyste snížili čtení záznamů?
Vaše odpovědi na tyto otázky vám pomohou tento dotaz opravit.
Implicitní konverze
SQL Server provádí implicitní převod za scénou, aby sladil datové typy při porovnávání hodnot. Například je vhodné přiřadit číslo sloupci řetězce bez uvozovek. Má to ale háček. Efekt je podobný, když použijete funkci v klauzuli WHERE.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
NationalIDNumner je NVARCHAR(15), ale odpovídá číslu. Poběží úspěšně kvůli implicitní konverzi. Všimněte si však prováděcího plánu na obrázku 19 níže.
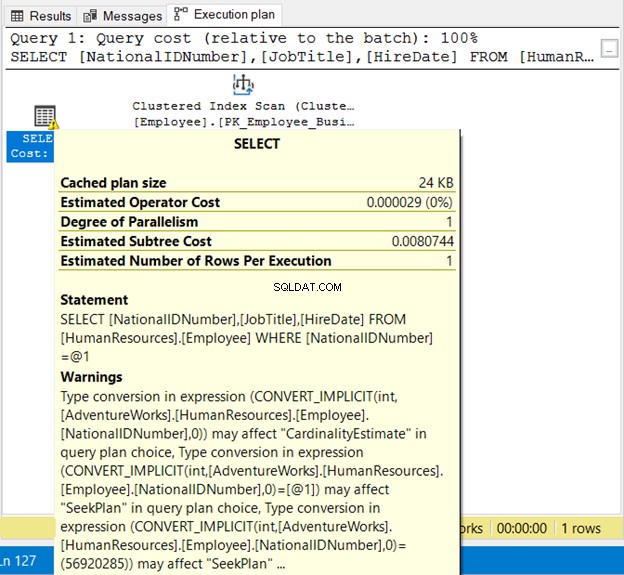
Vidíme zde 2 špatné věci. Za prvé, varování. Poté Skenování indexu . Skenování indexu proběhlo kvůli implicitní konverzi. Ujistěte se tedy, že řetězce uzavíráte do uvozovek nebo testujete doslovné hodnoty se stejným datovým typem jako sloupec.
Výsledky optimalizace dotazů SQL
A je to. Cítili jste se díky základům optimalizace dotazů SQL trochu připraveni na vaše dotazy? Udělejme si rekapitulaci.
- Pokud chcete optimalizovat své dotazy, začněte s dobrým návrhem databáze.
- Pokud je databáze již ve výrobě, zjistěte problematické dotazy pomocí standardních sestav SQL Server.
- Zjistěte, jak velký je dopad pomalého dotazu pomocí logického čtení ze STATISTICS IO.
- Ponořte se hlouběji do příběhu svého pomalého dotazu pomocí plánů provádění.
- Sledujte 4 pachy kódu, které zpomalují vaše dotazy.
Existují další tipy na optimalizaci dotazů SQL, aby pomalý dotaz běžel rychle. Jak jsem řekl na začátku, je to velké téma. Dejte nám tedy vědět v sekci Komentáře, co nám ještě uniklo.
A pokud se vám tento příspěvek líbí, sdílejte jej na svých oblíbených platformách sociálních médií.
Další optimalizace dotazů SQL z předchozích článků
Pokud potřebujete více příkladů, zde jsou některé užitečné příspěvky související s technikami optimalizace dotazů na SQL Server.
- Mají poddotazy špatný výkon? Podívejte se na Snadnou příručku o tom, jak používat poddotazy na serveru SQL Server .
- Používání HierarchyID vs. rodičovský/podřízený design – co je rychlejší? Navštivte stránku Jak používat SQL Server HierarchyID prostřednictvím jednoduchých příkladů .
- Mohou databázové dotazy v grafech překonat své relační ekvivalenty v systému doporučení v reálném čase? Podívejte se na Jak využít funkce SQL Server Graph Database .
- Co je rychlejší:COALESCE nebo ISNULL? Zjistěte to v Nejčastější odpovědi na 5 ožehavých otázek o funkci SQL COALESCE .
- SELECT FROM View vs. SELECT FROM Base Tables – který z nich poběží rychleji? Navštivte 3 nejlepší tipy, které potřebujete znát, abyste mohli psát rychlejší SQL zobrazení .
- CTE vs. dočasné tabulky vs. dílčí dotazy. Zjistěte, který z nich vyhraje v Vše, co potřebujete vědět o SQL CTE na jednom místě .
- Používání SQL SUBSTRING v klauzuli WHERE – výkonnostní past? Podívejte se, zda je to pravda, pomocí příkladů v článku Jak analyzovat řetězce jako profesionál pomocí funkce SQL SUBSTRING()?
- SQL UNION ALL je rychlejší než UNION. Zjistěte proč v SQL UNION Cheat Sheet s 10 snadnými a užitečnými tipy .