SQL Server Transakční replikace je jednou z nejběžnějších replikačních technik používaných ke kopírování nebo distribuci dat mezi více cíli.
V předchozích článcích jsme diskutovali o replikaci SQL Serveru, o tom, jak interně funguje a jak nakonfigurovat replikaci pomocí Průvodce replikací nebo přístupem T-SQL. Nyní se zaměříme na problémy s replikací SQL a jejich správné řešení.
Problémy s replikací SQL
Většina zákazníků, kteří používají SQL Server Transakční replikace, se zaměřuje hlavně na získávání dat téměř v reálném čase dostupných v instancích databáze předplatitelů. DBA, který spravuje replikaci, by si proto měl být vědom různých možných problémů souvisejících s replikací SQL, které mohou nastat. DBA také musí být schopen tyto problémy vyřešit v krátkém čase.
Všechny problémy s replikací SQL můžeme kategorizovat do níže uvedených kategorií (na základě mých zkušeností):
Problémy s konfigurací
- Maximální velikost replikace textu
- Služba SQL Server Agent Service není nastavena na spuštění automatického režimu
- Instance nemonitorované replikace se dostanou do neinicializovaného stavu předplatného
- Známé problémy na serveru SQL Server
Problémy s oprávněním
- Problémy s oprávněním k úloze SQL Server Agent
- Pověření úlohy agenta snímku nemají přístup k cestě ke složce snímku
- Pověření úlohy agenta Log Reader se nelze připojit k databázi vydavatele/distribuce
- Pověření úlohy agenta distribuce se nelze připojit k databázi distribuce/předplatitele
Problémy s připojením
- Server vydavatele nebyl nalezen nebo nebyl přístupný
- Distribuční server nebyl nalezen nebo nebyl přístupný
- Server předplatitele nebyl nalezen nebo nebyl přístupný
Problémy s integritou dat
- Chyby porušení primárního nebo jedinečného klíče
- Chyby řádek Nenalezen
- Chyby cizího klíče nebo jiných omezení
Problémy s výkonem
- Dlouhotrvající aktivní transakce v databázi vydavatele
- Hromadné operace INSERT/UPDATE/DELETE s články
- Velké změny dat v rámci jedné transakce
- Blokování v distribuční databázi
Problémy související s korupcí
- Poškození databáze vydavatelů
- Poškození souboru protokolu transakcí vydavatele
- Poškození distribuční databáze
- Poškození databáze odběratelů
Příprava DEMO prostředí
Než se ponoříme do podrobností o problémech replikace SQL, musíme naše prostředí připravit na ukázku. Jak bylo uvedeno v mých předchozích článcích, jakékoli změny dat, ke kterým dojde v databázi odběratelů v transakční replikaci, nebudou viditelné přímo v databázi vydavatele. Pro účely učení se tedy chystáme provést určité úpravy přímo v databázi předplatitelů.
Buďte prosím extrémně opatrní a v produkčních databázích nic neupravujte. Bude mít vliv na integritu dat předplatitelských databází. Vezmu záložní skripty pro každou provedenou změnu a použiji tyto skripty k vyřešení problémů s replikací SQL.
Změna 1 – Vkládání záznamů do tabulky Person.ContactType
Před vložením záznamů do Person.ContacType tabulka, podívejme se na strukturu tabulky, několik výchozích omezení a rozšířené vlastnosti upravené ve skriptu níže:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Tuto tabulku jsem zvolil, protože má méně sloupců. Pro testovací účely je to výhodnější. Nyní se podívejme, co máme o jeho struktuře:
- ContactTypeId je definován jako SLOUPEC IDENTITY – automaticky vygeneruje hodnoty primárního klíče a NENÍ K REPLIKÁCI.
- NOT FOR REPLICATION je speciální vlastnost, kterou lze použít u různých typů objektů, jako jsou tabulky, omezení, jako jsou omezení cizího klíče, kontrolní omezení, spouštěče a identita na vydavateli nebo předplatiteli pouze při použití jakékoli z metod replikace. Umožňuje správci databází plánovat nebo implementovat replikaci, aby se zajistilo, že se určité funkce budou při používání replikace chovat ve vydavateli/odběrateli odlišně.
- V našem případě dáváme SQL Server pokyn, aby používal hodnoty IDENTITY generované pouze v databázi Publisher. Vlastnost IDENTITY by se neměla používat u Person.ContactType tabulky v databázi předplatitelů. Podobně můžeme upravit omezení nebo spouštěče, aby se chovaly odlišně, když je replikace nakonfigurována pomocí této možnosti.
- V tabulce jsou k dispozici 2 další sloupce NOT NULL.
- Tabulka má primární klíč definovaný na ContactTypeId . Jen pro připomenutí, primární klíč je povinným požadavkem pro replikaci. Bez toho na stole bychom nebyli schopni replikovat tabulkový článek.
Nyní VLOŽME ukázkový záznam do Osobě .Typ kontaktu tabulce v AdventureWorks_REPL databáze:
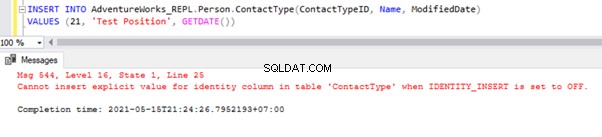
Přímý INSERT v tabulce selže v databázi odběratelů, protože vlastnost identity je zakázaná pouze pro replikaci pomocí možnosti NENÍ PRO REPLIKACI. Kdykoli provádíme operaci INSERT ručně, stále musíme použít možnost SET IDENTITY_INSERT takto:
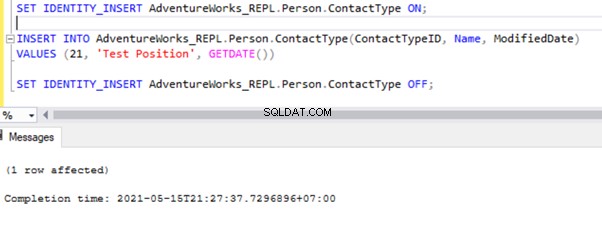
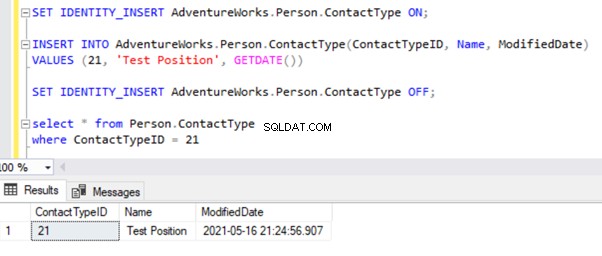
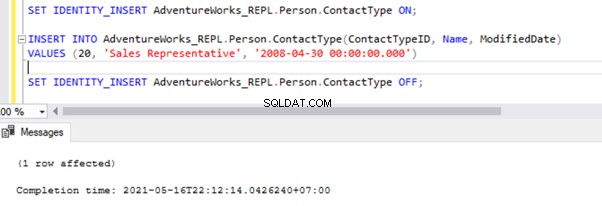
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Po přidání možnosti SET IDENTITY_INSERT můžeme záznam úspěšně VLOŽIT do Person.ContactType tabulka.
Provedením SELECT v tabulce se zobrazí nově vložený záznam:
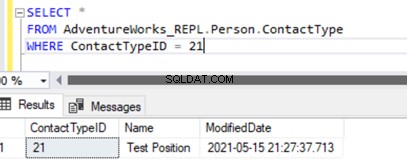
Přidali jsme nový záznam pouze do databáze odběratelů, který není dostupný v databázi vydavatelů na Person.ContactType tabulka.
Provedení SELECT na stejné tabulce databáze Publisher nezobrazí žádné záznamy. Jakékoli změny provedené v databázi odběratelů se tedy nereplikují do databáze vydavatelů.
Změna 2 – Odstranění 2 záznamů z tabulky Person.ContactType
Držíme se našeho známého Person.ContactType stůl. Před odstraněním záznamů z databáze odběratelů musíme ověřit, zda tyto záznamy existují u vydavatele i odběratele. Viz níže:
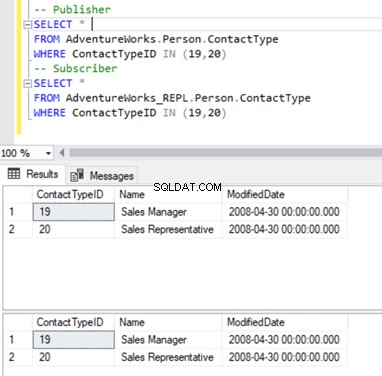
Nyní můžeme odstranit tyto 2 ContactTypeId pomocí následujícího příkazu:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
Výše uvedený skript nám umožňuje odstranit 2 záznamy z Person.ContactType tabulka v databázi odběratelů:
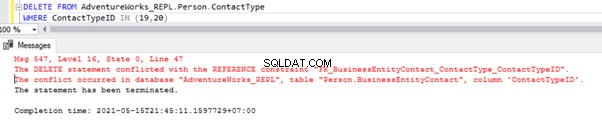
Máme odkaz na cizí klíč, který zabraňuje smazání těchto 2 záznamů z Person.ContactType stůl. Tento scénář můžeme zvládnout tak, že dočasně deaktivujeme omezení cizího klíče v podřízené tabulce. Skript je níže:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Jakmile jsou cizí klíče deaktivovány, můžeme úspěšně odstranit záznamy z Person.ContactType tabulka:
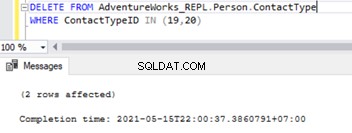
To také změnilo referenční omezení cizího klíče ve 2 tabulkách. Můžeme se pokusit simulovat problémy s replikací SQL na základě tohoto scénáře.
V našem současném scénáři víme, že Person.ContactType tabulka neměla synchronizovaná data napříč vydavatelem a odběratelem.
Věřte mi, že v málokterém produkčním prostředí provádějí vývojáři nebo správci databází nějaké opravy dat v databázi předplatitelů. stejně jako všechny změny, které jsme provedli dříve, způsobily problémy s integritou dat napříč databázemi Publisher a Subscriber ve stejné tabulce. Jako DBA potřebuji jednodušší mechanismus pro ověření těchto druhů nesrovnalostí. Jinak by byl život DBA žalostný.
Zde přichází řešení od společnosti Microsoft, které nám umožňuje ověřit nesrovnalosti v datech napříč tabulkami ve Vydavateli a Předplatiteli. Ano, tušíte správně. Je to nástroj TableDiff, o kterém jsme hovořili v předchozích článcích.
Nástroj TableDiff
Nástroj TableDiff se primárně používá v prostředích replikace. Můžeme to také použít pro jiné případy, kdy potřebujeme porovnat 2 SQL Server tabulky pro nekonvergenci. Můžeme je porovnat a identifikovat rozdíly mezi těmito 2 tabulkami. Poté nástroj pomůže synchronizovat Cíl tabulka na Zdroj tabulka generováním nezbytných skriptů INSERT/UPDATE/DELETE.
TableDiff je samostatný program tablediff.exe nainstalovaný ve výchozím nastavení na C:\Program Files\Microsoft SQL Server\130\COM, jakmile nainstalujeme komponenty replikace. Upozorňujeme, že výchozí cesta se může lišit v závislosti na instalačních parametrech SQL Server. Číslo 130 v cestě označuje verzi SQL Server (SQL Server 2016). Proto se bude lišit pro každou jinou verzi instalace SQL Server.
K obslužnému programu TableDiff můžete přistupovat prostřednictvím příkazového řádku nebo pouze z dávkových souborů. Obslužný program nemá luxusního průvodce nebo grafické uživatelské rozhraní. Podrobná syntaxe nástroje TableDiff je v článku MSDN. Náš aktuální článek se zaměřuje pouze na některé nezbytné možnosti.
Abychom mohli porovnat 2 tabulky pomocí nástroje TableDiff, musíme poskytnout povinné podrobnosti pro zdrojové a cílové tabulky, jako je název zdrojového serveru, název zdrojové databáze, název zdrojového schématu, název zdrojové tabulky, název cílového serveru, název cílové databáze, cíl Název schématu a Název cílové tabulky.
Zkusme otestovat TableDiff pomocí Person.ContactType s rozdíly mezi vydavatelem a odběratelem.
Otevřete příkazový řádek a přejděte na cestu nástroje TableDiff (pokud tato cesta není přidána do proměnných prostředí).
Chcete-li zobrazit seznam všech dostupných parametrů, zadejte příkaz „tablediff-?“ pro výpis všech dostupných možností a parametrů. Výsledky jsou níže:
Pojďme zkontrolovat osobu.Typ kontaktu tabulky napříč našimi databázemi Publisher a Subscriber spuštěním níže uvedeného příkazu:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeUpozorňujeme, že jsem neuvedl sourceuser , heslo zdroje , destinationuser a heslo cíle protože moje přihlášení do Windows má přístup k tabulkám. Pokud chcete místo ověřování systému Windows používat přihlašovací údaje SQL, výše uvedené parametry jsou povinné pro přístup k tabulkám pro porovnání . V opačném případě obdržíte chyby.
Výsledky správného provedení příkazu:
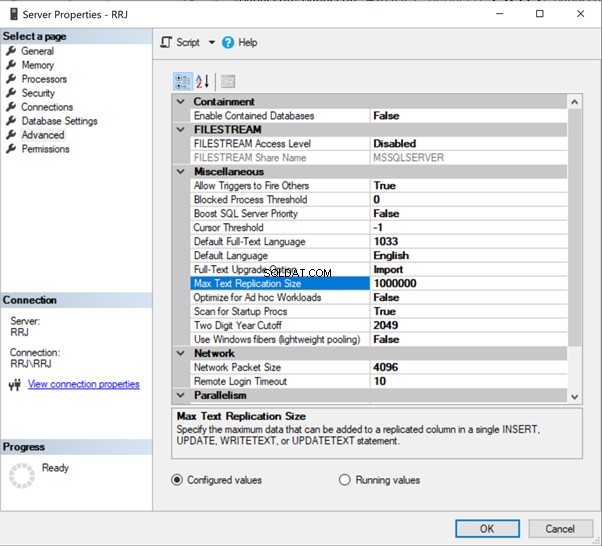
Ukazuje to, že máme 3 nesrovnalosti. Jeden je nový záznam v cílové databázi a dva záznamy nejsou v cílové databázi dostupné.
Nyní se pojďme rychle podívat na Různé možnosti dostupné pro nástroj TableDiff.
- -et – zaprotokoluje souhrn výsledků do cílové tabulky
- -dt – zruší cílovou tabulku výsledků, pokud již existuje
- -f – generuje T-SQL DML skript s příkazy INSERT/UPDATE/DELETE, aby se cílová tabulka sblížila se zdrojovou tabulkou.
- -o – název výstupního souboru, pokud je volba -f se používá ke generování souboru konvergence.
Vytvoříme konvergenční soubor s -f a -o možnosti k našemu dřívějšímu příkazu:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlKonvergenční soubor byl úspěšně vytvořen:
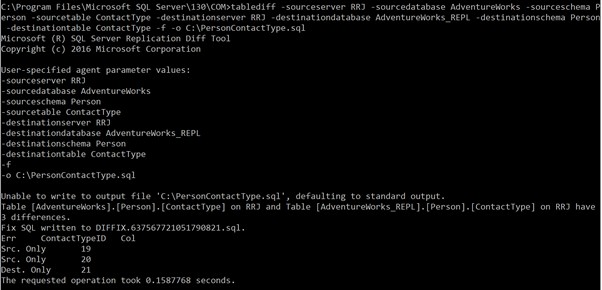
Jak vidíte, vytvoření nového souboru v kořenové složce disku C:není z bezpečnostních důvodů povoleno. Proto zobrazí chybovou zprávu a vytvoří výstupní soubor Soubor DIFFIX.*.sql ve složce nástroje TableDiff. Když tento soubor otevřeme, můžeme vidět níže uvedené podrobnosti:

Pro 2 odstraněné záznamy byly vytvořeny skripty INSERT a pro záznamy nově vložené do databáze odběratelů byly vytvořeny skripty DELETE. Nástroj se také stará o použití možností IDENTITY_INSERT, jak je požadováno pro Cíl stůl. Proto bude tento nástroj velmi užitečný, kdykoli DBA potřebuje synchronizovat dvě tabulky.
V našem případě skripty nespustím, protože tyto odchylky potřebujeme k simulaci našich problémů s replikací SQL.
Výhody nástroje TableDiff Utility
- TableDiff je bezplatný nástroj, který je dodáván jako součást instalace komponent SQL Server Replication, který se používá pro porovnávání nebo sbližování tabulek.
- Skripty pro vytváření konvergence lze vytvořit bez ručního zásahu.
Omezení nástroje TableDiff Utility
- Obslužný program TableDiff lze spustit pouze z příkazového řádku nebo dávkového souboru.
- Z příkazového řádku můžete provádět porovnání pouze jedné tabulky najednou, pokud nemáte paralelně otevřeno více příkazových výzev k porovnání několika tabulek.
- Zdrojová tabulka, kterou potřebujete porovnat pomocí obslužného programu TableDiff, vyžaduje definovaný primární klíč nebo sloupec identity nebo dostupný sloupec ROWGUID k provedení porovnání řádků. Pokud je -strict Pokud je použita možnost, cílová tabulka také vyžaduje primární klíč nebo sloupec identity nebo dostupný sloupec ROWGUID.
- Pokud zdrojová nebo cílová tabulka obsahuje sql_variant datový typ, nemůžete k porovnání použít nástroj TableDiff.
- Při spouštění obslužného programu TableDiff na tabulkách obsahujících velké záznamy lze zaznamenat problémy s výkonem, protože u těchto tabulek provede porovnání řádek po řádku.
- Konvergenční skripty vytvořené obslužným programem TableDiff neobsahují sloupce datových typů znaků BLOB, jako je varchar(max) , nvarchar(max) , varbinary(max) , text , ntext nebo obrázek sloupce a xml nebo časové razítko sloupců. Proto potřebujete alternativní přístupy ke zpracování tabulek s těmito sloupci datových typů.
I s těmito omezeními však lze obslužný program TableDiff použít v jakékoli tabulce serveru SQL pro rychlé ověření dat nebo kontrolu konvergence. Můžete si však zakoupit i dobrý nástroj třetí strany.
Nyní se podrobně podíváme na různé problémy replikace SQL.
Problémy s konfigurací
Na základě svých zkušeností jsem kategorizoval často opomíjené možnosti konfigurace replikace, které mohou vést ke kritickým problémům s replikací SQL jako Konfigurace problémy. Některé z nich jsou uvedeny níže.
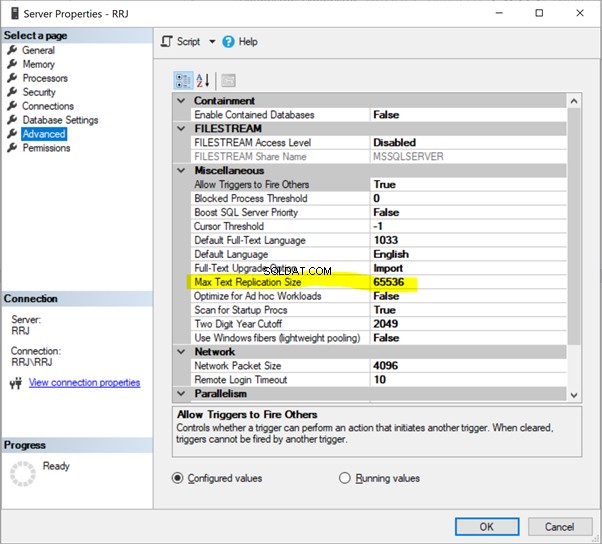
Maximální velikost replikace textu
Maximální velikost textové repliky odkazuje na Maximální velikost replikace textu v bajtech . Platí pro všechny datové typy jako char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, aobrázek .
SQL Server má výchozí možnost omezit maximální délku sloupce datového typu řetězce (v bajtech), který má být replikován jako 65536 bajtů.
Při každé konfiguraci replikace pro databázi musíme pečlivě vyhodnotit maximální velikost repliky textu. Za tímto účelem musíme zkontrolovat všechny výše uvedené sloupce datových typů a identifikovat maximální možné bajty, které budou přeneseny prostřednictvím replikace.
Změna hodnoty na -1 znamená, že neexistují žádná omezení. Doporučujeme však vyhodnotit maximální délku řetězce a nakonfigurovat tuto hodnotu.
Můžeme nakonfigurovat Max Text Repl Size pomocí SSMS nebo T-SQL.
V SSMS klikněte pravým tlačítkem na Název serveru> Vlastnosti > Pokročilé :
Stačí kliknout na 65536 jej upravit. Pro testy jsem změnil 65536 na 1000000 a kliknul na OK :
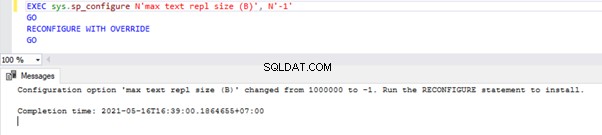
Chcete-li nakonfigurovat možnost Max Text Repl Size prostřednictvím T-SQL, otevřete nové okno dotazu a spusťte níže uvedený skript proti hlavní databázi:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Tento dotaz umožní Replication neomezit velikost výše uvedených sloupců datových typů.
Pro ověření můžeme provést SELECT na sys.configurations DMV a zkontrolujte value_in_use sloupec, jak je uvedeno níže:

Služba SQL Server Agent není nastavena na spuštění automatického režimu
Replikace se opírá o replikační agenty, kteří jsou spouštěni jako úlohy SQL Server Agent. Jakýkoli problém s některou službou SQL Server Agent Service bude mít tedy přímý dopad na funkci replikace.
Musíme se ujistit, že Start Mode SQL Server a SQL Server Agent Services jsou nastaveny na Automatic. Pokud je nastaveno na Ruční, měli bychom nakonfigurovat některá upozornění. Upozorní správce serveru nebo správce serveru, aby spustili službu SQL Server Agent Service, když se server restartuje, ať už plánovaný nebo neplánovaný.
Pokud tak neučiníte, replikace nemusí být spuštěna po dlouhou dobu, což ovlivní i ostatní úlohy SQL Server Agent.
Nemonitorované instance replikace se dostanou do stavu neinicializovaných předplatných
Podobně jako u monitorování SQL Server Agent Service hraje konfigurace Database Mail Service v jakékoli instanci SQL Server zásadní roli při včasném upozornění DBA nebo nakonfigurované osoby. Pro jakékoli selhání nebo problémy úlohy lze úlohy SQL Server Agent, jako je Log Reader Agent nebo Distribution Agent, nakonfigurovat tak, aby zasílaly upozornění DBA nebo příslušnému členovi týmu e-mailem. Selhání provádění úlohy replikačního agenta může vést k následujícím scénářům:
Neprovedení úlohy agenta Log Reader . Soubor protokolu transakcí databáze vydavatele bude znovu použit pouze po příkazu označeném pro replikaci je přečten agentem Log Reader a úspěšně odeslán do distribuční databáze. V opačném případě log_reuse_wait_desc sloupec sys.databases zobrazí hodnotu jako Replikace, což znamená, že databázový protokol nelze znovu použít, dokud úspěšně nepřenese změny do distribuční databáze. Neprovedení agenta Log Reader tedy bude neustále zvětšovat velikost souboru Transakčního protokolu databáze Publisher a budeme narážet na problémy s výkonem během úplné zálohy nebo na problémy s místem na disku v instanci databáze Publisher.
Neprovedení úlohy distribučního agenta. Úloha Agent distribuce načte data z distribuční databáze a odešle je do databáze odběratelů. Poté označí tyto záznamy k odstranění v distribuční databázi. Pokud se úloha agenta distribuce neprovádí, zvětší se velikost distribuční databáze, což způsobí problémy s výkonem celkového výkonu replikace. Ve výchozím nastavení je distribuční databáze nakonfigurována tak, aby uchovávala záznamy po dobu maximálně 0-72 hodin, jak je uvedeno ve vlastnosti Uchování transakcí níže. Pokud replikace selže déle než 72 hodin, bude odpovídající předplatné označeno jako neinicializované, což nás donutí buď překonfigurovat předplatné, nebo vygenerovat nový snímek, aby replikace opět fungovala.
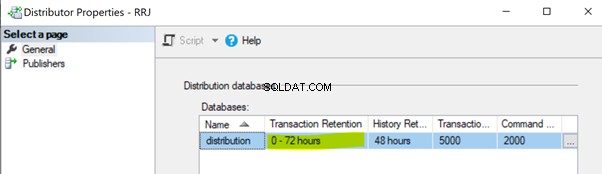
Neprovedení čištění distribuce:úloha distribuce . Úloha čištění distribuce je zodpovědná za odstranění všech replikovaných záznamů z distribuční databáze, aby byla velikost distribuční databáze pod kontrolou. Neprovedení této úlohy vede ke zvětšení velikosti distribuční databáze, což má za následek problémy s výkonem replikace.
Abychom zajistili, že nenarazíme na žádný z těchto nemonitorovaných problémů, měla by být pošta databáze nakonfigurována tak, aby hlásila všechna selhání nebo opakování úlohy příslušným členům týmu, aby mohli rychle jednat.
Známé problémy na serveru SQL Server
Některé verze SQL Server měly ve verzi RTM nebo dřívějších verzích známé problémy s replikací. Tyto problémy byly opraveny v následujících aktualizacích Service Pack nebo balíčcích CU. Proto se doporučuje použít nejnovější aktualizace Service Pack nebo balíčky CU, jakmile budou dostupné pro všechny SQL Servery po jejich otestování v prostředí QA. Přestože se jedná o obecné doporučení pro servery se systémem SQL Server, lze jej použít i pro replikaci.
Problémy s oprávněním
V prostředí s konfigurovanou transakční replikací serveru SQL Server můžeme často pozorovat problémy s oprávněními. Můžeme jim čelit během konfigurace Replikace nebo jakýchkoli činností údržby na instancích databáze Vydavatele, Distributora nebo Předplatitele. Výsledkem je ztráta přihlašovacích údajů nebo oprávnění. Podívejme se nyní na některé časté problémy s oprávněními související s replikací.
Problémy s oprávněním k úlohám SQL Server Agent
Všichni agenti replikace používají úlohy SQL Server Agent. Každá úloha agenta SQL Server související se snímkem nebo agentem čtečky protokolů nebo distribucí se provádí pod některými přihlašovacími pověřeními Windows nebo SQL, jak je uvedeno níže:
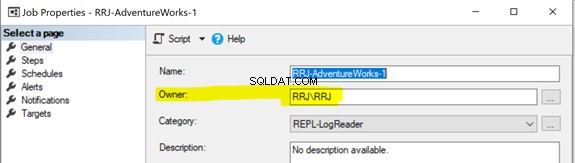
Chcete-li spustit úlohu SQL Server Agent, musíte vlastnit buď SQLAgentOperatorRole ke spuštění všech úloh nebo buď SQLAgentUserRole nebo SQLAgentReaderRole začít pracovat, které vlastníte. Pokud se některé úlohy nepodařilo správně spustit, zkontrolujte, zda vlastník úlohy má potřebná práva k provedení této úlohy.
Pověření úlohy agenta snímku nemá přístup k cestě ke složce snímku
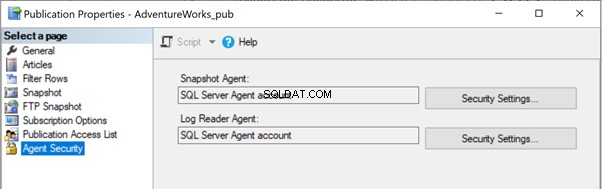
V našich předchozích článcích jsme si všimli, že spuštění agenta Snapshot vytvoří snímek článků v cestě místní nebo sdílené složky, který bude šířen do databáze odběratelů prostřednictvím agenta distribuce. Umístění cesty snímku lze identifikovat v části Vlastnosti publikace > Snímek :
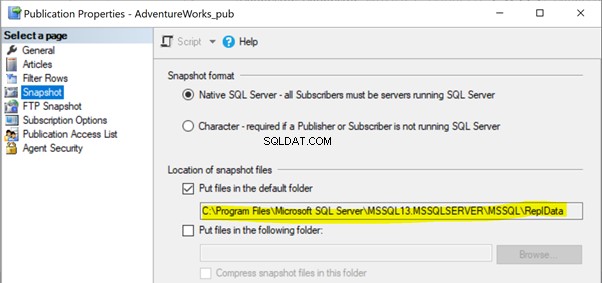
Pokud agent Snapshot nemá přístup k tomuto umístění souborů Snapshot, může se zobrazit chyba:
Přístup k cestě ‚C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\YYYYMMDDHHMISS\' je odepřen.
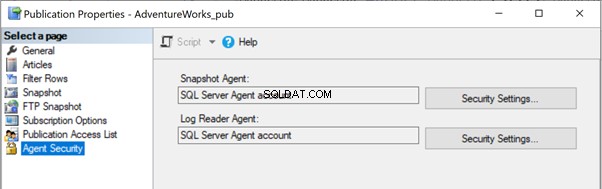
Chcete-li problém vyřešit, je lepší udělit úplný přístup k cestě ke složce C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ pro účet, pod kterým se provádí Snapshot Agent. V naší konfiguraci používáme účet SQL Server Agent a služba SQL Server Agent Service běží pod účtem RRJ\RRJ.
Pověření úlohy agenta Log Reader se nemůže připojit k databázi vydavatele/distribuce
Log Reader Agent se připojí k databázi vydavatele a spustí sp_replcmds postup pro vyhledání transakcí, které jsou označeny pro replikaci, z transakčních protokolů databáze Publisher.
Pokud není vlastník databáze Publisher databáze správně nastaven, mohou se zobrazit následující chyby:
Proces nemohl spustit „sp_replcmds“ na „RRJ.
Nebo
Nelze spustit jako hlavní objekt databáze, protože principál „dbo“ neexistuje, tento typ objektu nelze zosobnit nebo nemáte oprávnění.
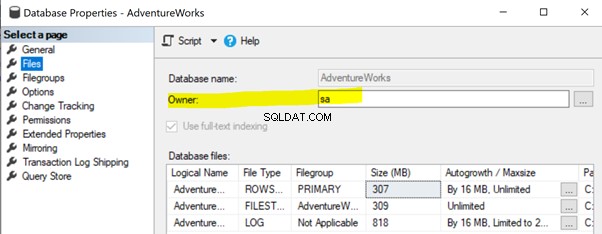
Chcete-li tento problém vyřešit, ujistěte se, že vlastnost vlastníka databáze databáze Publisher je nastavena na sa nebo jiný platný účet (viz níže).
Klikněte pravým tlačítkem na Vydavatel databáze (AdventureWorks )> Vlastnosti > Soubory . Ujistěte se, že Vlastník pole je nastaveno na sa nebo jakékoli platné přihlašovací údaje a není prázdné .
Pokud se při připojování k vydavatelské nebo distribuční databázi vyskytnou nějaké problémy s oprávněními, zkontrolujte přihlašovací údaje používané pro agenta Log Reader Agent a udělte mu oprávnění k přístupu k těmto databázím.
Pověření úlohy agenta distribuce se nemůže připojit k databázi distribuce/předplatitelů
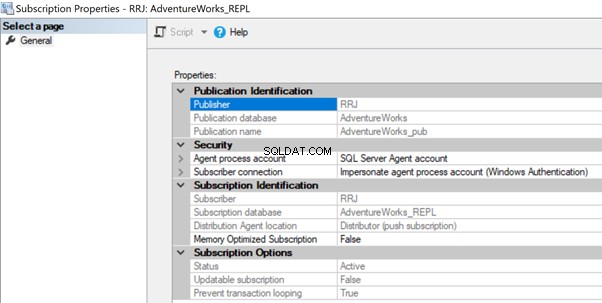
Agent distribuce může mít problémy s oprávněním, pokud účet nemá povolen přístup k distribuční databázi nebo připojení k databázi předplatitelů. V tomto případě se mohou zobrazit následující chyby:
Nelze spustit provádění kroku 2 (důvod:Chyba při ověřování proxy RRJ\RRJ, systémová chyba:uživatelské jméno nebo heslo je nesprávné.)
Proces se nemohl připojit k odběrateli „RRJ.
Přihlášení uživatele „RRJ\RRJ“ se nezdařilo.
Chcete-li to vyřešit, zkontrolujte účet používaný ve vlastnostech předplatného a ujistěte se, že má potřebná oprávnění pro připojení k databázi Distribuce nebo Subscriber.
Problémy s připojením
Transakční replikaci obvykle konfigurujeme mezi servery v rámci stejné sítě nebo napříč geograficky distribuovanými lokalitami. Pokud je distribuční databáze umístěna na vyhrazeném serveru kromě vydavatele nebo předplatitele, stává se náchylnou ke ztrátám síťových paketů – problémy s připojením.
V případě takových problémů mohou agenti replikace (čtečka protokolů nebo agent distribuce) hlásit níže uvedené chyby:
Server vydavatele nebyl nalezen nebo nebyl přístupný
Distribuční server nebyl nalezen nebo nebyl přístupný
Server předplatitele nebyl nalezen nebo nebyl přístupný
Abychom tyto problémy vyřešili, můžeme se pokusit připojit k databázi vydavatele, distributora nebo předplatitele v SSMS, abychom zkontrolovali, zda se dokážeme připojit k těmto instancím SQL Serveru bez problémů či nikoli.
Pokud k problémům s připojením dochází často, můžeme zkusit ping na server nepřetržitě, abychom identifikovali případné ztráty paketů. Musíme také spolupracovat s nezbytnými členy týmu, abychom tyto problémy vyřešili a zprovoznili server, aby mohla replikace obnovit přenos dat.
Problémy s integritou dat
Vzhledem k tomu, že transakční replikace je jednosměrný mechanismus, jakékoli změny dat, ke kterým dojde u předplatitele (ručně nebo z aplikace), se na vydavateli neprojeví. Může to vést k rozdílům v datech mezi vydavatelem a odběratelem.
Pojďme se podívat na problémy související s integritou dat a podívat se, jak je vyřešit. Všimněte si, že jsme vložili záznam do Person.ContactType a odstranil 2 záznamy z Person.ContactType tabulky v databázi předplatitelů. Tyto 3 záznamy použijeme k nalezení chyb.
Chyby porušení primárního klíče nebo jedinečného klíče
Chystám se otestovat záznam INSERT na Person.ContactType stůl. Vložíme tento záznam do databáze vydavatele a uvidíme, co se stane:
Spusťte Replication Monitor a uvidíte, jak to jde. Dostaneme chybu:
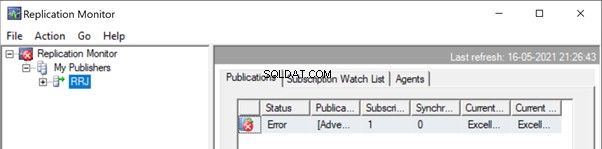
Rozbalení Vydavatel a Publikace , získáme následující podrobnosti:
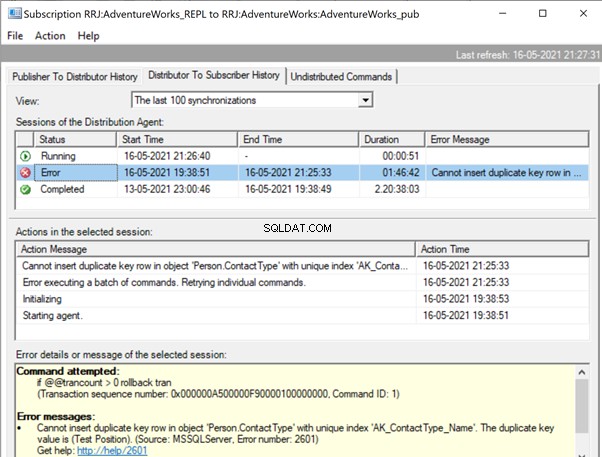
Pokud jsme nakonfigurovali výstrahy replikace a přiřadili příslušné osoby k přijímání výstrah e-mailem, obdržíme příslušná e-mailová upozornění s chybovou zprávou:Nelze vložit duplicitní řádek klíče do objektu 'Person.ContactType' s jedinečným indexem 'AK_ContactType_Name ' . Duplicitní hodnota klíče je (Testovací pozice). (Zdroj:MSSQLServer, číslo chyby:2601)
Chcete-li vyřešit problém týkající se porušení jedinečného klíče nebo problémů s primárním klíčem, máme několik možností:
- Analyzujte, proč k této chybě došlo, jak byl záznam dostupný v databázi odběratelů a kdo jej z jakých důvodů vložil. Zjistěte, zda to bylo nutné nebo ne.
- Přidejte přeskočovací chyby parametr do profilu distribučního agenta přeskočit Chyba číslo 2601 nebo Chyba číslo 2627 v případě porušení primárního klíče.
V našem případě jsme záměrně vložili data, abychom tuto chybu obdrželi. Chcete-li tento problém vyřešit, odstraňte ručně vložený záznam, abyste mohli pokračovat v replikaci změn přijatých od vydavatele.
DELETE from Person.ContactType
where ContactTypeID = 21
Abych prostudoval další možnosti a porovnal rozdíly mezi těmito dvěma přístupy, přeskakuji první možnost (která je efektivní a doporučená) a přejdu k druhé možnosti přidáním -skiperrors parametr k úloze Distribučního agenta.
Můžeme to implementovat úpravou Úlohy distribučního agenta > Kroky > klikněte na 2 Job Step s názvem Run Agent > klikněte na Upravit pro zobrazení dostupného příkazu:
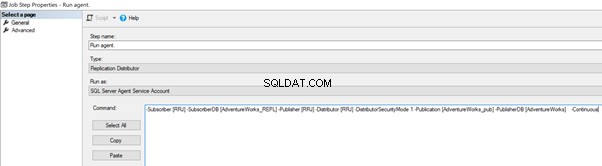
Nyní přidejte -SkipErrors 2601 klíčové slovo na konci (2601 je číslo chyby – jakékoli číslo chyby obdržené v rámci replikace můžeme přeskočit) a klikněte na OK .
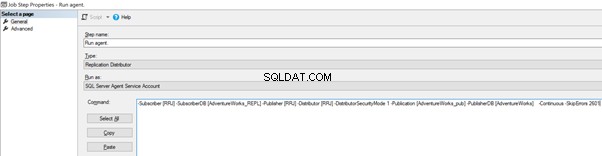
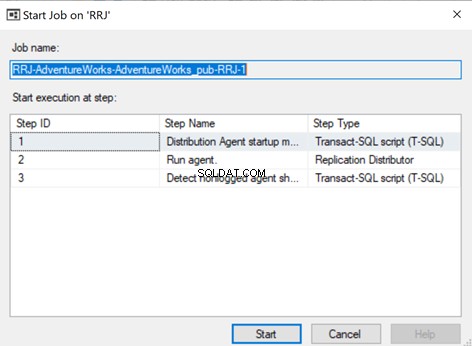
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
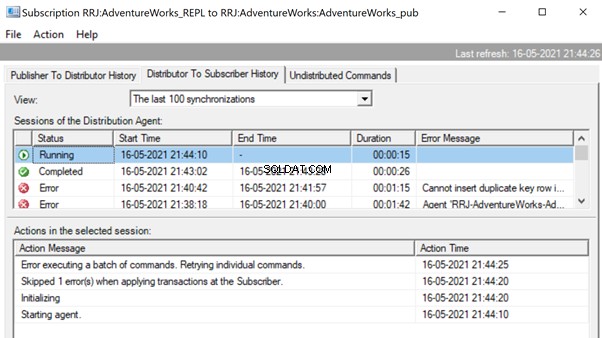
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
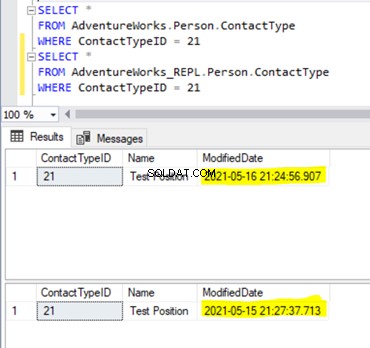
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors příkaz.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
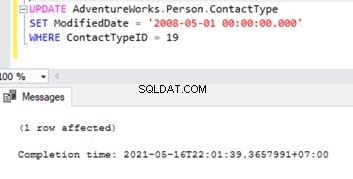
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
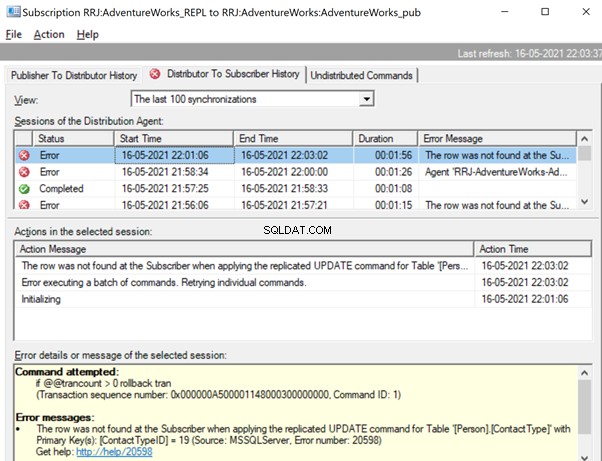
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors volba. Instead, we’ll apply the INSERT approach.
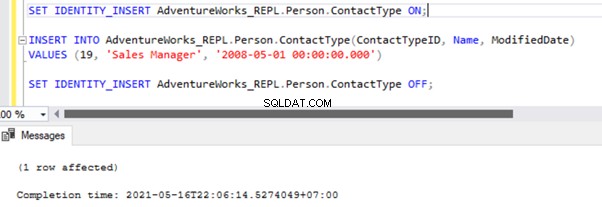
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
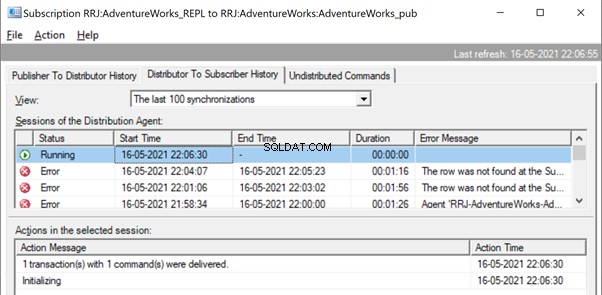
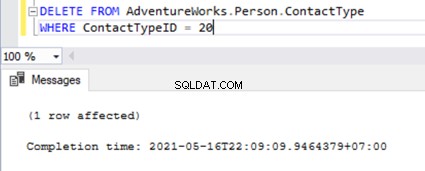
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
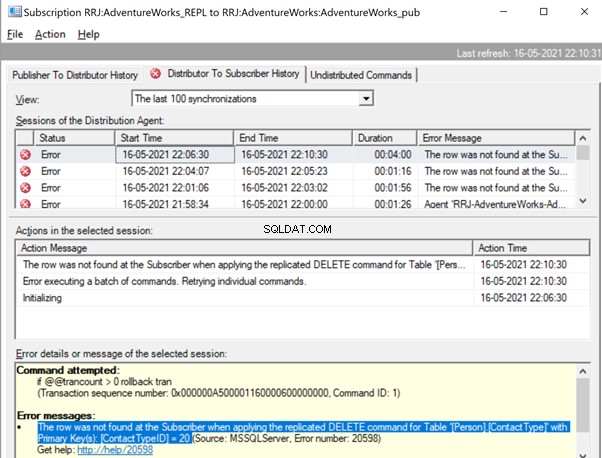
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Závěr
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.