Úvod
Tabulka je logická struktura. Když vytváříte tabulku, obvykle by vám bylo jedno, na kterých jednotkách je ve vrstvě úložiště umístěna. Pokud jste však správcem databáze, mohou být tyto znalosti nezbytné, pokud potřebujete přesunout určité části databáze do alternativního úložiště nebo svazku. Potom můžete chtít, aby byly určité tabulky na konkrétním svazku nebo sadě disků.
Souborové skupiny v SQL Serveru nabízejí tuto vrstvu abstrakce, která nám umožňuje řídit fyzické umístění našich logických struktur – tabulek, indexů atd.
Skupiny souborů
Skupina souborů je logická struktura pro seskupování datových souborů na serveru SQL Server. Pokud vytvoříme skupinu souborů a přidružíme ji k sadě datových souborů, jakýkoli logický objekt vytvořený v této skupině souborů bude fyzicky umístěn v této sadě fyzických souborů.
Primárním účelem takového fyzického seskupování souborů je alokace dat a umístění dat. Například chceme, aby naše transakční data byla uložena na jedné sadě rychlých disků. Zároveň potřebujeme historická data uložená na jiné sadě levnějších disků. V takovém scénáři bychom vytvořili Tran tabulka ve skupině souborů TXN a TranHist tabulky v jiné skupině souborů HIST. Dále v tomto článku uvidíme, jak to znamená mít data na různých discích.
Vytváření skupin souborů
Syntaxe pro vytváření skupin souborů je uvedena v Výpisu 1 . Poznámka :Kontext databáze je hlavní databáze. Při vydávání příkazů měníme databázi DB2 tím, že do ní přidáváme nové skupiny souborů. V podstatě jsou tyto skupiny souborů v tomto bodě pouze logické konstrukce. Neobsahují žádná data.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Přidávání souborů do skupin souborů
Dalším krokem je přidání souboru do každé skupiny souborů. Můžeme přidat více než jeden soubor, ale pro demonstrační účely je to jednoduché. Všimněte si, že každý soubor je zcela na jiné jednotce a syntaxe nám umožňuje určit zamýšlenou skupinu souborů.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Vytváření tabulek do skupin souborů
Zde zajistíme, aby tabulky byly na požadovaných discích. Syntaxe pro vytváření tabulek nám umožňuje zadat požadovanou skupinu souborů.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Když uděláme krok zpět, poznamenáváme, že jsme nyní dosáhli následujícího:
- Vytvořeny dvě skupiny souborů.
- Určení datových souborů (a disků) spojených s každou skupinou souborů.
- Určení tabulek přidružených ke každé skupině souborů.
V podstatě je skupina souborů abstrakce vrstva .
Kontrola, na kterých skupinách souborů jsou naše tabulky
Abychom zjistili, do jaké skupiny souborů každá tabulka patří, spustíme kód ve výpisu 4. Používáme dvě hlavní zobrazení systémového katalogu:sys.indexes a sys.data_spaces . sys.data_spaces zobrazení katalogu obsahuje informace o skupinách souborů a oddílech a hlavních logických strukturách, kde jsou uloženy tabulky a indexy.
Poznámka:Nepoužili jsme sys.tables . SQL Server spojuje indexy v tabulce s datovými prostory spíše než tabulkami, jak bychom si mohli intuitivně myslet.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
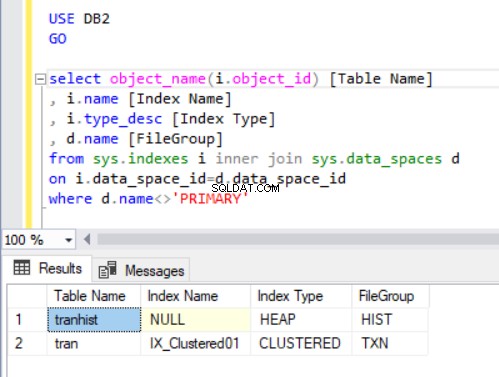
Výstup dotazu ve výpisu 4 zobrazuje dvě tabulky, které jsme právě vytvořili. Všimněte si, že tranhist tabulka nemá index. Přesto se zobrazí ve výsledkové sadě označené jako hromada .
hromada je tabulka, která nemá žádný seskupený index určující data objednávky fyzicky uložená v tabulce. V tabulce může být pouze jeden seskupený index.
Vyplnění tabulky Tran
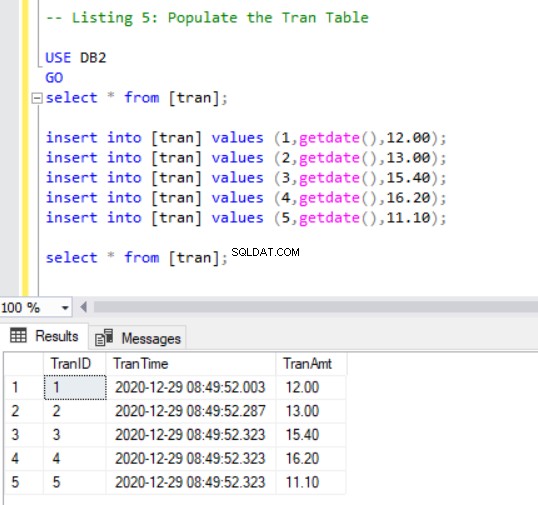
Nyní musíme do tranu přidat několik záznamů tabulky pomocí následujícího kódu:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Přesun tabulky do jiné skupiny souborů
Chcete-li přesunout tran tabulky do jiné skupiny souborů, potřebujeme pouze znovu vytvořit seskupený index a při provádění této přestavby určete novou skupinu souborů. Výpis 5 ukazuje tento přístup.
Provedeme dva kroky:nejprve index zrušíme a poté jej znovu vytvoříme. Mezitím zkontrolujeme, zda data a umístění dvou tabulek, které jsme vytvořili dříve, zůstávají nedotčeny.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Vypuštěním seskupeného indexu z tran tabulku, převedli jsme ji na hromadu :
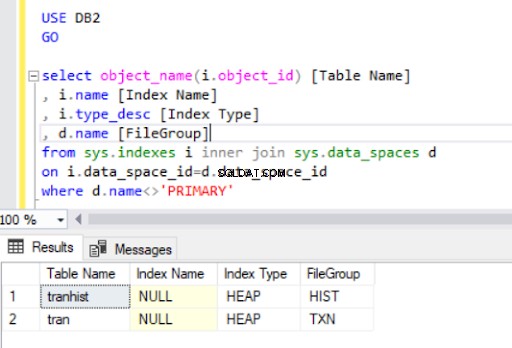
Když znovu vytvoříme seskupený index, zobrazí se také ve výstupu výpisu 4.
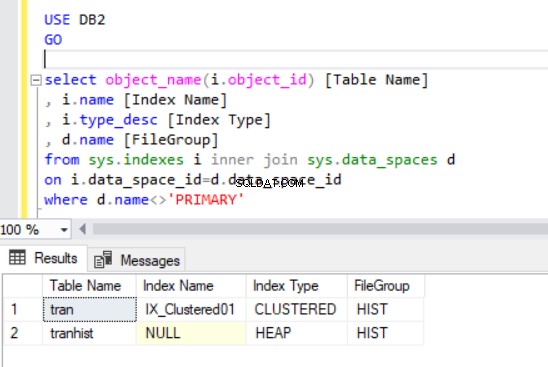
Nyní máme tran tabulky ve skupině souborů HIST.
Závěr
Tento článek demonstroval vztah mezi tabulkami, indexy, soubory a skupinami souborů z hlediska ukládání dat našeho serveru SQL Server. Vysvětlili jsme také přesun tabulky z jedné skupiny souborů do druhé opětovným vytvořením seskupeného indexu.
Tato dovednost bude užitečná, když potřebujete migrovat data na nové úložiště (rychlejší disky nebo pomalejší disky pro archivaci). V pokročilejších scénářích můžete použít skupiny souborů ke správě životního cyklu dat implementací oddílů tabulky.
Odkazy
- Databázové soubory a skupiny souborů
- Vypnutí oddílů tabulky – návod