U všech hlavních produktů RDBMS Primární klíč v omezeních SQL má zásadní roli. Jednoznačně identifikují záznamy přítomné v tabulce. Proto bychom měli při návrhu tabulky pečlivě vybírat server Primary Keys, abychom zlepšili výkon.
V tomto článku se dozvíme, co je to omezení primárního klíče. Také uvidíme, jak vytvořit, upravit nebo zrušit omezení primárních klíčů.
Omezení serveru SQL
V SQL Server Omezení jsou pravidla, která upravují zadávání údajů do potřebných sloupců. Omezení vynucují přesnost dat a to, jak tato data odpovídají obchodním požadavkům. Také díky nim jsou data pro koncové uživatele spolehlivá. Proto je důležité během fáze návrhu identifikovat správná omezení databáze nebo schématu tabulky.
SQL Server podporuje následující typy omezení k vynucení integrity dat:
Primární klíčová omezení jsou vytvořeny na jednom sloupci nebo kombinaci sloupců, aby byla zajištěna jedinečnost záznamů a rychlejší identifikace záznamů. Zapojené sloupce by neměly obsahovat hodnoty NULL. Vlastnost NOT NULL by tedy měla být definována ve sloupcích.
Zahraniční klíčová omezení jsou vytvořeny na jednom sloupci nebo kombinaci sloupců za účelem vytvoření vztahu mezi dvěma tabulkami a vynucení dat přítomných v jedné tabulce do druhé. V ideálním případě se sloupce tabulky, kde potřebujeme vynutit data s omezeními cizího klíče, odkazují na zdrojovou tabulku s primárním klíčem v SQL nebo omezením jedinečného klíče. Jinými slovy, do cílové tabulky lze vložit nebo aktualizovat pouze záznamy dostupné v omezeních primárního nebo jedinečného klíče zdrojové tabulky.
Unikátní klíčová omezení jsou vytvořeny na jednom sloupci nebo kombinaci sloupců, aby byla zajištěna jedinečnost napříč daty sloupce. Jsou podobná omezením primárního klíče s jedinou změnou. Rozdíl mezi primárním klíčem a omezením jedinečného klíče je v tom, že poslední klíč lze vytvořit na možnost Null sloupce a povolit jeden záznam hodnoty NULL v jeho sloupci.
Zkontrolujte omezení jsou vytvořeny na jednom sloupci nebo kombinaci sloupců omezením akceptovaných datových hodnot pro příslušné sloupce prostřednictvím logického výrazu. Mezi cizím klíčem a omezením kontroly je rozdíl. Cizí klíč vynucuje integritu dat kontrolou dat z primárního nebo jedinečného klíče jiné tabulky. Kontrolní omezení to však provádí pomocí logického výrazu.
Nyní si projdeme omezení primárního klíče.
Omezení primárního klíče
Omezení primárního klíče vynucuje jedinečnost jednoho sloupce nebo kombinace sloupců bez jakýchkoli hodnot NULL uvnitř příslušných sloupců.
K vynucení jedinečnosti vytvoří SQL Server jedinečný seskupený index ve sloupcích, kde byly vytvořeny primární klíče. Pokud existují nějaké existující seskupené indexy, SQL Server vytvoří v tabulce pro primární klíč jedinečný index bez seskupení.
Podívejme se, jak vytváříme, upravujeme, pouštíme, deaktivujeme nebo povolujeme primární klíče v tabulce pomocí skriptů T-SQL.
Vytvořte primární klíč
Primární klíče můžeme na tabulce vytvořit buď během vytváření tabulky, nebo až poté. Syntaxe se pro tyto scénáře mírně liší.
Vytvoření primárního klíče během vytváření tabulky
Syntaxe je níže:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Vytvořme tabulku s názvem Zaměstnanci v Lidských zdrojích schéma pro testovací účely pomocí níže uvedeného skriptu:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
Úspěšně jsme vytvořili HumanResources.Employees tabulky na AdventureWorks databáze:
Vidíme, že seskupený index byl vytvořen v tabulce odpovídající názvu primárního klíče, jak je zvýrazněno výše.
Pusťme tabulku pomocí níže uvedeného skriptu a zkuste to znovu s novou syntaxí.
DROP TABLE HumanResources.EmployeesVytvoření primárního klíče v SQL v tabulce s uživatelem definovaným názvem primárního klíče PK_Employees , použijte níže uvedenou syntaxi:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
Vytvořili jsme HumanResources.Employees tabulka s názvem primárního klíče PK_Employees :
Vytvoření primárního klíče po vytvoření tabulky
Někdy vývojáři nebo správci databází zapomenou na primární klíče a vytvoří tabulky bez nich. Je však možné vytvořit primární klíč na existujících tabulkách.
Vynechme HumanResources.Employees tabulku a znovu ji vytvořte pomocí níže uvedeného skriptu:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
Když tento skript úspěšně spustíte, uvidíme HumanResources.Employees tabulka vytvořená bez primárních klíčů nebo indexů:

Chcete-li vytvořit primární klíč s názvem PK_Employees v této tabulce použijte níže uvedenou syntaxi:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
Spuštění tohoto skriptu vytvoří primární klíč na naší tabulce:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Vytvoření primárního klíče ve více sloupcích
V našich příkladech jsme vytvořili primární klíče na jednotlivých sloupcích. Pokud chceme vytvořit primární klíče ve více sloupcích, potřebujeme jinou syntaxi.
Chcete-li přidat více sloupců jako součást primárního klíče, musíme jednoduše přidat hodnoty názvů sloupců oddělené čárkami, které by měly být součástí primárního klíče.
Primární klíč během vytváření tabulky
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Primární klíč po vytvoření tabulky
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Zrušte primární klíč
K odstranění primárního klíče používáme níže uvedenou syntaxi. Nezáleží na tom, zda byl primární klíč v jednom nebo více sloupcích.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
Chcete-li zrušit omezení primárního klíče na HumanResources.Employees tabulky, použijte níže uvedený skript:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
Vypuštěním primárního klíče odstraníte primární klíče i klastrované nebo neklastrované indexy vytvořené spolu s vytvořením primárního klíče:
Upravit primární klíč
V SQL Server neexistují žádné přímé příkazy pro úpravu primárních klíčů. Potřebujeme odstranit existující primární klíč a znovu jej vytvořit s nezbytnými úpravami. Kroky pro úpravu primárního klíče jsou tedy:
- Zrušte stávající primární klíč.
- Vytvořte nové primární klíče s nezbytnými změnami.
Zakázat/Povolit primární klíč
Při hromadném načítání tabulky s mnoha záznamy deaktivujte primární klíč a povolte jej zpět pro lepší výkon. Kroky jsou uvedeny níže:
Deaktivujte stávající primární klíč pomocí níže uvedené syntaxe:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;Chcete-li deaktivovat primární klíč na HumanResources.Employees tabulka, skript je:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Povolit existující primární klíče, které jsou ve stavu deaktivace. Potřebujeme PŘESTAVIT index pomocí níže uvedené syntaxe:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;Chcete-li povolit primární klíč na HumanResources.Employees tabulky, použijte následující skript:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
Mýty o primárním klíči
Mnoho lidí je zmateno níže uvedenými mýty souvisejícími s primárními klíči v SQL Server.
- Tabulka s primárním klíčem není tabulka haldy
- Primární klíče mají seskupený index a data seřazená ve fyzickém pořadí
Pojďme si je vyjasnit.
Tabulka s primárním klíčem není tabulka haldy
Než se ponoříme hlouběji, zrevidujme definici primárního klíče a tabulky haldy.
Primární klíč vytvoří seskupený index v tabulce, pokud tam nejsou k dispozici žádné jiné seskupené indexy. Tabulka bez seskupeného indexu bude tabulkou haldy.
Na základě těchto definic můžeme pochopit, že primární klíč vytváří seskupený index pouze v případě, že v tabulce nejsou žádné jiné seskupené indexy. Pokud existují nějaké seskupené indexy, vytvoření primárního klíče vytvoří v tabulce neklastrovaný index odpovídající primárnímu klíči.
Pojďme si to ověřit vypuštěním HumanResources.Employees Tabulka a její opětovné vytvoření:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
Pro Primární klíč můžeme zadat volbu indexu NEZAHRNUTÝ (viz výše). Byla vytvořena tabulka s jedinečným, neseskupeným indexem pro primární klíč PK_Employees .
Tato tabulka je tedy tabulkou haldy, i když má primární klíč.
Podívejme se, zda SQL Server může vytvořit index bez klastrů pro primární klíč, pokud neurčíme klíčové slovo Non klastr během vytváření primárního klíče. Použijte níže uvedený skript:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
Zde jsme vytvořili seskupený index samostatně před vytvořením primárního klíče. A tabulka může mít pouze jeden seskupený index. Proto SQL Server vytvořil primární klíč jako jedinečný index bez clusterů. Právě teď není tabulka tabulkou haldy, protože má seskupený index.
Pokud bych si to rozmyslel a vypustil seskupený index na First_Name a Příjmení sloupce pomocí níže uvedeného skriptu:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
Seskupený index jsme úspěšně zrušili. The HumanResources.Employees tabulka je tabulka haldy, i když máme v tabulce k dispozici primární klíč:
To odstraňuje mýtus, že tabulka s primárním klíčem může být tabulkou haldy, pokud v tabulce nejsou k dispozici žádné seskupené indexy.
Primární klíč bude mít seskupený index a data seřazená ve fyzickém pořadí
Jak jsme se dozvěděli z předchozího příkladu, primární klíč v SQL může mít index bez klastrů. V takovém případě by záznamy nebyly seřazeny ve fyzickém pořadí.
Ověřme tabulku se seskupeným indexem na primárním klíči. Zkontrolujeme, zda třídí záznamy ve fyzickém pořadí.
Znovu vytvořte HumanResources.Employees tabulka s minimálním počtem sloupců a odstraněnou vlastností IDENTITY pro Employee_ID sloupec:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Nyní, když jsme vytvořili tabulku bez primárního klíče nebo seskupeného indexu, můžeme VLOŽIT 3 záznamy v nesetříděném pořadí pro Id_zaměstnance sloupec:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Vyberme z HumanResources.Employees tabulka:
SELECT *
FROM HumanResources.Employees
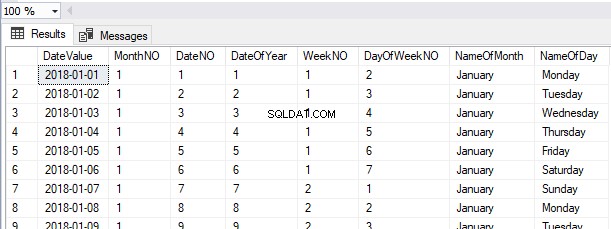
V tuto chvíli vidíme záznamy načtené ve stejném pořadí jako záznamy vložené z tabulky haldy.
Pojďme vytvořit primární klíč v této tabulce haldy a uvidíme, zda to má nějaký dopad na příkaz SELECT:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

Po vytvoření primárního klíče můžeme vidět, že příkaz SELECT načítal záznamy ve vzestupném pořadí podle ID_zaměstnance (sloupec Primární klíč). Je to kvůli klastrovanému indexu na Employee_Id .
Pokud je primární klíč vytvořen s možností bez klastrů, data tabulky nebudou řazena podle sloupce Primární klíč.
Pokud délka jednoho záznamu v tabulce přesáhne 4030 bajtů, na stránku se vejde pouze jeden záznam. Clusterový index zajišťuje, že stránky jsou ve fyzickém pořadí.
Stránka je základní jednotkou úložiště datových souborů serveru SQL Server o velikosti 8 kB (8192 bajtů). Pouze 8060 bajtů této jednotky je použitelných pro ukládání dat. Zbývající částka je určena pro záhlaví stránek a další interní prvky.
Tipy pro výběr primárních klíčových sloupců
- Celočíselné sloupce s datovým typem jsou nejvhodnější pro sloupce s primárním klíčem, protože zabírají menší úložiště a mohou pomoci rychleji získávat data.
- Vzhledem k tomu, že sloupce primárního klíče mají ve výchozím nastavení seskupený index, použijte možnost IDENTITY pro sloupce typu dat typu celočíselné, aby se nové hodnoty generovaly v přírůstkovém pořadí.
- Místo vytváření primárního klíče pro více sloupců vytvořte nový celočíselný sloupec s definovanou vlastností IDENTITY. Pro lepší výkon také vytvořte jedinečný index pro více sloupců, které byly původně identifikovány.
- Snažte se vyhnout sloupcům s datovým typem řetězce, jako je varchar, nvarchar atd. U těchto datových typů nemůžeme zaručit sekvenční přírůstek dat. Může to ovlivnit výkon INSERT v těchto sloupcích.
- Jako primární klíče vyberte sloupce, ve kterých se hodnoty nebudou aktualizovat. Pokud se například hodnota primárního klíče může změnit z 5 na 1000, je třeba aktualizovat B-strom spojený s seskupeným indexem, což má za následek mírné snížení výkonu.
- Pokud je třeba jako sloupce primárního klíče vybrat sloupce s datovým typem řetězce, zajistěte, aby délka sloupců s datovým typem varchar nebo nvarchar zůstala malá pro lepší výkon.
Závěr
Prošli jsme základy omezení dostupných na serveru SQL Server. Podrobně jsme prozkoumali omezení primárního klíče a naučili jsme se, jak vytvořit, zrušit, upravit, zakázat a znovu vytvořit primární klíče. Kromě toho jsme pomocí příkladů objasnili některé oblíbené mýty o primárních klíčích.
Zůstaňte naladěni na další článek!