Je to dobré, ale někdy to může být špatné.
Sniffing parametrů spočívá v tom, že optimalizátor dotazů používá hodnotu poskytnutého parametru ke zjištění nejlepšího možného plánu dotazů. Jednou z mnoha možností, která je docela snadno pochopitelná, je, zda by se měla pro získání hodnot naskenovat celá tabulka, nebo zda to bude rychlejší pomocí hledání indexu. Pokud je hodnota ve vašem parametru vysoce selektivní, optimalizátor pravděpodobně vytvoří plán dotazů s hledáním, a pokud tomu tak není, dotaz prohledá vaši tabulku.
Plán dotazů je pak uložen do mezipaměti a znovu použit pro po sobě jdoucí dotazy, které mají různé hodnoty. Špatná část sniffování parametrů je, když plán uložený v mezipaměti není nejlepší volbou pro jednu z těchto hodnot.
Ukázková data:
create table T
(
ID int identity primary key,
Value int not null,
AnotherValue int null
);
create index IX_T_Value on T(Value);
insert into T(Value) values(1);
insert into T(Value)
select 2
from sys.all_objects;
T je tabulka s několika tisíci řádky s neshlukovaným indexem na hodnotě. Existuje jeden řádek s hodnotou 1 a zbytek má hodnotu 2 .
Ukázkový dotaz:
select *
from T
where Value = @Value;
Možnosti, které zde má optimalizátor dotazů, jsou buď provést Clustered Index Scan a zkontrolovat klauzuli where u každého řádku, nebo použít Index Seek k vyhledání řádků, které se shodují, a poté provést vyhledávání klíčů, abyste získali hodnoty ze sloupců požadovaných v seznam sloupců.
Když je načtená hodnota 1 plán dotazů bude vypadat takto:

A když je načtená hodnota 2 bude to vypadat takto:
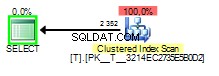
Špatná část sniffování parametrů v tomto případě nastane, když je plán dotazů vytvořen pomocí sniffování 1 ale proveden později s hodnotou 2 .
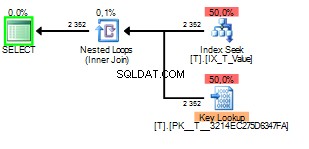
Můžete vidět, že vyhledávání klíčů bylo provedeno 2352krát. Skenování by bylo jednoznačně lepší volbou.
Abych to shrnul, řekl bych, že sniffování parametrů je dobrá věc, kterou byste se měli pokusit provést co nejvíce pomocí parametrů ve svých dotazech. Někdy se to může pokazit a v těchto případech je to s největší pravděpodobností kvůli zkresleným datům, která si zahrávají s vašimi statistikami.
Aktualizace:
Zde je dotaz na několik dmv, které můžete použít k nalezení toho, jaké dotazy jsou ve vašem systému nejdražší. Změňte objednávku na klauzuli a použijte různá kritéria pro to, co hledáte. Myslím, že TotalDuration je dobré místo, kde začít.
set transaction isolation level read uncommitted;
select top(10)
PlanCreated = qs.creation_time,
ObjectName = object_name(st.objectid),
QueryPlan = cast(qp.query_plan as xml),
QueryText = substring(st.text, 1 + (qs.statement_start_offset / 2), 1 + ((isnull(nullif(qs.statement_end_offset, -1), datalength(st.text)) - qs.statement_start_offset) / 2)),
ExecutionCount = qs.execution_count,
TotalRW = qs.total_logical_reads + qs.total_logical_writes,
AvgRW = (qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count,
TotalDurationMS = qs.total_elapsed_time / 1000,
AvgDurationMS = qs.total_elapsed_time / qs.execution_count / 1000,
TotalCPUMS = qs.total_worker_time / 1000,
AvgCPUMS = qs.total_worker_time / qs.execution_count / 1000,
TotalCLRMS = qs.total_clr_time / 1000,
AvgCLRMS = qs.total_clr_time / qs.execution_count / 1000,
TotalRows = qs.total_rows,
AvgRows = qs.total_rows / qs.execution_count
from sys.dm_exec_query_stats as qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) as st
cross apply sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) as qp
--order by ExecutionCount desc
--order by TotalRW desc
order by TotalDurationMS desc
--order by AvgDurationMS desc
;