Benjamin Nevarez je nezávislý konzultant se sídlem v Los Angeles v Kalifornii, který se specializuje na ladění a optimalizaci dotazů SQL Server. Je autorem „SQL Server 2014 Query Tuning &Optimization“ a „Inside the SQL Server Query Optimizer“ a spoluautorem „SQL Server 2012 Internals“. S více než 20 lety zkušeností v oblasti relačních databází byl Benjamin také řečníkem na mnoha konferencích SQL Server, včetně PASS Summit, SQL Server Connections a SQLBits. Benjaminův blog lze nalézt na https://www.benjaminnevarez.com a lze jej také kontaktovat e-mailem na adrese admin na adrese benjaminnevarez dot com a na twitteru na adrese @BenjaminNevarez.
Zatímco většina informací, blogů a dokumentace o SQL Server 2014 se soustředila na Hekaton a další nové funkce, o novém odhadu mohutnosti nebylo poskytnuto mnoho podrobností. Aktuálně o tom BOL mluví pouze nepřímo v sekci Co je nového (databázový stroj) s tím, že SQL Server 2014 „zahrnuje podstatná vylepšení komponenty, která vytváří a optimalizuje plány dotazů“ a ALTER DATABASE příkaz ukazuje, jak povolit nebo zakázat jeho chování. Naštěstí můžeme získat nějaké další informace přečtením výzkumné práce Testing Cardinality Estimation Models in SQL Server od Campbell Fraser et al. Přestože se tento článek zaměřuje na proces zajišťování kvality nového modelu odhadu, nabízí také základní úvod do nového estimátoru mohutnosti a motivaci jeho přepracování.
Co je tedy odhad mohutnosti? Odhad mohutnosti je komponenta dotazovacího procesoru, jehož úkolem je odhadnout počet řádků vrácených relačními operacemi v dotazu. Tyto informace spolu s některými dalšími daty používá optimalizátor dotazů k výběru efektivního plánu provádění. Odhad mohutnosti je ze své podstaty nepřesný, protože se jedná o matematický model, který se opírá o statistické informace. Je také založena na několika předpokladech, které, i když nebyly zdokumentovány, byly v průběhu let známy – některé z nich zahrnují předpoklady jednotnosti, nezávislosti, omezení a inkluze. Následuje stručný popis těchto předpokladů.
- Uniformita . Používá se, když je distribuce pro atribut neznámá, například uvnitř řádků rozsahu v kroku histogramu nebo když histogram není k dispozici.
- Nezávislost . Používá se, když jsou atributy ve vztahu nezávislé, pokud mezi nimi není známa korelace.
- Udržování . Používá se, když mohou být dva atributy stejné, předpokládá se, že jsou stejné.
- Začlenění . Používá se při porovnávání atributu s konstantou, předpokládá se, že vždy existuje shoda.
Je zajímavé, že jsem právě nedávno hovořil o některých omezeních těchto předpokladů na svém posledním vystoupení na PASS Summit, nazvaném Defeating the Limitations of the Query Optimizer. Přesto mě překvapilo, když jsem si v článku přečetl, že autoři připouštějí, že podle jejich zkušeností z praxe jsou tyto předpoklady „často nesprávné“.
Aktuální odhad mohutnosti byl napsán spolu s celým dotazovacím procesorem pro SQL Server 7.0, který byl vydán v prosinci 1998. Je zřejmé, že tato komponenta během několika let a několika vydáních SQL Serveru čelila mnoha změnám, včetně oprav, úprav a rozšíření přizpůsobit odhad mohutnosti pro nové funkce T-SQL. Možná si říkáte, proč nahrazovat součástku, která se úspěšně používá už asi 15 let?
Proč nový odhad mohutnosti
Článek vysvětluje některé důvody redesignu, včetně:
- Přizpůsobení odhadu mohutnosti novým vzorcům pracovní zátěže.
- Změny provedené v odhadu mohutnosti v průběhu let znesnadnily komponentu „ladit, předvídat a pochopit.“
- Pokoušet se vylepšit současný model bylo při použití současné architektury obtížné, proto byl vytvořen nový návrh zaměřený na oddělení úkolů (a) rozhodování o tom, jak vypočítat konkrétní odhad, a (b) skutečného provádění výpočtu .
Nejsem si jistý, zda Microsoft zveřejní další podrobnosti o novém odhadu mohutnosti. Ostatně za 15 let nebylo nikdy zveřejněno tolik podrobností o starém odhadu mohutnosti; například jak se vypočítá nějaký specifický odhad mohutnosti. Na druhou stranu existují nové rozšířené události, které můžeme použít k řešení problémů s odhadem mohutnosti nebo jen k prozkoumání toho, jak to funguje. Tyto události zahrnují query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors a query_rpc_set_cardinality .
Plánovat regrese
Hlavním problémem, který přichází na mysl s tak obrovskou změnou uvnitř optimalizátoru dotazů, jsou regrese plánu. Strach z regresí plánu byl považován za největší překážku vylepšení optimalizátoru dotazů. Regrese jsou problémy vzniklé po použití opravy na optimalizátor dotazů a někdy se jim říká klasické „dvě chyby dělají dobro“. To se může stát, když se dva špatné odhady, například jeden nadhodnocující hodnotu a druhý podhodnocující, vzájemně vyruší, což naštěstí dává dobrý odhad. Oprava pouze jedné z těchto hodnot může nyní vést ke špatnému odhadu, který může negativně ovlivnit výběr plánu a způsobit regresi.
Aby se zabránilo regresím souvisejícím s novým estimátorem mohutnosti, SQL Server poskytuje způsob, jak jej povolit nebo zakázat, protože závisí na úrovni kompatibility databáze. Toto lze změnit pomocí ALTER DATABASE prohlášení, jak bylo uvedeno výše. Nastavení databáze na úroveň kompatibility 120 použije nový estimátor mohutnosti, zatímco úroveň kompatibility menší než 120 použije starý odhad mohutnosti. Kromě toho, jakmile použijete konkrétní estimátor mohutnosti, existují dva příznaky trasování, které můžete použít ke změně na druhý. Ačkoli v tuto chvíli nevidím nikde zdokumentované příznaky trasování, jsou zmíněny jako součást popisu query_optimizer_force_both_cardinality_estimation_behaviors prodloužená akce. Příznak trasování 2312 lze použít k aktivaci nového estimátoru mohutnosti, zatímco příznak trasování 9481 lze použít k jeho zakázání. Můžete dokonce použít příznaky trasování pro konkrétní dotaz pomocí QUERYTRACEON hint (ačkoli ještě není zdokumentováno, zda bude podporováno i toto).
Příklady
Nakonec se v článku také zmiňují některé testované scénáře, jako je přeplněný primární klíč, jednoduché spojení nebo problém vzestupného klíče. Ukazuje také, jak autoři experimentovali s více scénáři (nebo modelovými variacemi) a v některých případech „uvolnili“ některé předpoklady vytvořené estimátorem mohutnosti, například v případě předpokladu nezávislosti, od úplné nezávislosti k úplné korelaci. a něco mezi tím, dokud nebyly nalezeny dobré výsledky.
Přestože papír neobsahuje žádné podrobnosti, rozhodl jsem se začít testovat některé z těchto scénářů, abych se pokusil porozumět tomu, jak nový odhad mohutnosti funguje. Prozatím vám ukážu příklad s použitím předpokladu nezávislosti a vzestupných klíčů. Také jsem testoval předpoklad uniformity, ale zatím jsem nebyl schopen najít žádný rozdíl v odhadu.
Začněme příkladem předpokladu nezávislosti. Nejprve se podívejme na aktuální chování. Za tímto účelem se ujistěte, že používáte starý estimátor mohutnosti spuštěním následujícího příkazu v databázi AdventureWorks2012:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Poté spusťte:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Získáme odhadem 196 záznamů, jak je uvedeno dále:

Podobným způsobem získá následující výrok odhadem 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Pokud použijeme oba predikáty, máme následující dotaz, který bude mít odhadovaný počet řádků 1,93862 (zaokrouhleno na 2 řádky, pokud používáte SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Tato hodnota je vypočtena za předpokladu úplné nezávislosti obou predikátů, což používá vzorec (196 * 194) / 19614,0 (kde 19614 je celkový počet řádků v tabulce). Použití celkové korelace by nám mělo dát odhad 194, protože všechny záznamy s PSČ 91502 patří Burbanku. Nový estimátor mohutnosti odhaduje hodnotu, která nepředpokládá úplnou nezávislost nebo úplnou korelaci. Změňte na nový odhad mohutnosti pomocí následujícího příkazu:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Opětovné spuštění stejného příkazu poskytne odhad 19,3931 řádků, což je hodnota mezi předpokladem úplné nezávislosti a celkovou korelací (zaokrouhleno na 19 řádků v Průzkumníku plánu). Použitý vzorec je selektivita nejselektivnějšího filtru * SQRT (selektivita dalšího nejselektivnějšího filtru) nebo (194/19614,0) * SQRT (196/19614,0) * 19614, což dává 19,393:

Pokud jste povolili nový estimátor mohutnosti na úrovni databáze, kupte jej a chcete jej deaktivovat pro konkrétní dotaz, abyste se vyhnuli regresi plánu, můžete použít příznak trasování 9481, jak bylo vysvětleno dříve:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Poznámka:Nápověda k dotazu QUERYTRACEON se používá k použití příznaku trasování na úrovni dotazu a v současnosti je podporována pouze v omezeném počtu scénářů. Další informace o nápovědě k dotazu QUERYTRACEON naleznete na adrese https://support.microsoft.com/kb/2801413.
Nyní se podívejme na vzestupný klíčový problém, téma, které jsem podrobněji vysvětlil v tomto příspěvku. Tradičním doporučením společnosti Microsoft k vyřešení tohoto problému je ruční aktualizace statistik po načtení dat, jak je vysvětleno zde – což popisuje problém následujícím způsobem:
Statistiky ve vzestupných nebo sestupných klíčových sloupcích, jako jsou IDENTITY nebo sloupce časového razítka v reálném čase, mohou vyžadovat častější aktualizace statistik, než provádí optimalizátor dotazů. Operace vložení připojí nové hodnoty k vzestupným nebo sestupným sloupcům. Počet přidaných řádků může být příliš malý na to, aby spustil aktualizaci statistik. Pokud statistiky nejsou aktuální a dotazy se vybírají z naposledy přidaných řádků, aktuální statistika nebude mít odhady mohutnosti pro tyto nové hodnoty. To může mít za následek nepřesné odhady mohutnosti a pomalý výkon dotazů. Například dotaz, který vybírá z nejnovějších dat prodejní objednávky, bude mít nepřesné odhady mohutnosti, pokud statistiky nebudou aktualizovány tak, aby zahrnovaly odhady mohutnosti pro nejnovější data prodejní objednávky.
Doporučení v mém článku bylo použít příznaky trasování 2389 a 2390, které poprvé publikoval Ian Jose ve svém článku Ascending Keys and Auto Quick Corrected Statistics. Můžete si přečíst můj článek pro vysvětlení a příklad, jak používat tyto příznaky trasování, abyste se tomuto problému vyhnuli. Tyto příznaky trasování stále fungují na SQL Server 2014 CTP2. Ale ještě lepší je, že již nejsou potřeba, pokud používáte nový odhad mohutnosti.
Použití stejného příkladu v mém příspěvku:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Vložte nějaká data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Od té doby, co jsme vytvořili index, máme jen nové statistiky. Spuštěním následujícího dotazu vytvoříte dobrý odhad 35 řádků:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Pokud vložíme nová data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Odhad můžete vidět pomocí starého odhadu mohutnosti, jak je uvedeno dále:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Protože malý počet vložených záznamů nestačil ke spuštění automatické aktualizace objektu statistiky, aktuální histogram si není vědom nových přidaných záznamů a optimalizátor dotazů používá odhadem 1 řádek. Volitelně můžete použít příznaky trasování 2389 a 2390, které vám pomohou získat lepší odhad. Ale pokud zkusíte stejný dotaz s novým odhadem mohutnosti, získáte následující odhad:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
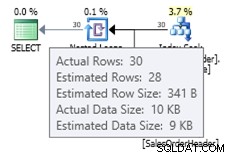
V tomto případě získáme lepší odhad než starý odhad mohutnosti (nebo získáme stejný odhad jako při použití příznaků trasování 2389 nebo 2390). Odhadovaná hodnota 27,9631 (opět zaokrouhlená na 28 pomocí Plan Explorer) se vypočítá pomocí informací o hustotě statistického objektu vynásobených počtem řádků tabulky; tj. 0,0008992806 * 31095. Hodnotu hustoty lze získat pomocí:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); A konečně, mějte na paměti, že nic zmíněného v tomto článku není zdokumentováno, a toto je chování, které jsem dosud pozoroval v SQL Server 2014 CTP2. Cokoli z toho se může změnit v pozdější verzi CTP nebo RTM produktu.