Ohledně databáze tempdb dávám stejná doporučení od té doby, co jsem před více než 15 lety začal pracovat se serverem SQL, kdy jsem pracoval se zákazníky používajícími verzi 2000. Podstata toho:vytvořte více datových souborů, které mají stejnou velikost, se stejným automatickým nastavením -growth settings, povolte příznak trasování 1118 (a možná 1117) a omezte používání databáze tempdb. Ze strany zákazníka to byl limit toho, co lze udělat*, až do SQL Server 2019.
*Existuje několik dalších doporučení pro kódování, o kterých Pam Lahoud diskutuje ve svém velmi informativním příspěvku TEMPDB – Soubory a trasovací příznaky a aktualizace, ach můj!
Zajímavé je, že po tak dlouhé době je tempdb stále problémem. Tým SQL Server provedl v průběhu let mnoho změn, aby se pokusil problémy zmírnit, ale zneužívání pokračuje. Nejnovější adaptací týmu SQL Server je přesun systémových tabulek (metadata) pro tempdb do In-Memory OLTP (neboli optimalizováno pro paměť). Některé informace jsou k dispozici v poznámkách k vydání SQL Server 2019 a během prvního dne keynote PASS Summit byla k dispozici ukázka od Boba Warda a Conora Cunninghama. Pam Lahoud také udělala rychlé demo na svém generálním zasedání PASS Summit. Nyní, když je venku 2019 CTP 3.2, myslel jsem si, že by mohl být čas trochu otestovat sám sebe.
Nastavení
Na svém virtuálním počítači mám nainstalovaný SQL Server 2019 CTP 3.2, který má 8 GB paměti (max. paměť serveru nastavena na 6 GB) a 4 vCPU. Vytvořil jsem čtyři (4) datové soubory tempdb, každý o velikosti 1 GB.
Obnovil jsem kopii WideWorldImporters a poté vytvořil tři uložené procedury (definice níže). Každá uložená procedura přijímá vstup data a vloží všechny řádky z Sales.Order a Sales.OrderLines pro dané datum do dočasného objektu. V Sales.usp_OrderInfoTV je objektem proměnná tabulky, v Sales.usp_OrderInfoTT je objektem dočasná tabulka definovaná pomocí SELECT … INTO s neshlukovaným přidáním později a v Sales.usp_OrderInfoTTALT je objektem předdefinovaná dočasná tabulka, která je následně změněna. mít další sloupec. Po přidání dat do dočasného objektu existuje u objektu příkaz SELECT, který se připojí k tabulce Sales.Customers.
/*
Create the stored procedures
*/
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTV
GO
CREATE PROCEDURE Sales.usp_OrderInfoTV @OrderDate DATE
AS
BEGIN
DECLARE @OrdersInfo TABLE (
OrderID INT,
OrderLineID INT,
CustomerID INT,
StockItemID INT,
Quantity INT,
UnitPrice DECIMAL(18,2),
OrderDate DATE);
INSERT INTO @OrdersInfo (
OrderID,
OrderLineID,
CustomerID,
StockItemID,
Quantity,
UnitPrice,
OrderDate)
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice,
OrderDate
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM @OrdersInfo o
JOIN Sales.Customers c
ON o.CustomerID = c.CustomerID
GROUP BY o.OrderID, c.CustomerName;
END
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTT
GO
CREATE PROCEDURE Sales.usp_OrderInfoTT @OrderDate DATE
AS
BEGIN
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice,
OrderDate
INTO #temporderinfo
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM #temporderinfo o
JOIN Sales.Customers c
ON o.CustomerID = c.CustomerID
GROUP BY o.OrderID, c.CustomerName
END
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTTALT
GO
CREATE PROCEDURE Sales.usp_OrderInfoTTALT @OrderDate DATE
AS
BEGIN
CREATE TABLE #temporderinfo (
OrderID INT,
OrderLineID INT,
CustomerID INT,
StockItemID INT,
Quantity INT,
UnitPrice DECIMAL(18,2));
INSERT INTO #temporderinfo (
OrderID,
OrderLineID,
CustomerID,
StockItemID,
Quantity,
UnitPrice)
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM #temporderinfo o
JOIN Sales.Customers c
ON o.CustomerID c.CustomerID
GROUP BY o.OrderID, c.CustomerName
END
GO
/*
Create tables to hold testing data
*/
USE [WideWorldImporters];
GO
CREATE TABLE [dbo].[PerfTesting_Tests] (
[TestID] INT IDENTITY(1,1),
[TestName] VARCHAR (200),
[TestStartTime] DATETIME2,
[TestEndTime] DATETIME2
) ON [PRIMARY];
GO
CREATE TABLE [dbo].[PerfTesting_WaitStats] (
[TestID] [int] NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
GO
/*
Enable Query Store
(testing settings, not exactly what
I would recommend for production)
*/
USE [master];
GO
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON;
GO
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30),
DATA_FLUSH_INTERVAL_SECONDS = 600,
INTERVAL_LENGTH_MINUTES = 10,
MAX_STORAGE_SIZE_MB = 1024,
QUERY_CAPTURE_MODE = AUTO,
SIZE_BASED_CLEANUP_MODE = AUTO);
GO Testování
Výchozí chování pro SQL Server 2019 je, že metadata databáze tempdb nejsou optimalizována pro paměť, a to můžeme potvrdit kontrolou sys.configurations:
SELECT * FROM sys.configurations WHERE configuration_id = 1589;

Pro všechny tři uložené procedury použijeme sqlcmd ke generování 20 souběžných vláken s jedním ze dvou různých souborů .sql. První soubor .sql, který bude používat 19 vláken, provede proceduru ve smyčce 1000krát. Druhý soubor .sql, který bude mít pouze jedno (1) vlákno, provede proceduru ve smyčce 3000krát. Soubor také obsahuje TSQL pro zachycení dvou zajímavých metrik:celkové trvání a statistiky čekání. K zachycení průměrné doby trvání procedury použijeme Query Store.
/*
Example of first .sql file
which calls the SP 1000 times
*/
SET NOCOUNT ON;
GO
USE [WideWorldImporters];
GO
DECLARE @StartDate DATE;
DECLARE @MaxDate DATE;
DECLARE @Date DATE;
DECLARE @Counter INT = 1;
SELECT @StartDATE = MIN(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SELECT @MaxDATE = MAX(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SET @Date = @StartDate;
WHILE @Counter <= 1000
BEGIN
EXEC [Sales].[usp_OrderInfoTT] @Date;
IF @Date <= @MaxDate
BEGIN
SET @Date = DATEADD(DAY, 1, @Date);
END
ELSE
BEGIN
SET @Date = @StartDate;
END
SET @Counter = @Counter + 1;
END
GO
/*
Example of second .sql file
which calls the SP 3000 times
and captures total duration and
wait statisics
*/
SET NOCOUNT ON;
GO
USE [WideWorldImporters];
GO
DECLARE @StartDate DATE;
DECLARE @MaxDate DATE;
DECLARE @DATE DATE;
DECLARE @Counter INT = 1;
DECLARE @TestID INT;
DECLARE @TestName VARCHAR(200) = 'Execution of usp_OrderInfoTT - Disk Based System Tables';
INSERT INTO [WideWorldImporters].[dbo].[PerfTesting_Tests] ([TestName]) VALUES (@TestName);
SELECT @TestID = MAX(TestID) FROM [WideWorldImporters].[dbo].[PerfTesting_Tests];
SELECT @StartDATE = MIN(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SELECT @MaxDATE = MAX(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SET @Date = @StartDate;
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
/*
set start time
*/
UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests]
SET [TestStartTime] = SYSDATETIME()
WHERE [TestID] = @TestID;
WHILE @Counter <= 3000
BEGIN
EXEC [Sales].[usp_OrderInfoTT] @Date;
IF @Date <= @MaxDate
BEGIN
SET @Date = DATEADD(DAY, 1, @Date);
END
ELSE
BEGIN
SET @Date = @StartDate;
END
SET @Counter = @Counter + 1
END
/*
set end time
*/
UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests]
SET [TestEndTime] = SYSDATETIME()
WHERE [TestID] = @TestID;
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
WITH [DiffWaits] AS
(SELECT
-- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT
-- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0),
[Waits] AS
(SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (
-- These wait types are almost 100% never a problem and so they are
-- filtered out to avoid them skewing the results.
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR', N'BROKER_TASK_STOP',
N'BROKER_TO_FLUSH', N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT', N'CLR_MANUAL_EVENT',
N'CLR_SEMAPHORE', N'CXCONSUMER', N'DBMIRROR_DBM_EVENT',
N'DBMIRROR_EVENTS_QUEUE', N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE', N'EXECSYNC',
N'FSAGENT', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', N'HADR_LOGCAPTURE_WAIT',
N'HADR_NOTIFICATION_DEQUEUE', N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP', N'LOGMGR_QUEUE',
N'MEMORY_ALLOCATION_EXT', N'ONDEMAND_TASK_QUEUE', N'PARALLEL_REDO_DRAIN_WORKER',
N'PARALLEL_REDO_LOG_CACHE', N'PARALLEL_REDO_TRAN_LIST', N'PARALLEL_REDO_WORKER_SYNC',
N'PARALLEL_REDO_WORKER_WAIT_WORK', N'PREEMPTIVE_XE_GETTARGETSTATE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED', N'PWAIT_DIRECTLOGCONSUMER_GETNEXT',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', N'QDS_ASYNC_QUEUE',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'QDS_SHUTDOWN_QUEUE', N'REDO_THREAD_PENDING_WORK', N'REQUEST_FOR_DEADLOCK_SEARCH',
N'RESOURCE_QUEUE', N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP', N'SLEEP_MASTERDBREADY',
N'SLEEP_MASTERMDREADY', N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK', N'SLEEP_TEMPDBSTARTUP',
N'SNI_HTTP_ACCEPT', N'SOS_WORK_DISPATCHER', N'SP_SERVER_DIAGNOSTICS_SLEEP',
N'SQLTRACE_BUFFER_FLUSH', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS', N'WAITFOR',
N'WAITFOR_TASKSHUTDOWN', N'WAIT_XTP_RECOVERY', N'WAIT_XTP_HOST_WAIT',
N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', N'WAIT_XTP_CKPT_CLOSE',
N'XE_DISPATCHER_JOIN', N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT'
)
)
INSERT INTO [WideWorldImporters].[dbo].[PerfTesting_WaitStats] (
[TestID],
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
@TestID,
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO Příklad souboru příkazového řádku:
Výsledky
Po spuštění souborů příkazového řádku, které generují 20 vláken pro každou uloženou proceduru, kontrola celkové doby trvání 12 000 spuštění každé procedury ukazuje následující:
SELECT *, DATEDIFF(SECOND, TestStartTime, TestEndTime) AS [TotalDuration] FROM [dbo].[PerfTesting_Tests] ORDER BY [TestID];

Dokončení uložených procedur s dočasnými tabulkami (usp_OrderInfoTT a usp_OrderInfoTTC) trvalo déle. Pokud se podíváme na výkon jednotlivých dotazů:
SELECT
[qsq].[query_id],
[qsp].[plan_id],
OBJECT_NAME([qsq].[object_id]) AS [ObjectName],
[rs].[count_executions],
[rs].[last_execution_time],
[rs].[avg_duration],
[rs].[avg_logical_io_reads],
[qst].[query_sql_text]
FROM [sys].[query_store_query] [qsq]
JOIN [sys].[query_store_query_text] [qst]
ON [qsq].[query_text_id] = [qst].[query_text_id]
JOIN [sys].[query_store_plan] [qsp]
ON [qsq].[query_id] = [qsp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qsp].[plan_id] = [rs].[plan_id]
WHERE ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTT'))
OR ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTV'))
OR ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTTALT'))
ORDER BY [qsq].[query_id], [rs].[last_execution_time];

Vidíme, že SELECT … INTO pro usp_OrderInfoTT trvalo v průměru asi 28 ms (trvání v Query Store je uloženo v mikrosekundách) a trvalo pouze 9 ms, když byla dočasná tabulka předem vytvořena. U proměnné tabulky trvalo INSERT v průměru něco málo přes 22 ms. Zajímavé je, že dotaz SELECT trval jen něco málo přes 1 ms pro dočasné tabulky a přibližně 2,7 ms pro proměnnou tabulky.
Kontrola dat statistiky čekání najde známý wait_type, PAGELATCH*:
SELECT * FROM [dbo].[PerfTesting_WaitStats] ORDER BY [TestID], [Percentage] DESC;

Všimněte si, že vidíme pouze PAGELATCH* čeká na testy 1 a 2, což byly procedury s dočasnými tabulkami. Pro usp_OrderInfoTV, který používal proměnnou tabulky, vidíme pouze čekání SOS_SCHEDULER_YIELD. Poznámka: To v žádném případě neznamená, že byste měli místo dočasných tabulek používat proměnné tabulky , ani to neznamená, že nebudete mít PAGELATCH čeká s proměnnými tabulky. Toto je vykonstruovaný scénář; velmi doporučujeme otestovat pomocí VAŠEHO kódu, abyste viděli, jaké wait_types se objeví.
Nyní změníme instanci tak, aby používala pro metadata tempdb tabulky optimalizované pro paměť. To lze provést dvěma způsoby, pomocí příkazu ALTER SERVER CONFIGURATION nebo pomocí sp_configure. Protože toto nastavení je pokročilá možnost, pokud používáte sp_configure, musíte nejprve povolit pokročilé možnosti.
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED TEMPDB_METADATA = ON; GO
Po této změně je nutné restartovat do instance. (POZNÁMKA:toto můžete změnit zpět na NEPOUŽÍVAT tabulky optimalizované pro paměť, stačí restartovat instanci znovu.) Pokud po restartu znovu zkontrolujeme sys.configurations, můžeme vidět, že tabulky metadat jsou optimalizované pro paměť:

Po opětovném spuštění souborů příkazového řádku celková doba trvání 21 000 spuštění každé procedury ukazuje následující (všimněte si, že výsledky jsou seřazeny podle uložené procedury pro snazší porovnání):

Rozhodně došlo ke zlepšení výkonu pro usp_OrderInfoTT i usp_OrderInfoTTC a k mírnému zvýšení výkonu pro usp_OrderInfoTV. Pojďme zkontrolovat trvání dotazů:
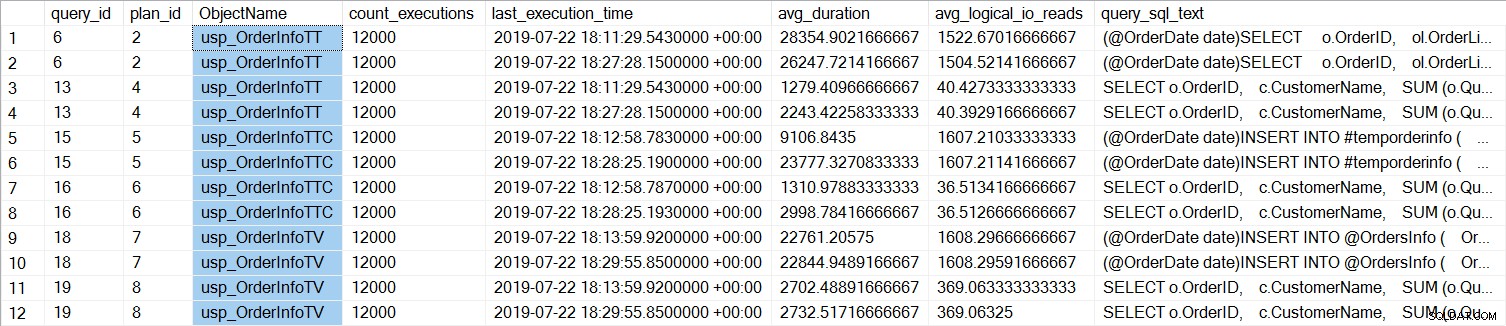
U všech dotazů je trvání dotazu téměř stejné, s výjimkou prodloužení doby trvání INSERT, když je tabulka předem vytvořena, což je zcela neočekávané. Vidíme zajímavou změnu ve statistikách čekání:
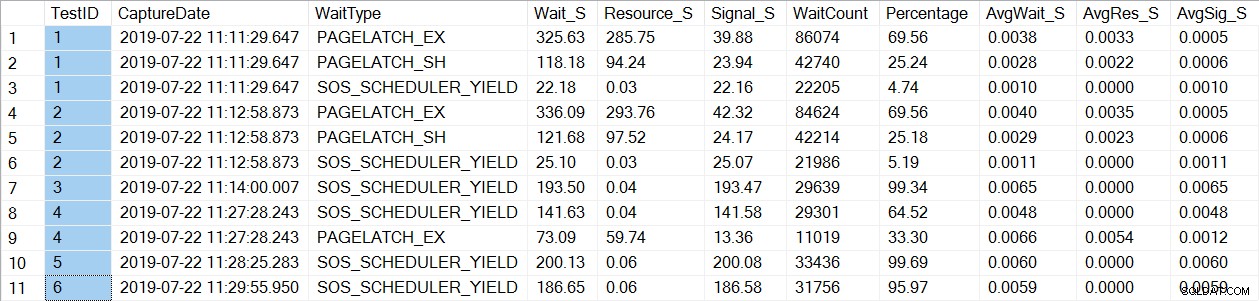
Pro usp_OrderInfoTT se provede SELECT … INTO k vytvoření dočasné tabulky. Čekání se změní z PAGELATCH_EX a PAGELATCH_SH na pouze PAGELATCH_EX a SOS_SCHEDULER_YIELD. Již nevidíme čekání PAGELATCH_SH.
Pro usp_OrderInfoTTC, který vytvoří dočasnou tabulku a poté ji vloží, se již nezobrazují čekání PAGELATCH_EX a PAGELATCH_SH a vidíme pouze čekání SOS_SCHEDULER_YIELD.
A konečně, pro OrderInfoTV jsou čekání konzistentní – pouze SOS_SCHEDULER_YIELD, s téměř stejnou celkovou dobou čekání.
Shrnutí
Na základě tohoto testování vidíme zlepšení ve všech případech, výrazně u uložených procedur s dočasnými tabulkami. Pro postup proměnné tabulky došlo k mírné změně. Je nesmírně důležité si uvědomit, že se jedná o jeden scénář s malým zátěžovým testem. Velmi mě zajímalo vyzkoušet tyto tři velmi jednoduché scénáře, abych se pokusil pochopit, co by mohlo nejvíce těžit z optimalizace paměti metadat tempdb. Toto pracovní zatížení bylo malé a běželo po velmi omezenou dobu – ve skutečnosti jsem měl rozmanitější výsledky s více vlákny, což stojí za to prozkoumat v jiném příspěvku. Největší výhodou je, že stejně jako u všech nových funkcí a funkcí je důležité testování. Pro tuto funkci chcete mít základní linii aktuálního výkonu, se kterou budete moci porovnávat metriky, jako jsou dávkové požadavky/s a statistiky čekání po provedení optimalizace paměti metadat.
Další úvahy
Použití In-Memory OLTP vyžaduje skupinu souborů typu MEMORY OPTIMIZED DATA. Po povolení MEMORY_OPTIMIZED TEMPDB_METADATA se však pro tempdb nevytvoří žádná další skupina souborů. Navíc není známo, zda jsou tabulky optimalizované pro paměť odolné (SCHEMA_AND_DATA) nebo ne (SCHEMA_ONLY). Obvykle to lze určit pomocí sys.tables (durability_desc), ale při dotazování v databázi tempdb se nic nevrací pro příslušné systémové tabulky, a to ani při použití připojení vyhrazeného správce. Máte možnost prohlížet neklastrované indexy pro tabulky optimalizované pro paměť. Chcete-li zjistit, které tabulky jsou v databázi tempdb optimalizovány pro paměť, můžete použít následující dotaz:
SELECT * FROM tempdb.sys.dm_db_xtp_object_stats x JOIN tempdb.sys.objects o ON x.object_id = o.object_id JOIN tempdb.sys.schemas s ON o.schema_id = s.schema_id;
Potom pro kteroukoli z tabulek spusťte sp_helpindex, například:
EXEC sys.sp_helpindex N'sys.sysobjvalues';

Všimněte si, že pokud se jedná o hash index (který vyžaduje odhad BUCKET_COUNT jako součást vytváření), popis bude obsahovat „neshlukovaný hash“.