
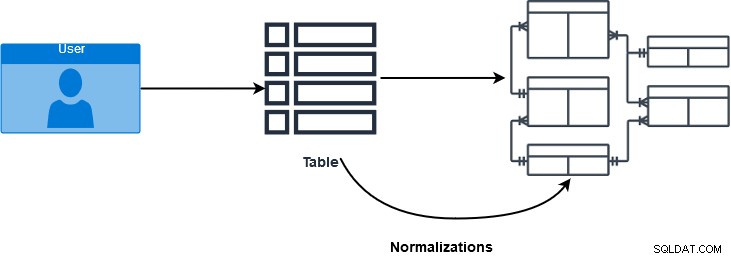
SQL JOIN je klauzule, která se používá ke kombinaci více tabulek a načítání dat na základě společného pole v relačních databázích. Databázoví odborníci používají normalizace k zajištění a zlepšení integrity dat. V různých formách normalizace jsou data distribuována do více logických tabulek. Tyto tabulky používají referenční omezení – primární klíč a cizí klíče – k vynucení integrity dat v tabulkách SQL Server. Na obrázku níže vidíme proces normalizace databáze.
Porozumění různým typům SQL JOIN
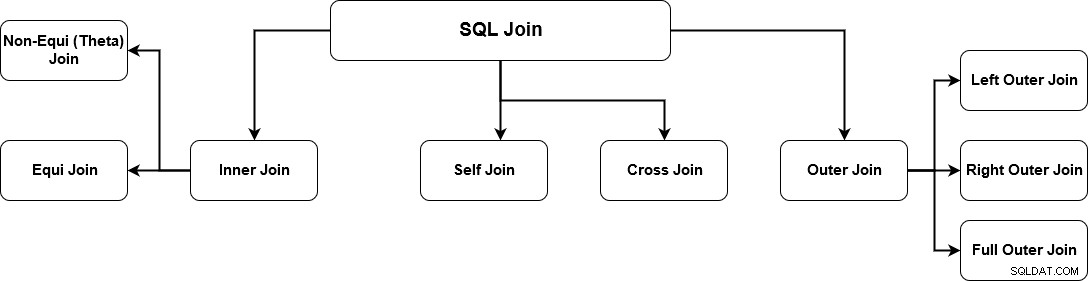
SQL JOIN generuje smysluplná data kombinací více relačních tabulek. Tyto tabulky spolu souvisí pomocí klíče a mají vztahy jedna k jedné nebo jedna k mnoha. Chcete-li získat správná data, musíte znát požadavky na data a správné mechanismy spojení. SQL Server podporuje více spojení a každá metoda má specifický způsob načítání dat z více tabulek. Níže uvedený obrázek uvádí podporovaná připojení k serveru SQL.
Vnitřní spojení SQL
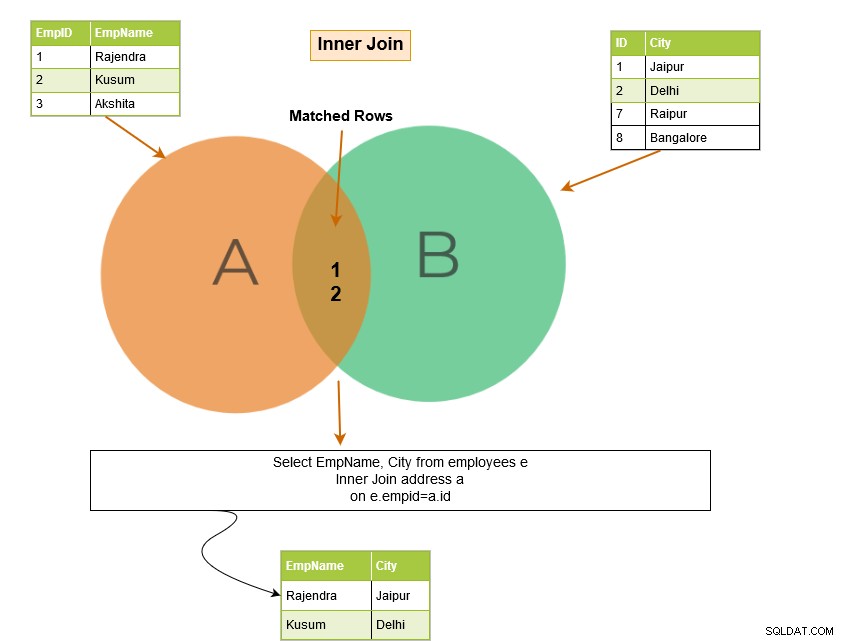
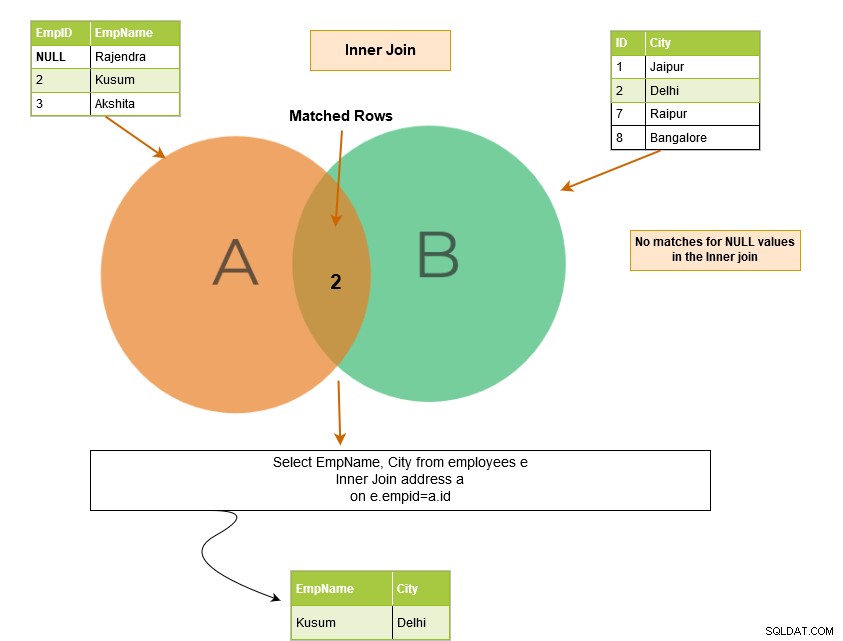
Vnitřní spojení SQL zahrnuje řádky z tabulek, kde jsou splněny podmínky spojení. Například v níže uvedeném Vennově diagramu vnitřní spojení vrací odpovídající řádky z tabulky A a tabulky B.
V níže uvedeném příkladu si všimněte následujících věcí:
- Máme dvě tabulky – [Zaměstnanci] a [Adresa].
- Dotaz SQL je připojen ke sloupci [Zaměstnanci].[ID_zaměstnavatele] a [Adresa].[ID].
Výstup dotazu vrátí záznamy zaměstnanců pro EmpID, které existuje v obou tabulkách.
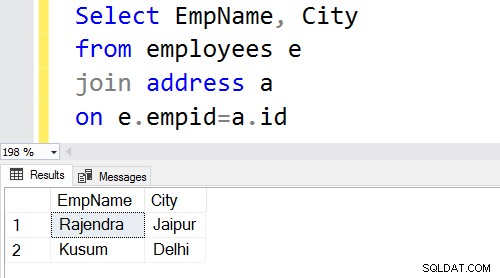
Vnitřní spojení vrátí odpovídající řádky z obou tabulek; proto je také známý jako Equi join. Pokud klíčové slovo inner nespecifikujeme, SQL Server provede operaci vnitřního spojení.
V jiném typu vnitřního spojení, theta spojení, nepoužíváme operátor rovnosti (=) v klauzuli ON. Místo toho používáme operátory nerovnosti, jako jsou .
SELECT * FROM Table1 T1, Table2 T2 WHERE T1.Price
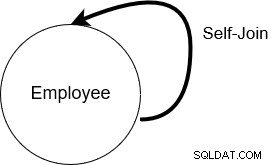
Při samopřipojení se SQL Server připojí k tabulce sám se sebou. To znamená, že název tabulky se v klauzuli from objeví dvakrát.
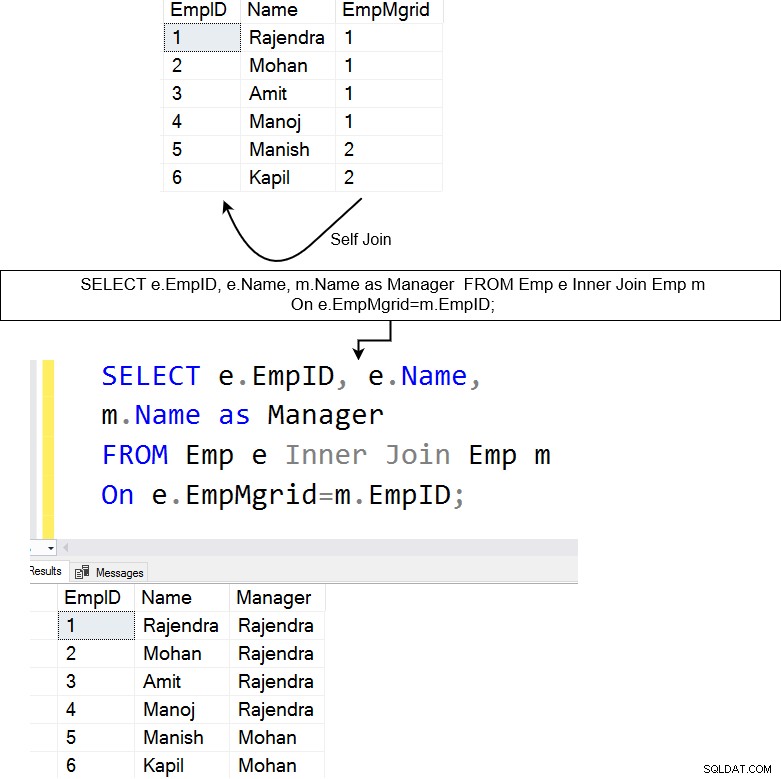
Níže máme tabulku [Emp], která obsahuje údaje o zaměstnancích a jejich manažerech. Vlastní spojení je užitečné pro dotazování na hierarchická data. Například v tabulce zaměstnanců můžeme pomocí vlastního připojení zjistit jméno každého zaměstnance a jeho manažera sestav.
Výše uvedený dotaz vloží vlastní spojení do tabulky [Emp]. Spojí sloupec EmpMgrID se sloupcem EmpID a vrátí odpovídající řádky.
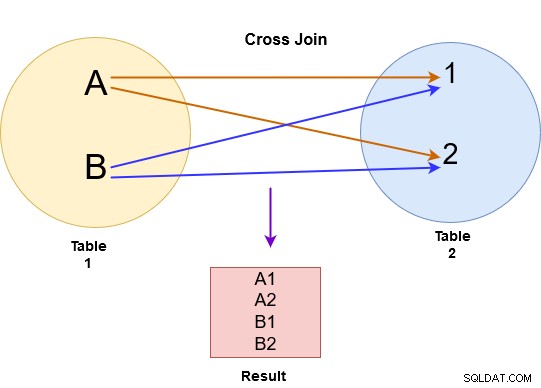
V křížovém spojení vrátí SQL Server kartézský produkt z obou tabulek. Například na obrázku níže jsme provedli křížové spojení pro tabulku A a B.
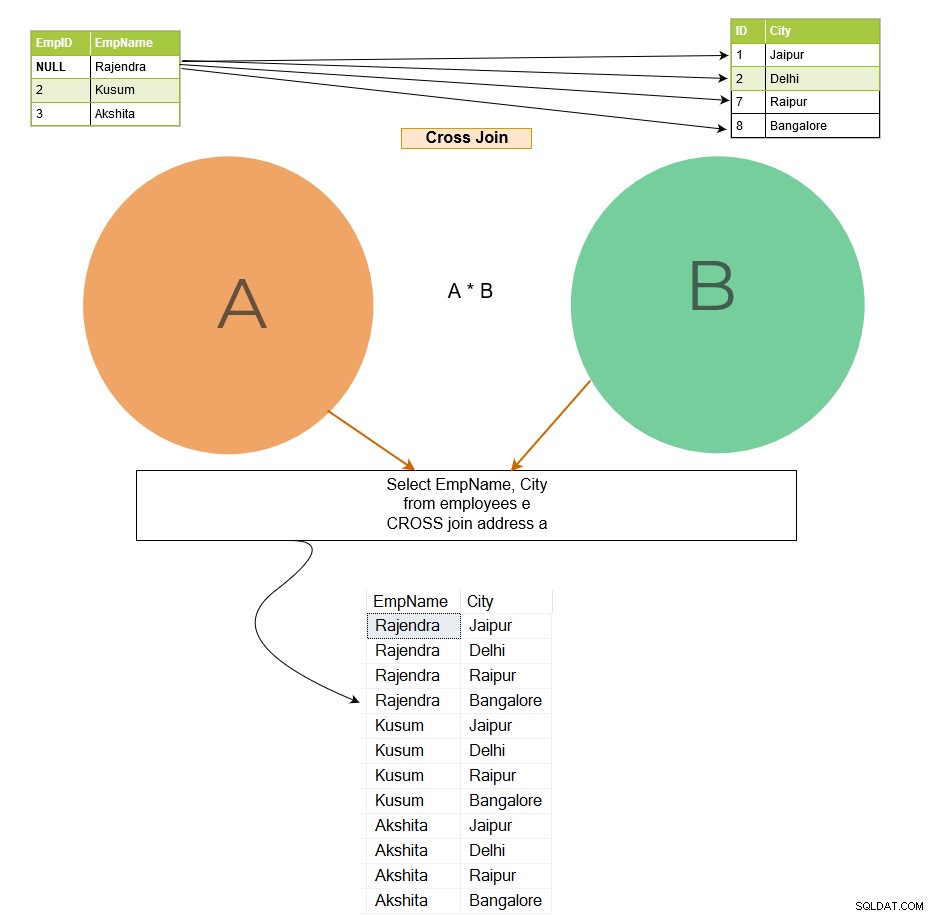
Křížové spojení spojuje každý řádek z tabulky A s každým řádkem dostupným v tabulce B. Proto je výstup také známý jako kartézský součin obou tabulek. Na obrázku níže si všimněte následujícího:
Ve výstupu křížového spojení se řádek 1 tabulky [Zaměstnanec] spojí se všemi řádky tabulky [Adresa] a pro zbývající řádky se řídí stejným vzorem.
Pokud má první tabulka x počet řádků a druhá tabulka má n počet řádků, křížové spojení dá x*n počet řádků na výstupu. U větších tabulek byste se měli vyhnout křížovému spojení, protože může vrátit velké množství záznamů a SQL Server vyžaduje hodně výpočetního výkonu (CPU, paměť a IO) pro zpracování tak rozsáhlých dat.
Jak jsme vysvětlili dříve, vnitřní spojení vrací odpovídající řádky z obou tabulek. Při použití vnějšího spojení SQL nejen vypíše odpovídající řádky, ale také vrátí neshodné řádky z ostatních tabulek. Neshodný řádek závisí na levém, pravém nebo úplném klíčovém slovu.
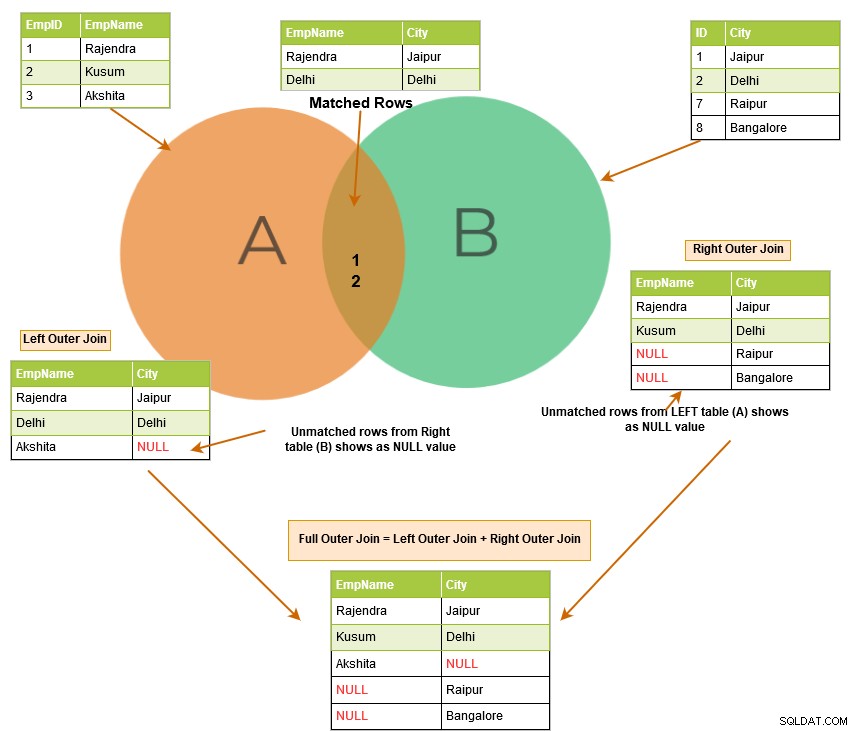
Obrázek níže popisuje na vysoké úrovni levé, pravé a úplné vnější spojení.
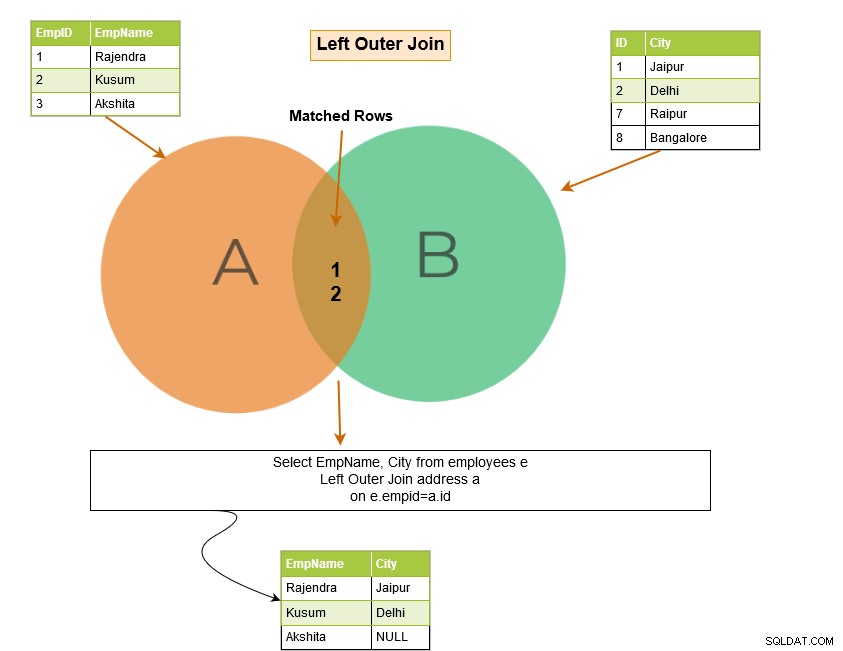
Levé vnější spojení SQL vrátí odpovídající řádky obou tabulek spolu s neodpovídajícími řádky z levé tabulky. Pokud záznam z levé tabulky nemá žádné odpovídající řádky v pravé tabulce, zobrazí záznam s hodnotami NULL.
V níže uvedeném příkladu vrací levé vnější spojení následující řádky:
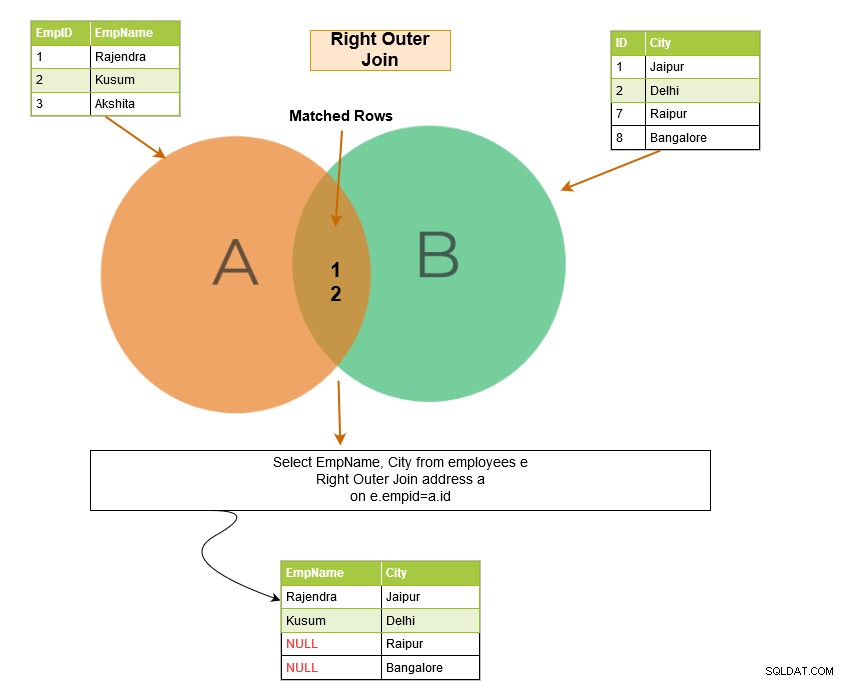
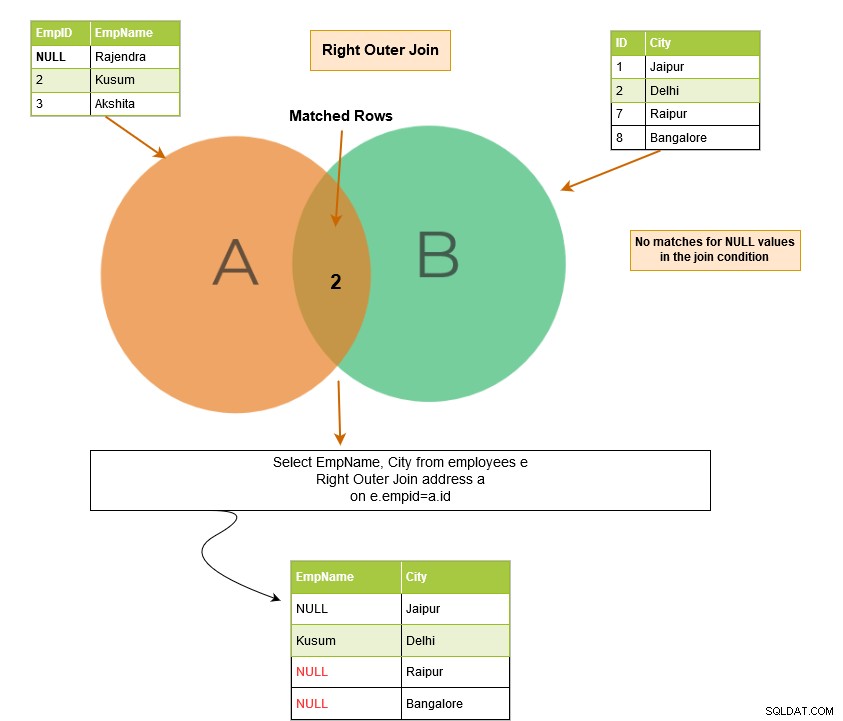
Pravé vnější spojení SQL vrátí odpovídající řádky obou tabulek spolu s neodpovídajícími řádky z pravé tabulky. Pokud záznam z pravé tabulky nemá žádné odpovídající řádky v levé tabulce, zobrazí záznam s hodnotami NULL.
V níže uvedeném příkladu máme následující výstupní řádky:
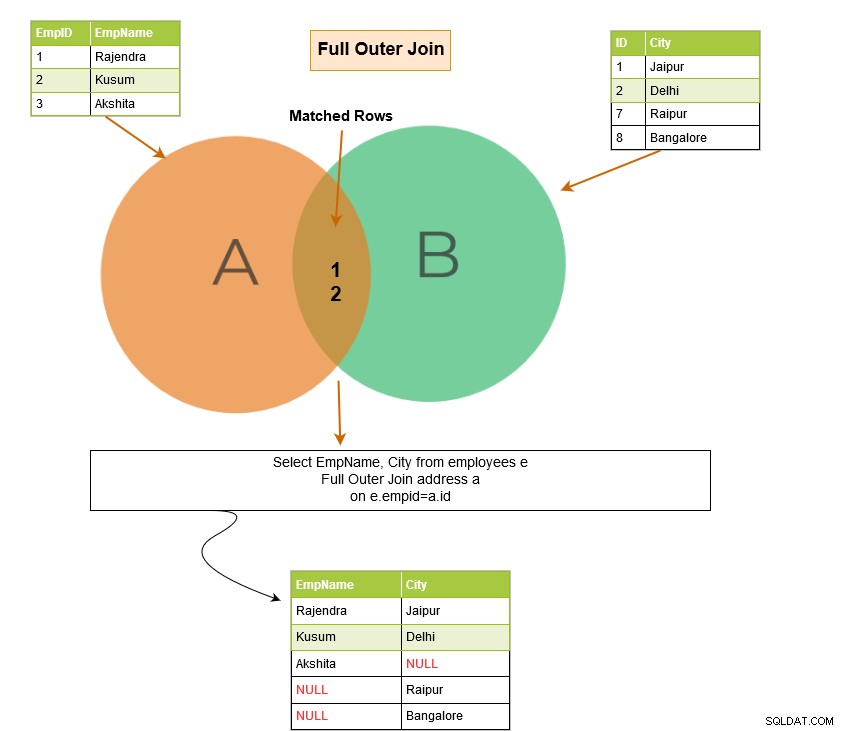
Úplné vnější spojení vrátí ve výstupu následující řádky:
V předchozích příkladech používáme dvě tabulky v dotazu SQL k provádění operací spojení. Většinou spojujeme více tabulek dohromady a vrací relevantní data.
Níže uvedený dotaz používá více vnitřních spojení.
Pojďme analyzovat dotaz v následujících krocích:
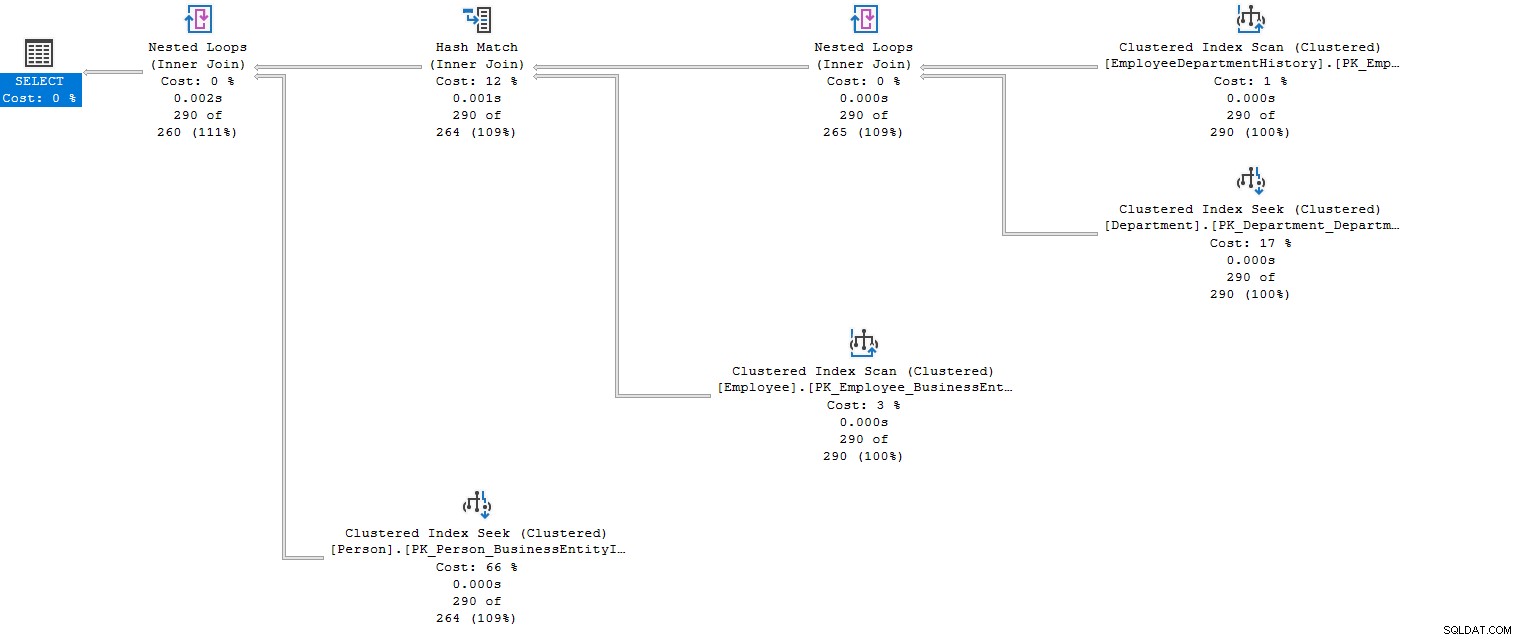
Jakmile spustíte dotaz s více spojeními, optimalizátor dotazů připraví plán provádění. Připravuje nákladově optimalizovaný prováděcí plán splňující podmínky spojení s využitím zdrojů – například v níže uvedeném skutečném plánu provádění se můžeme podívat na více vnořených smyček (vnitřní spojení) a hash match (vnitřní spojení) kombinující data z více spojovacích tabulek. .
Předpokládejme, že ve sloupcích tabulky máme hodnoty NULL a spojíme tabulky v těchto sloupcích. Odpovídá SQL Server hodnotám NULL?
Hodnoty NULL se navzájem neshodují. Proto SQL Server nemohl vrátit odpovídající řádek. V níže uvedeném příkladu máme ve sloupci EmpID tabulky [Zaměstnanci] hodnotu NULL. Proto ve výstupu vrátí odpovídající řádek pouze pro [EmpID] 2.
Tento řádek NULL můžeme získat ve výstupu v případě vnějšího spojení SQL, protože vrací také neshodné řádky.
V tomto článku jsme prozkoumali různé typy spojení SQL. Zde je několik důležitých doporučených postupů, které je třeba pamatovat a používat při používání spojení SQL.Vlastní připojení k SQL
Vzájemné spojení SQL
Vnější spojení SQL
Levý vnější spoj
Pravé vnější spojení
Úplné vnější spojení
Spojení SQL s více tabulkami
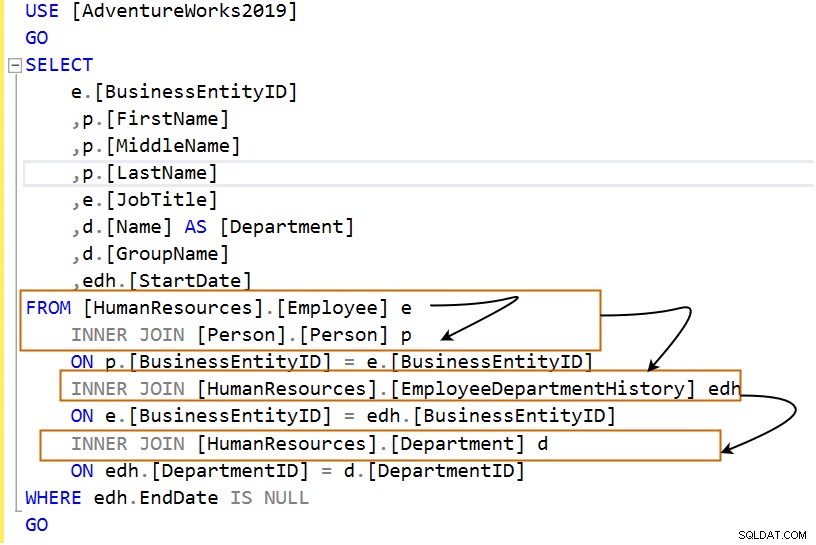
USE [AdventureWorks2019]
GO
SELECT
e.[BusinessEntityID]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,e.[JobTitle]
,d.[Name] AS [Department]
,d.[GroupName]
,edh.[StartDate]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [HumanResources].[EmployeeDepartmentHistory] edh
ON e.[BusinessEntityID] = edh.[BusinessEntityID]
INNER JOIN [HumanResources].[Department] d
ON edh.[DepartmentID] = d.[DepartmentID]
WHERE edh.EndDate IS NULL
GO
Hodnoty NULL a spojení SQL
Osvědčené postupy spojení SQL