Předpokládám, že důvodem je to, že to prostě nepovažovali za prioritní funkci, kterou stojí za to implementovat. Vypadá to, že Postgres dělá podporovat oba
UNION a UNION ALL .
Pokud máte pro tuto funkci silný argument, můžete nám poskytnout zpětnou vazbu na Connect (nebo jaká bude adresa URL jeho nahrazení).
Zabránění přidávání duplikátů může být užitečné, protože duplicitní řádek přidaný v pozdějším kroku k předchozímu téměř vždy skončí tak, že způsobí nekonečnou smyčku nebo překročí maximální limit rekurze.
V standardech SQL
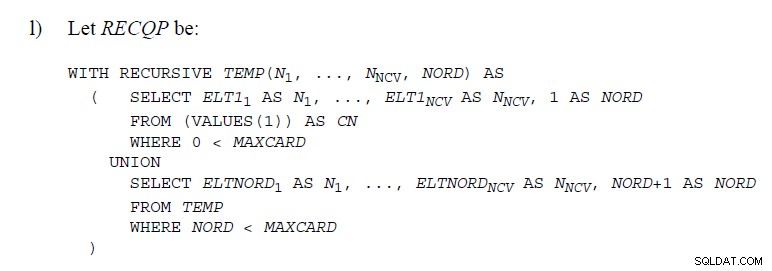
je poměrně dost míst kde je použit kód demonstrující UNION jako níže
Tento článek vysvětluje, jak jsou implementovány v SQL Server . Nic takového „pod pokličkou“ nedělají. Spool zásobníku odstraňuje řádky tak, jak to jde, takže by nebylo možné zjistit, zda je pozdější řádek duplikátem odstraněného řádku. Podpora UNION potřebovalo by to trochu jiný přístup.
Mezitím toho můžete docela snadno dosáhnout ve vícenásobném TVF.
Níže uvádíme hloupý příklad (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Změna UNION na UNION ALL a přidání DISTINCT na konci vás nezachrání před nekonečnou rekurzí.
Ale můžete to implementovat jako
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Výše uvedené používá IGNORE_DUP_KEY vyřadit duplikáty. Pokud je seznam sloupců příliš široký na indexování, budete potřebovat DISTINCT a NOT EXISTS namísto. Pravděpodobně byste také chtěli parametr pro nastavení maximálního počtu rekurzí a zamezení nekonečných smyček.