Ukázka možného vysvětlení.
Vytvořit skript tabulky
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
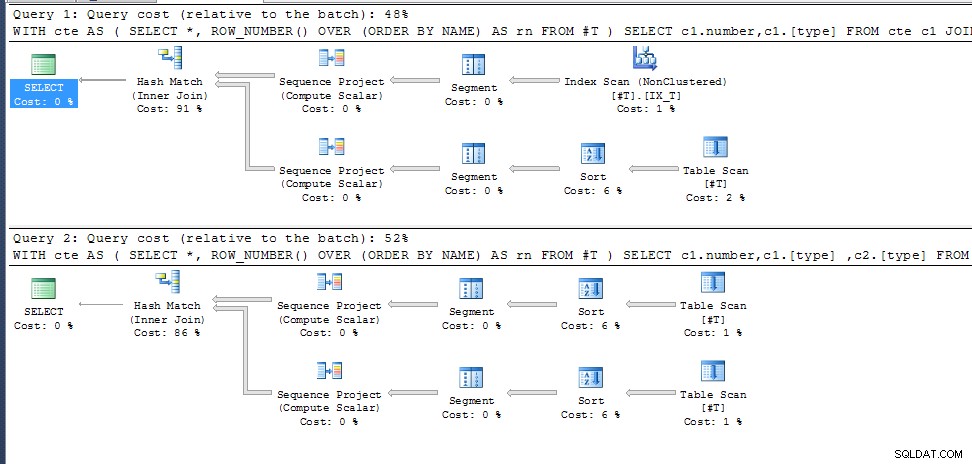
Dotaz jedna (vrátí 35 výsledků)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Dotaz 2 (Stejný jako předtím, ale přidáním c2.[type] do seznamu pro výběr vrátí 0 výsledků);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Proč?
row_number() pro duplicitní názvy NAME není specifikován, takže pouze vybere to, které vyhovuje nejlepšímu plánu provádění pro požadované výstupní sloupce. V druhém dotazu je to stejné pro obě volání cte, v prvním volí jinou přístupovou cestu s výsledným rozdílným číslováním_řádků.
Navrhované řešení
Připojujete se k CTE dne ROW_NUMBER() over (order by t.[Date])
Na rozdíl od toho, co se dalo očekávat, bude CTE pravděpodobně se nezhmotní
což by zajistilo konzistenci pro vlastní spojení, a proto předpokládáte korelaci mezi ROW_NUMBER() na obou stranách, které nemusí existovat pro záznamy, kde je duplicitní [Date] existuje v datech.
Co když zkusíte ROW_NUMBER() over (order by t.[Date], t.[id]) aby bylo zajištěno, že v případě nerozhodných dat bude číslování řádků v zaručeně konzistentním pořadí. (Nebo nějaký jiný sloupec/kombinace sloupců, které mohou odlišit záznamy, pokud to id neudělá)