Ukázkový balíček využívající SSIS 2008 R2, který se vkládá nebo aktualizuje pomocí dávkové operace:
Zde je ukázkový balíček napsaný v SSIS 2008 R2 který ukazuje, jak provádět vkládání, aktualizaci mezi dvěma databázemi pomocí dávkových operací.
- Pomocí
OLE DB Commandzpomalí operace aktualizace vašeho balíčku, protože to nedělá provádět dávkové operace. Každý řádek je aktualizován individuálně.
Ukázka používá dvě databáze, jmenovitě Source a Destination . V mém příkladu jsou obě databáze umístěny na serveru, ale logiku lze stále použít pro databáze umístěné na různých serverech a umístěních.
Vytvořil jsem tabulku s názvem dbo.SourceTable v mé zdrojové databázi Source .
CREATE TABLE [dbo].[SourceTable](
[RowNumber] [bigint] NOT NULL,
[CreatedOn] [datetime] NOT NULL,
[ModifiedOn] [datetime] NOT NULL,
[IsActive] [bit] NULL
)
Také byly vytvořeny dvě tabulky s názvem dbo.DestinationTable a dbo.StagingTable v mé cílové databázi Destination .
CREATE TABLE [dbo].[DestinationTable](
[RowNumber] [bigint] NOT NULL,
[CreatedOn] [datetime] NOT NULL,
[ModifiedOn] [datetime] NOT NULL
)
GO
CREATE TABLE [dbo].[StagingTable](
[RowNumber] [bigint] NOT NULL,
[CreatedOn] [datetime] NOT NULL,
[ModifiedOn] [datetime] NOT NULL
)
GO
Do tabulky dbo.SourceTable bylo vloženo asi 1,4 milionu řádků s jedinečnými hodnotami do RowNumber sloupec. Tabulky dbo.DestinationTable a dbo.StagingTable byly ze začátku prázdné. Všechny řádky v tabulce dbo.SourceTable mít příznak IsActive nastaveno na hodnotu false.
Vytvořil balíček SSIS se dvěma správci připojení OLE DB, z nichž každý se připojuje ke Source a Destination databází. Navrhl řídicí tok, jak je znázorněno níže:
-
První
Execute SQL Taskprovede příkazTRUNCATE TABLE dbo.StagingTableproti cílové databázi ke zkrácení pracovních tabulek. -
Další část vysvětluje, jak
Data Flow Taskje nakonfigurován. -
Druhá
Execute SQL Taskprovede níže uvedený příkaz SQL, který aktualizuje data vdbo.DestinationTablepomocí dat dostupných vdbo.StagingTable, za předpokladu, že existuje jedinečný klíč, který se shoduje mezi těmito dvěma tabulkami. V tomto případě je jedinečným klíčem sloupecRowNumber.
Skript k aktualizaci:
UPDATE D
SET D.CreatedOn = S.CreatedOn
, D.ModifiedOn = S.ModifiedOn
FROM dbo.DestinationTable D
INNER JOIN dbo.StagingTable S
ON D.RowNumber = S.RowNumber

Navrhl jsem úlohu toku dat, jak je uvedeno níže.
-
OLE DB Sourcečte data zdbo.SourceTablepomocí příkazu SQLSELECT RowNumber,CreatedOn, ModifiedOn FROM Source.dbo.SourceTable WHERE IsActive = 1 -
Lookup transformationse používá ke kontrole, zda hodnota RowNumber již existuje v tabulcedbo.DestinationTable -
Pokud záznam není existuje, bude přesměrován na
OLE DB Destinationpojmenované jakoInsert into destination table, který vloží řádek dodbo.DestinationTable -
Pokud záznam existuje , bude přesměrován na
OLE DB Destinationpojmenované jakoInsert into staging table, který vloží řádek dodbo.StagingTable. Tato data v pracovní tabulce budou použita ve druhé `Provedení úlohy SQL k provedení dávkové aktualizace.

Pro aktivaci několika dalších řádků pro zdroj OLE DB jsem spustil níže uvedený dotaz k aktivaci některých záznamů
UPDATE dbo.SourceTable
SET IsActive = 1
WHERE (RowNumber % 9 = 1)
OR (RowNumber % 9 = 2)

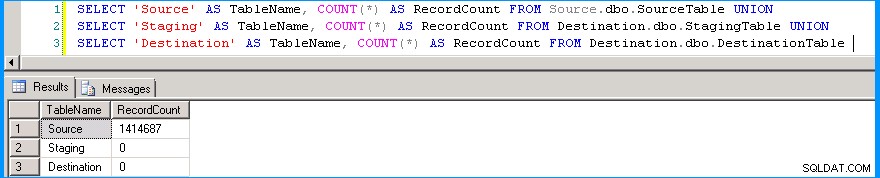
První provedení balíčku vypadalo, jak je ukázáno níže. Všechny řádky byly přesměrovány do cílové tabulky, protože byla prázdná. Spuštění balíčku na mém počítači trvalo asi 3 seconds .


Znovu spusťte dotaz na počet řádků, abyste našli počty řádků ve všech třech tabulkách.

Pro aktivaci několika dalších řádků pro zdroj OLE DB jsem spustil níže uvedený dotaz k aktivaci některých záznamů
UPDATE dbo.SourceTable
SET IsActive = 1
WHERE (RowNumber % 9 = 3)
OR (RowNumber % 9 = 5)
OR (RowNumber % 9 = 6)
OR (RowNumber % 9 = 7)
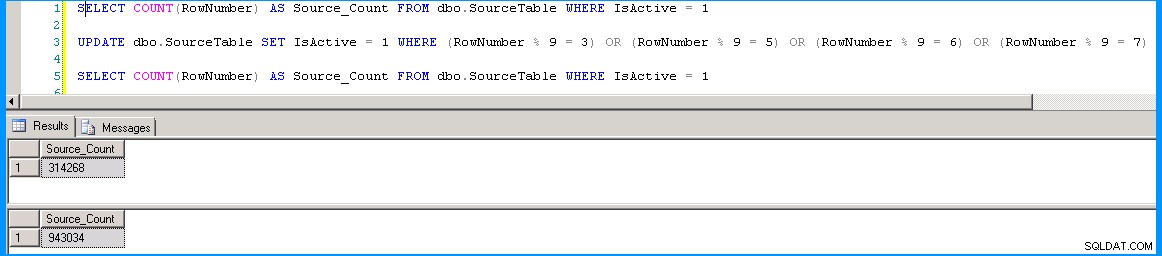
Druhé provedení balíčku vypadalo, jak je ukázáno níže. 314,268 rows které byly dříve vloženy během prvního spuštění byly přesměrovány do pracovní tabulky. 628,766 new rows byly přímo vloženy do cílové tabulky. Spuštění balíčku na mém počítači trvalo asi 12 seconds . 314,268 rows v cílové tabulce byly aktualizovány ve druhé úloze Execute SQL pomocí dat pomocí pracovní tabulky.


Znovu spusťte dotaz na počet řádků, abyste našli počty řádků ve všech třech tabulkách.

Doufám, že vám to dá nápad na implementaci vašeho řešení.