Když pracujete na projektu, který se skládá z mnoha mikroslužeb, bude pravděpodobně zahrnovat také více databází.
Můžete mít například databázi MySQL a databázi PostgreSQL, obě běží na samostatných serverech.
Pro spojení dat ze dvou databází byste obvykle museli zavést novou mikroslužbu, která by data spojila. Ale to by zvýšilo složitost systému.
V tomto tutoriálu použijeme Materialise ke spojení MySQL a Postgres v živém materializovaném zobrazení. Poté budeme schopni dotazovat se přímo a získat zpět výsledky z obou databází v reálném čase pomocí standardního SQL.
Materialize je zdrojově dostupná streamovací databáze napsaná v Rustu, která uchovává výsledky SQL dotazu (materializované zobrazení) v paměti, jak se data mění.
Výukový program obsahuje ukázkový projekt, který můžete začít pomocí docker-compose .
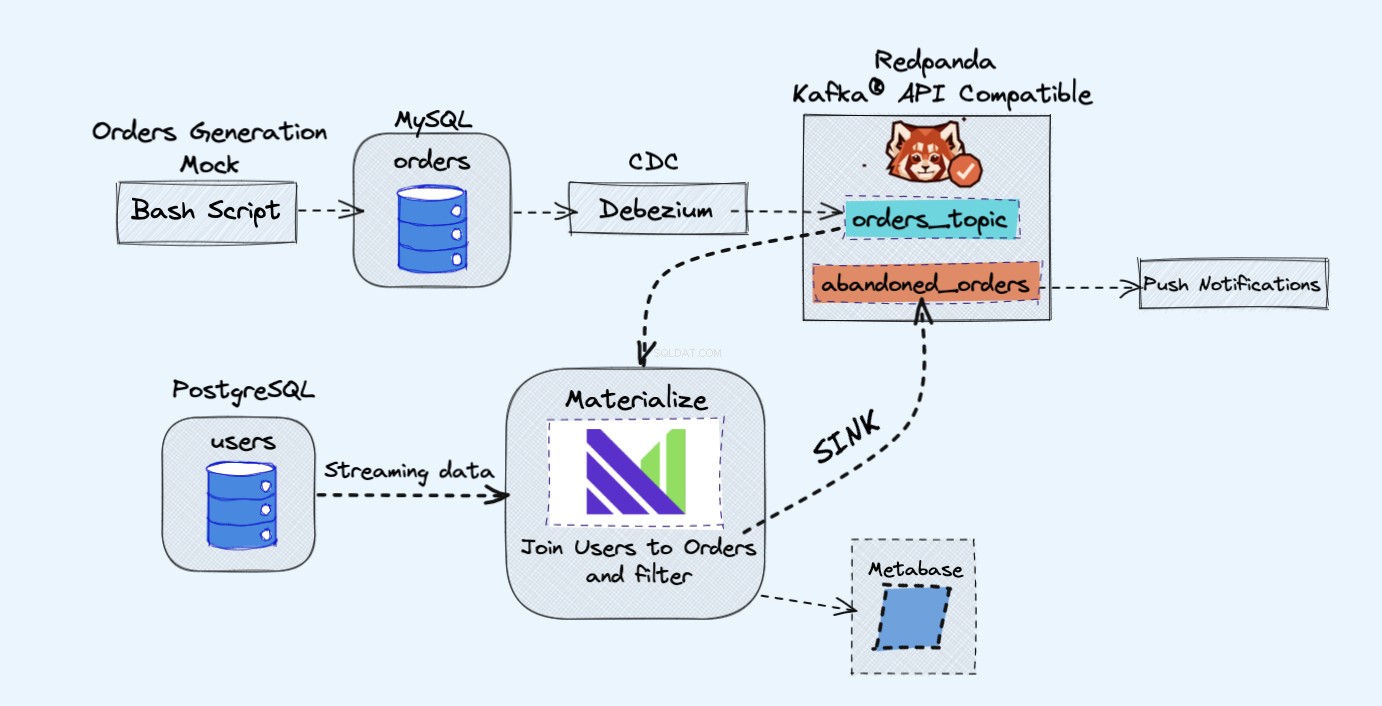
Demo projekt, který budeme používat, bude sledovat objednávky na našem falešném webu. Bude generovat události, které by mohly být později použity k odesílání upozornění, když byl košík po dlouhou dobu opuštěný.
Architektura demo projektu je následující:
Předpoklady
Všechny služby, které budeme používat v ukázce, poběží v kontejnerech Docker, takže nebudete muset instalovat žádné další služby na svůj notebook nebo server, nikoli Docker a Docker Compose.
V případě, že ještě nemáte nainstalované Docker a Docker Compose, můžete postupovat podle oficiálních pokynů, jak to udělat zde:
- Nainstalujte Docker
- Nainstalujte Docker Compose
Přehled
Jak je znázorněno na obrázku výše, budeme mít následující součásti:
- Simulovaná služba pro nepřetržité generování objednávek.
- Objednávky budou uloženy v databázi MySQL .
- Při zápisu do databáze Debezium streamuje změny z MySQL do Redpanda téma.
- Budeme mít také Postgres databáze, kam můžeme získat naše uživatele.
- Toto téma Redpanda pak vložíme do Materializovat přímo spolu s uživateli z databáze Postgres.
- Ve Materialize spojíme naše objednávky a uživatele, provedeme filtrování a vytvoříme materializované zobrazení, které zobrazuje informace o opuštěném košíku.
- Potom vytvoříme jímku, abychom odeslali data opuštěného košíku do nového tématu Redpanda.
- Nakonec použijeme Metabázi k vizualizaci dat.
- Později byste mohli informace z tohoto nového tématu použít k rozesílání oznámení svým uživatelům a připomínat jim, že mají opuštěný košík.
Jako okrajovou poznámku byste měli zcela v pořádku používat Kafku místo Redpanda. Líbí se mi jednoduchost, kterou Redpanda přináší, protože můžete spustit jedinou instanci Redpanda namísto všech komponent Kafka.
Jak spustit ukázku
Nejprve začněte klonováním úložiště:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Poté můžete vstoupit do adresáře:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Začněme tím, že nejprve spustíme kontejner Redpanda:
docker-compose up -d redpanda
Vytvořte obrázky:
docker-compose build
Nakonec spusťte všechny služby:
docker-compose up -d
Chcete-li spustit Materialize CLI, můžete spustit následující příkaz:
docker-compose run mzcli
Toto je jen zkratka ke kontejneru Docker s postgres-client předinstalovaný. Pokud již máte psql můžete spustit psql -U materialize -h localhost -p 6875 materialize místo toho.
Jak vytvořit materializovaný zdroj Kafky
Nyní, když jste v Materialize CLI, pojďme definovat orders tabulky v mysql.shop databáze jako zdroje Redpanda:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Pokud byste měli zkontrolovat dostupné sloupce z orders zdroj spuštěním následujícího příkazu:
SHOW COLUMNS FROM orders;
Mohli byste vidět, že když Materialize stahuje data schématu zpráv z registru Redpanda, zná typy sloupců, které se mají použít pro každý atribut:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Jak vytvářet materializované pohledy
Dále vytvoříme náš první materializovaný pohled, abychom získali všechna data z orders Zdroj Redpanda:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Nyní můžete použít SELECT * FROM abandoned_orders; zobrazíte výsledky:
SELECT * FROM abandoned_orders;
Další informace o vytváření materializovaných pohledů najdete v sekci Materialized Views v dokumentaci Materialize.
Jak vytvořit zdroj Postgres
Existují dva způsoby, jak vytvořit zdroj Postgres v Materialize:
- Používání Debezium stejně jako u zdroje MySQL.
- Pomocí Postgres Materialise Source, který vám umožňuje propojit Materialise přímo s Postgres, takže nemusíte používat Debezium.
Pro toto demo použijeme Postgres Materialise Source jen jako ukázku toho, jak jej používat, ale klidně místo něj použijte Debezium.
Pro vytvoření Postgres Materialise Source spusťte následující příkaz:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Rychlé shrnutí výše uvedeného prohlášení:
MATERIALIZED:Zhmotní data zdroje PostgreSQL. Všechna data jsou uchovávána v paměti a umožňují přímou volbu zdrojů.mz_source:Název zdroje PostgreSQL.CONNECTION:Parametry připojení PostgreSQL.PUBLICATION:Publikace PostgreSQL obsahující tabulky, které mají být streamovány do Materialize.
Jakmile vytvoříme zdroj PostgreSQL, abychom mohli dotazovat tabulky PostgreSQL, museli bychom vytvořit pohledy, které představují původní tabulky upstreamové publikace.
V našem případě máme pouze jednu tabulku s názvem users takže příkaz, který bychom potřebovali spustit, je:
CREATE VIEWS FROM SOURCE mz_source (users);
Chcete-li zobrazit dostupné pohledy, proveďte následující příkaz:
SHOW FULL VIEWS;
Jakmile to uděláte, můžete se přímo dotazovat na nové pohledy:
SELECT * FROM users;
Dále pojďme do toho a vytvořte několik dalších zobrazení.
Jak vytvořit dřez Kafka
Sinks vám umožňují odesílat data z Materialize do externího zdroje.
Pro tuto ukázku budeme používat Redpanda.
Redpanda je kompatibilní s Kafka API a Materialize z ní dokáže zpracovávat data stejně jako by zpracovávala data ze zdroje Kafka.
Pojďme vytvořit materializovaný pohled, který bude obsahovat všechny nezaplacené objednávky s velkým objemem:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Jak můžete vidět, zde se ve skutečnosti připojujeme k users zobrazení, které zpracovává data přímo z našeho zdroje Postgres, a abandond_orders zobrazení, které společně zpracovává data z tématu Redpanda.
Vytvořme Sink, kam budeme posílat data výše uvedeného materializovaného pohledu:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Nyní, pokud byste se měli připojit ke kontejneru Redpanda a použít rpk topic consume příkazem, budete moci číst záznamy z tématu.
Prozatím však nebudeme moci zobrazit náhled výsledků pomocí rpk protože je ve formátu AVRO. Redpanda by to s největší pravděpodobností implementovala v budoucnu, ale v tuto chvíli můžeme téma skutečně streamovat zpět do Materialize, abychom potvrdili formát.
Nejprve získejte název tématu, které bylo automaticky vygenerováno:
SELECT topic FROM mz_kafka_sinks;
Výstup:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
Další informace o tom, jak se generují názvy témat, naleznete v dokumentaci zde.
Poté vytvořte nový materializovaný zdroj z tohoto tématu Redpanda:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Nezapomeňte odpovídajícím způsobem změnit název tématu!
Nakonec zadejte dotaz na tento nový materializovaný pohled:
SELECT * FROM high_volume_orders_test LIMIT 2;
Nyní, když máte data v tématu, můžete se k nim připojit další služby a využívat je a poté spouštět například e-maily nebo upozornění.
Jak připojit metabázi
Chcete-li získat přístup k instanci metabáze, navštivte https://localhost:3030 pokud demo spouštíte lokálně nebo https://your_server_ip:3030 pokud spouštíte demo na serveru. Poté postupujte podle kroků k dokončení nastavení metabáze.
Ujistěte se, že jste jako zdroj dat vybrali Materialize.
Jakmile budete připraveni, budete moci svá data vizualizovat stejně jako se standardní PostgreSQL databází.
Jak zastavit ukázku
Chcete-li zastavit všechny služby, spusťte následující příkaz:
docker-compose down
Závěr
Jak vidíte, toto je velmi jednoduchý příklad toho, jak používat Materialise. Materialize můžete použít ke zpracování dat z různých zdrojů a poté je streamovat do různých cílů.
Užitečné zdroje:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT