Už jsou to téměř dva měsíce, co jsme vydali SCUMM (Severalnines ClusterControl Unified Management and Monitoring). SCUMM využívá Prometheus jako základní metodu pro shromažďování dat časových řad od exportérů běžících na databázových instancích a nástrojích pro vyrovnávání zatížení. Tento blog vám ukáže, jak opravit problémy, když exportéry Prometheus neběží, nebo když grafy nezobrazují data nebo nezobrazují „Žádné datové body“.
Co je Prometheus?
Prometheus je open-source monitorovací systém s dimenzionálním datovým modelem, flexibilním dotazovacím jazykem, efektivní databází časových řad a moderním přístupem k upozorňování. Jedná se o monitorovací platformu, která shromažďuje metriky ze sledovaných cílů seškrabováním metrik z koncových bodů HTTP na tyto cíle. Poskytuje rozměrová data, výkonné dotazy, skvělou vizualizaci, efektivní úložiště, jednoduché ovládání, přesné upozornění, mnoho klientských knihoven a mnoho integrací.
Prometheus v akci pro SCUMM Dashboards
Prometheus shromažďuje data metrik od exportérů, přičemž každý exportér běží na databázi nebo hostiteli nástroje pro vyrovnávání zatížení. Níže uvedený diagram ukazuje, jak jsou tito exportéři propojeni se serverem hostujícím proces Prometheus. Ukazuje, že uzel ClusterControl má spuštěný Prometheus, kde také spouští process_exporter a node_exporter.
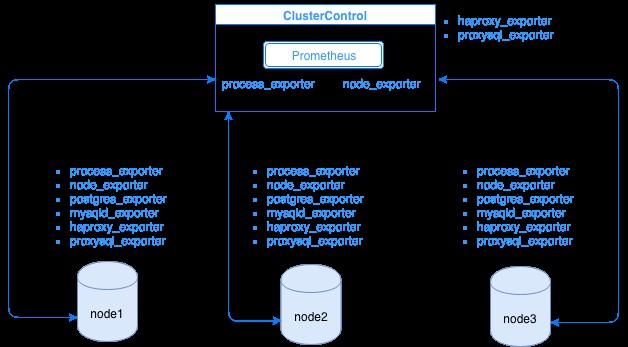
Diagram ukazuje, že Prometheus běží na hostiteli ClusterControl a exportérech process_exporter a node_exporter běží také ke shromažďování metrik z vlastního uzlu. Volitelně můžete jako cíl nastavit také hostitele ClusterControl, ve kterém můžete nastavit HAProxy nebo ProxySQL.
Pro uzly clusteru výše (node1, node2 a node3) může mít spuštěný mysqld_exporter nebo postgres_exporter, což jsou agenti, kteří interně seškrabují data v tomto uzlu a předávají je serveru Prometheus a ukládají je do vlastního úložiště dat. Jeho fyzická data můžete najít pomocí /var/lib/prometheus/data v hostiteli, kde je Prometheus nastaven.
Když nastavujete Prometheus například v hostiteli ClusterControl, měly by mít otevřené následující porty. Viz níže:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusNa základě výstupu mám také spuštěn ProxySQL na hostitelském testccnode, ve kterém je hostován ClusterControl.
Běžné problémy s řídicími panely SCUMM používajícími Prometheus
Když jsou řídicí panely povoleny, ClusterControl nainstaluje a nasadí binární soubory a exportéry, jako jsou node_exporter, process_exporter, mysqld_exporter, postgres_exporter a daemon. Toto jsou běžné sady balíčků pro uzly databáze. Po nastavení a instalaci se spustí a spustí následující příkazy démona, jak je vidět níže:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusPro uzel PostgreSQL
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterMá stejné exportéry jako uzel MySQL, ale liší se pouze u postgres_exporter, protože se jedná o uzel databáze PostgreSQL.
Pokud však uzel utrpí přerušení napájení, zhroucení systému nebo restartování systému, tyto exportéry přestanou běžet. Prometheus ohlásí, že vývozce je mimo provoz. ClusterControl navzorkuje samotný Prometheus a zeptá se na statusy exportéra. Bude tedy jednat podle těchto informací a restartuje exportér, pokud je mimo provoz.
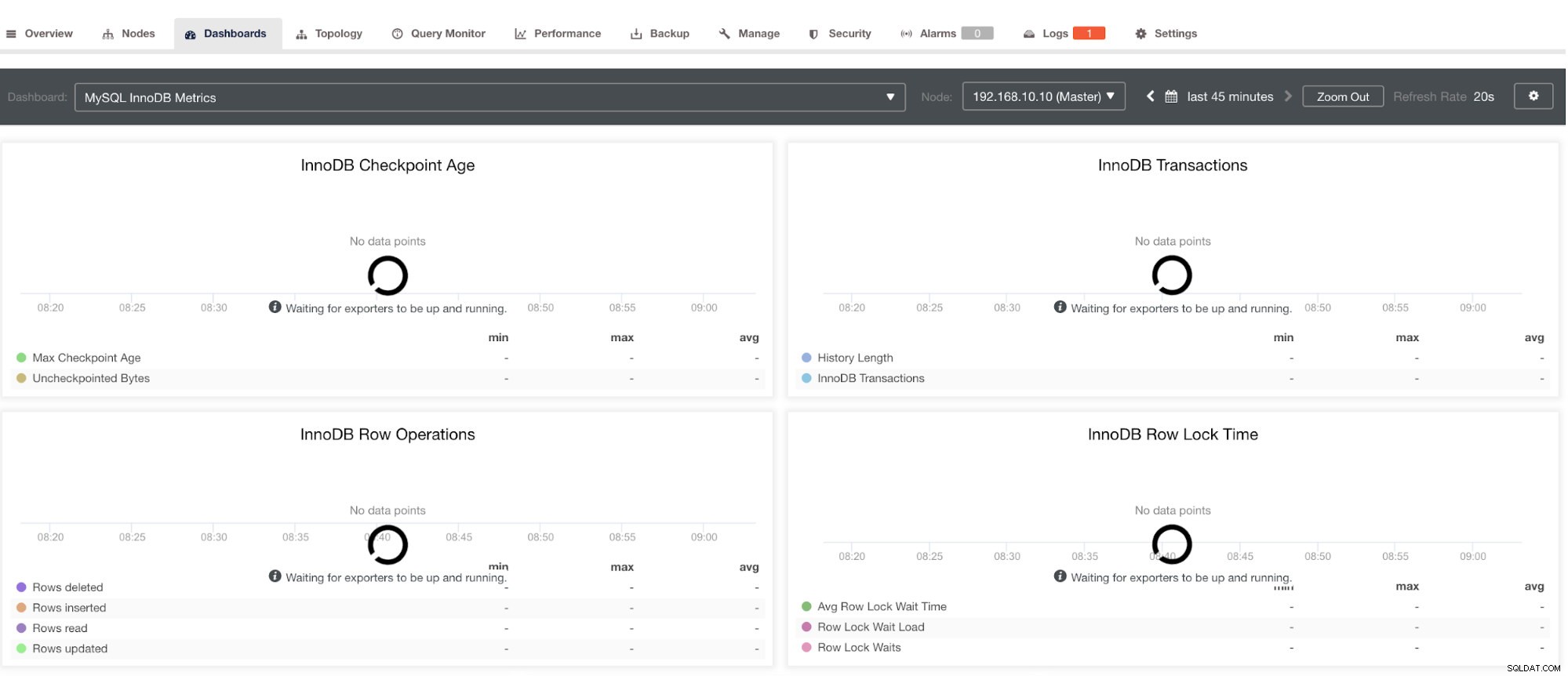
Upozorňujeme však, že exportéry, které nebyly nainstalovány prostřednictvím ClusterControl, nebudou po havárii restartovány. Důvodem je, že nejsou monitorovány systemd nebo démonem, který funguje jako bezpečnostní skript, který by restartoval proces při zhroucení nebo abnormálním vypnutí. Snímek obrazovky níže tedy ukáže, jak to vypadá, když exportéři neběží. Viz níže:
a v PostgreSQL Dashboard bude mít v grafu stejnou ikonu načítání se štítkem „Žádné datové body“. Viz níže:
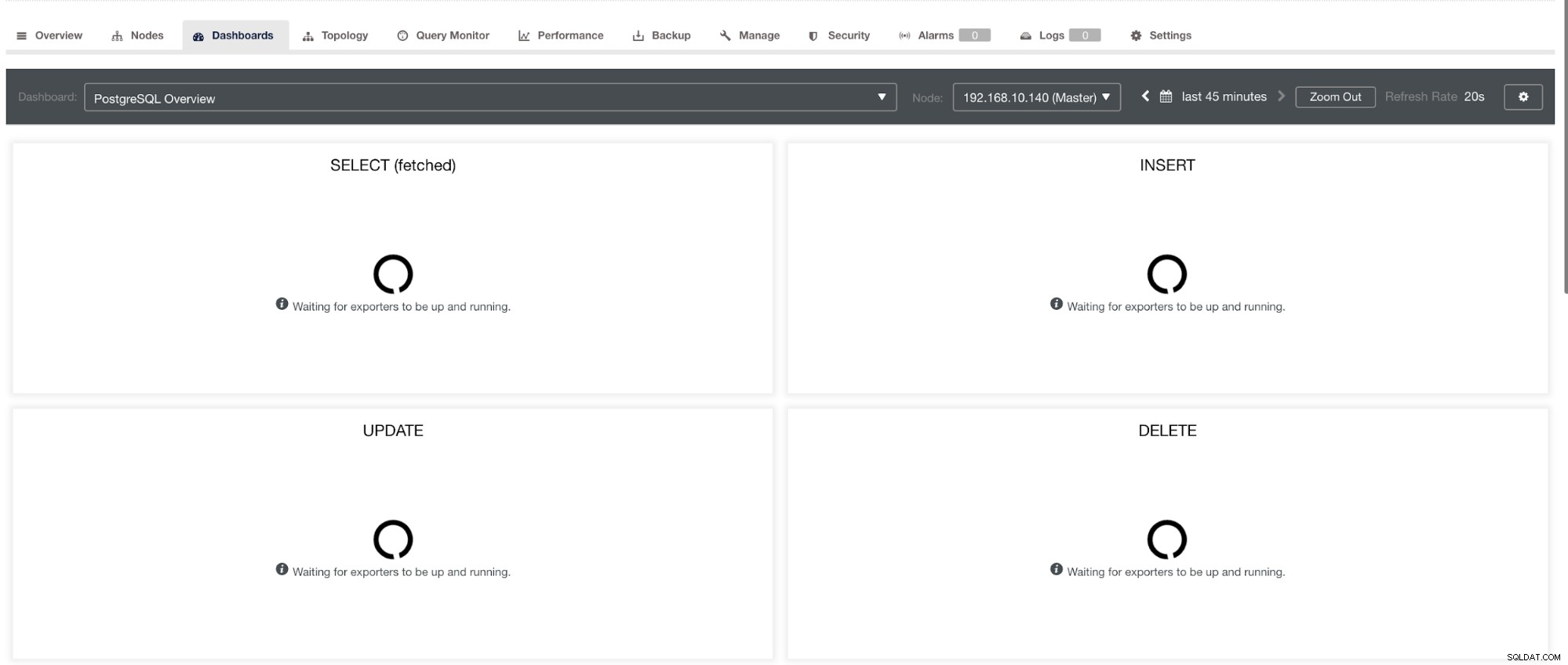
Lze je tedy odstranit pomocí různých technik, které budou následovat v následujících částech.
Odstraňování problémů s Prometheus
Agenti Prometheus, známí jako exportéři, používají následující porty:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter) a vlastní 90, který vlastní 900 proces. Toto jsou porty pro tyto agenty, které používá ClusterControl.
Chcete-li začít s odstraňováním problémů s řídicím panelem SCUMM, můžete začít kontrolou portů otevřených z uzlu databáze. Můžete se řídit následujícími seznamy:
-
Zkontrolujte, zda jsou porty otevřené
např.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporMůže nastat možnost, že porty nejsou otevřené kvůli firewallu (jako je iptables nebo firewalld), který mu brání v otevření portu, nebo že samotný démon procesu není spuštěn.
-
Použijte curl z hostitelského monitoru a ověřte, zda je port dosažitelný a otevřený.
např.
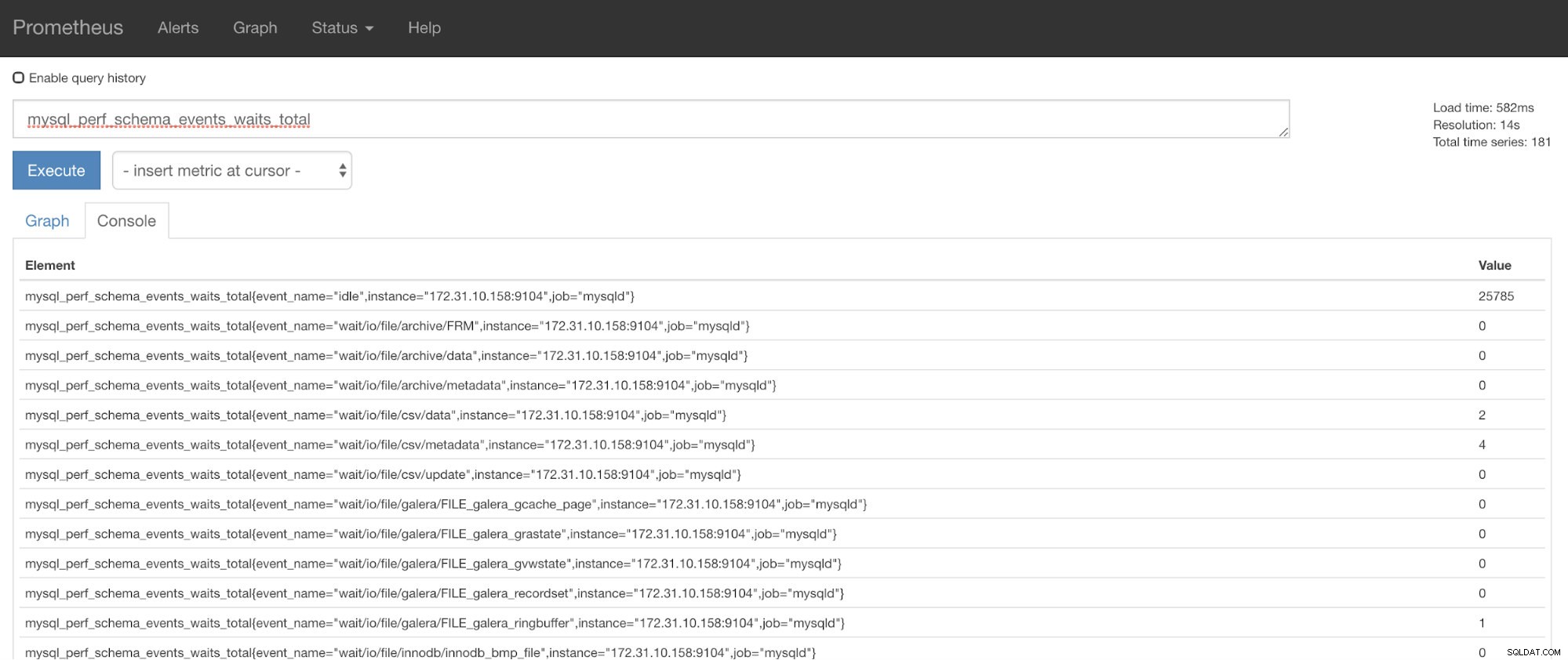
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0V ideálním případě jsem tento přístup prakticky považoval za proveditelný pro mě, protože mohu snadno grepovat a ladit z terminálu.
-
Proč nepoužít webové uživatelské rozhraní?
-
Prometheus zpřístupňuje port 9090, který používá ClusterControl v našich řídicích panelech SCUMM. Kromě toho lze porty, které exportéři odhalují, použít také k odstraňování problémů a určování dostupných názvů metrik pomocí PromQL. Na serveru, kde běží Prometheus, můžete navštívit https://
:9090/targets . Snímek obrazovky níže to ukazuje v akci: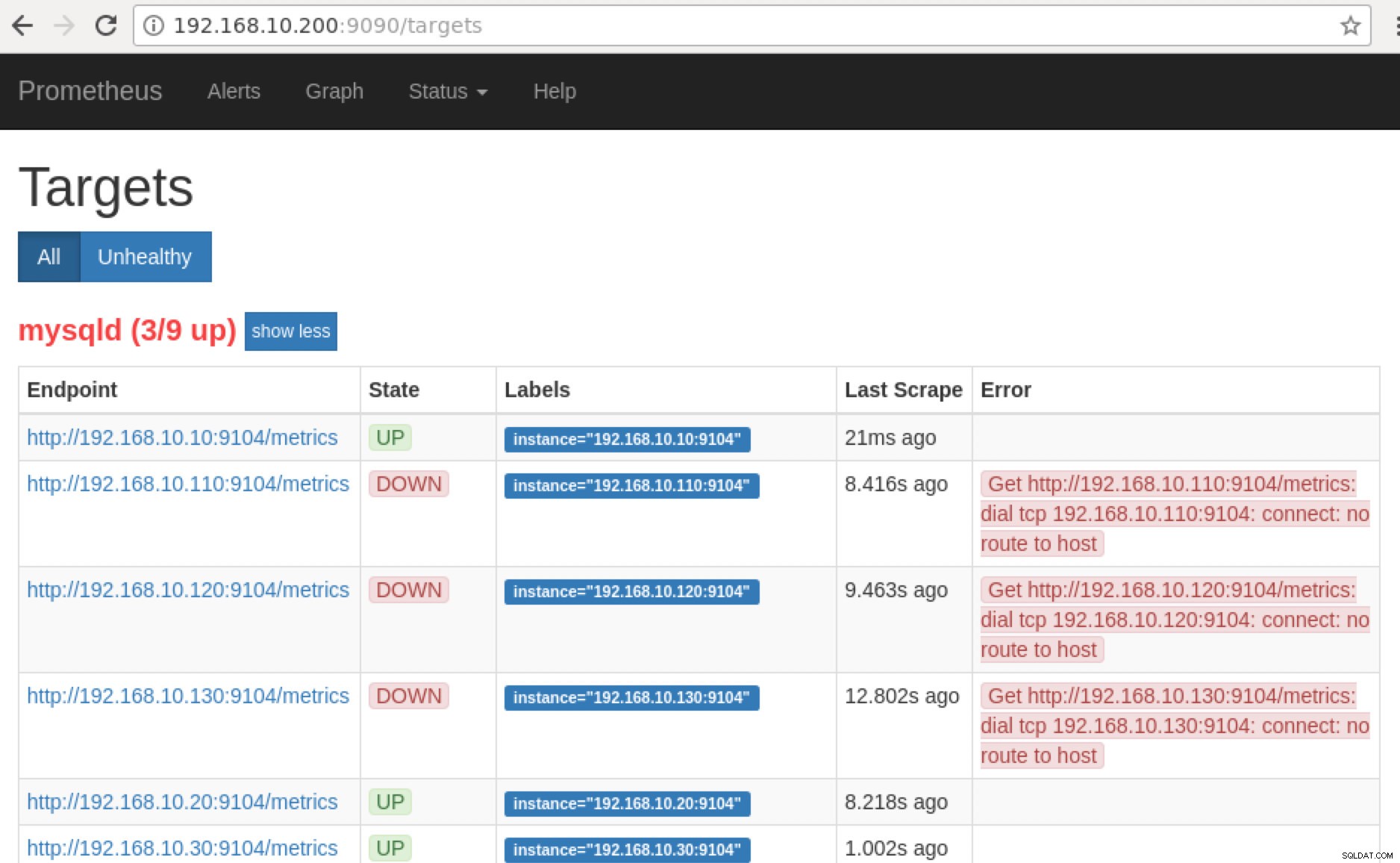
a kliknutím na „Koncové body“ můžete ověřit metriky stejně jako snímek obrazovky níže:
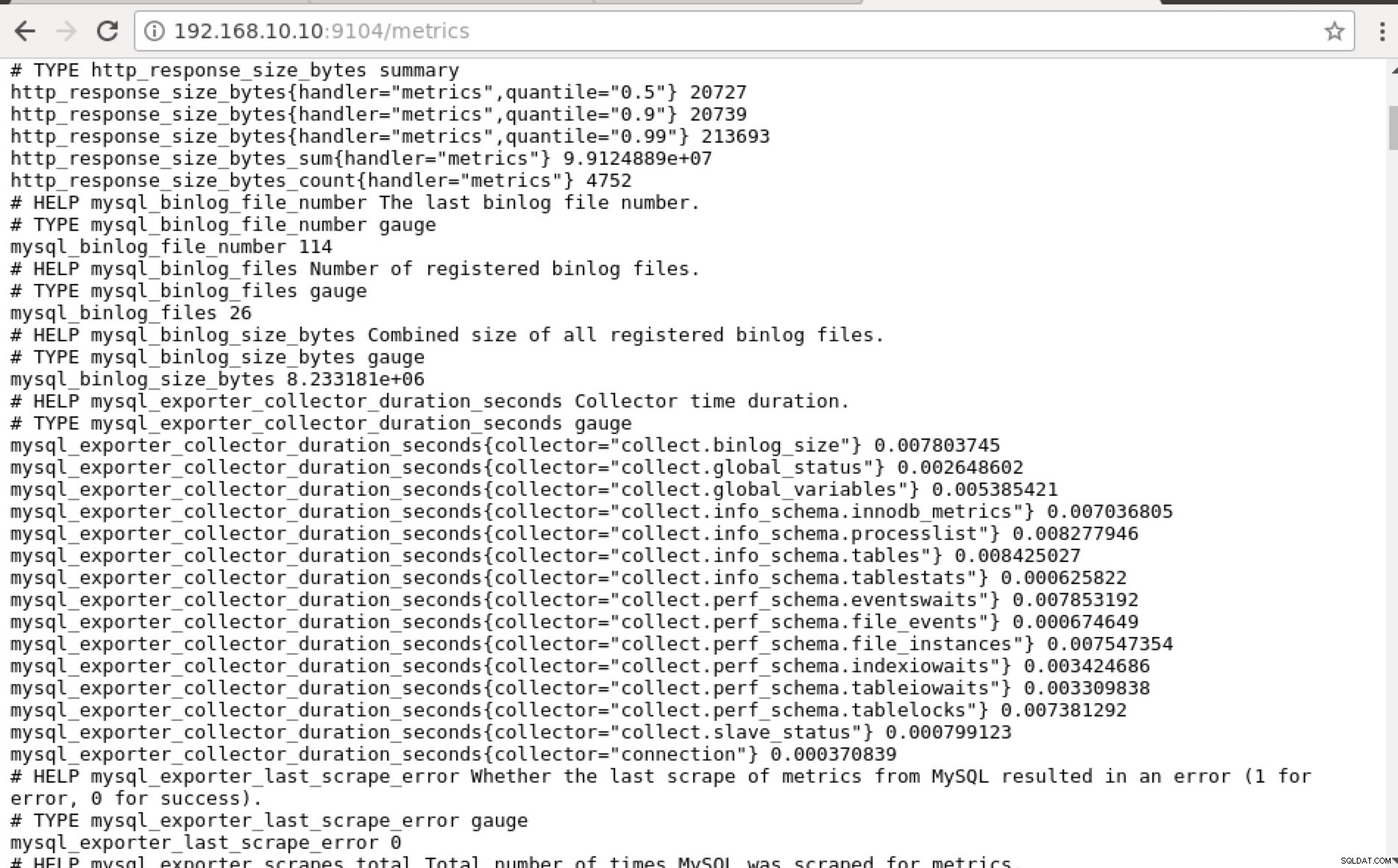
Namísto použití IP adresy to můžete také zkontrolovat lokálně prostřednictvím localhost na konkrétním uzlu, například návštěvou https://localhost:9104/metrics buď ve webovém rozhraní uživatelského rozhraní nebo pomocí cURL.
Nyní, pokud se vrátíme k „Cíle “, můžete vidět seznam uzlů, kde může být problém s portem. Důvody, které to mohou způsobit, jsou uvedeny níže:
- Server nefunguje
- Síť je nedostupná nebo porty nejsou otevřeny kvůli spuštěné bráně firewall
- Démon neběží tam, kde je
_exporter neběží. Například neběží mysqld_exporter.
-
Když jsou tyto exportéry spuštěny, můžete spustit a spustit proces pomocí démona příkaz. Můžete se odkázat na dostupné běžící procesy, které jsem použil ve výše uvedeném příkladu nebo které jsem uvedl v předchozí části tohoto blogu.
A co ty grafy „Žádné datové body“ na mém řídicím panelu?
SCUMM Dashboards přichází s obecným scénářem použití, který MySQL běžně používá. Existují však některé proměnné, kdy vyvolání takové metriky nemusí být dostupné pro konkrétní verzi MySQL nebo dodavatele MySQL, jako je MariaDB nebo Percona Server.
Níže uvedu příklad:
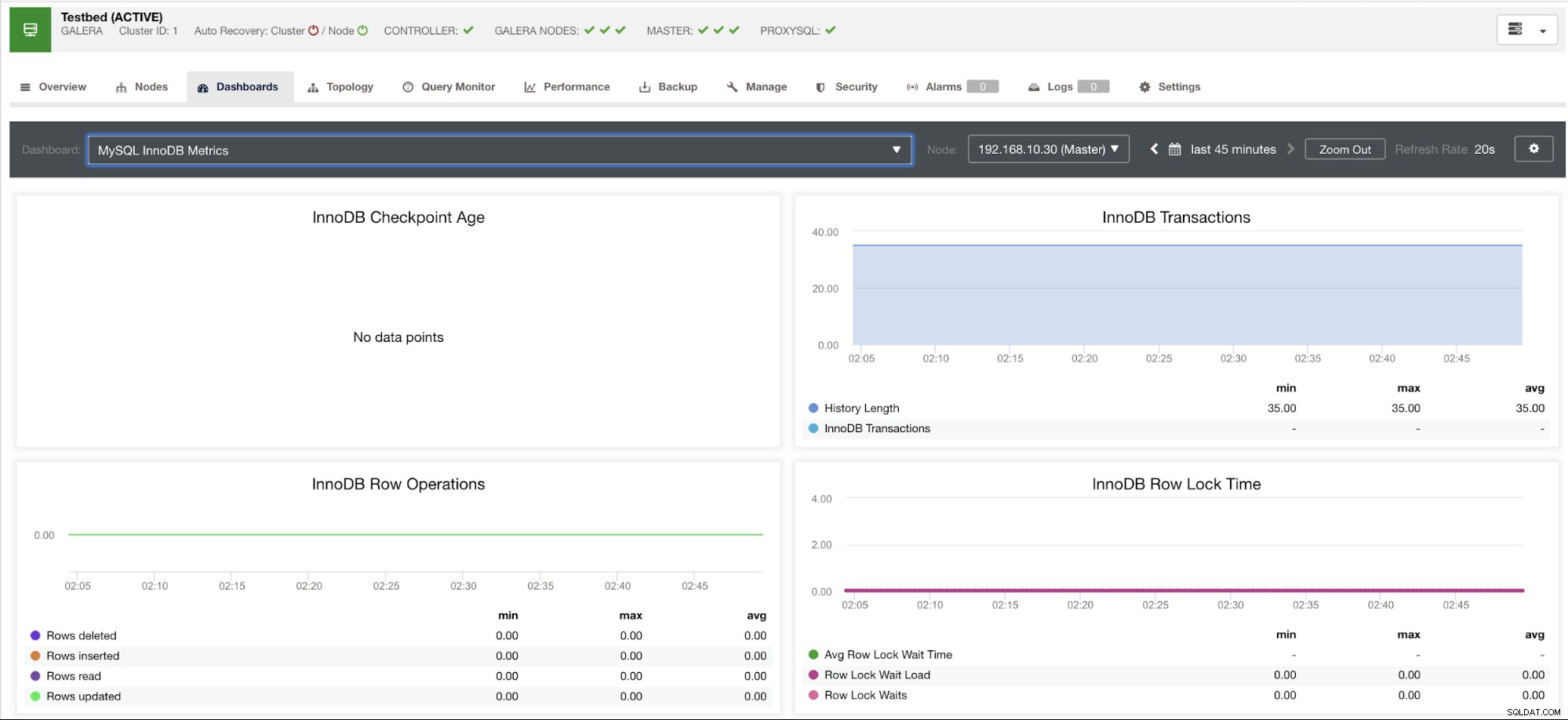
Tento graf byl pořízen na databázovém serveru spuštěném na serveru MariaDB verze 10.3.9-MariaDB-log s verzí wsrep_patch_version instance wsrep_25.23. Nyní je otázkou, proč se nenačítají žádné datové body? Když jsem se dotázal uzlu na stav stáří kontrolního bodu, ukázalo se, že je prázdný nebo že nebyla nalezena žádná proměnná. Viz níže:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Nemám ponětí, proč MariaDB nemá tuto proměnnou (pokud máte odpověď, dejte nám vědět v sekci komentářů tohoto blogu). To je na rozdíl od Percona XtraDB Cluster Server, kde proměnná Innodb_checkpoint_max_age existuje. Viz níže:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)To však znamená, že mohou existovat grafy, které nemají shromážděné datové body, protože nemají žádná data sklízená pro tuto konkrétní metriku, když byl proveden dotaz Prometheus.
Graf, který nemá datové body, však neznamená, že ho vaše aktuální verze MySQL nebo její varianta nepodporuje. Například existují určité grafy, které vyžadují určité proměnné, které je třeba správně nastavit nebo povolit.
Následující část ukáže, co tyto grafy jsou.
Graf posunutí stavu indexu (ICP)

Tento graf byl zmíněn v mém předchozím blogu. Spoléhá na globální proměnnou MySQL s názvem innodb_monitor_enable. Tato proměnná je dynamická, takže ji můžete nastavit bez tvrdého restartu databáze MySQL. Vyžaduje také innodb_monitor_enable =module_icp nebo můžete tuto globální proměnnou nastavit na innodb_monitor_enable =all. Abyste se vyhnuli takovým případům a nedorozuměním ohledně toho, proč takový graf nezobrazuje žádné datové body, možná budete muset používat všechny, ale opatrně. Když je tato proměnná zapnuta a nastavena na all, může dojít k určité režii.
Grafy schématu výkonu MySQL
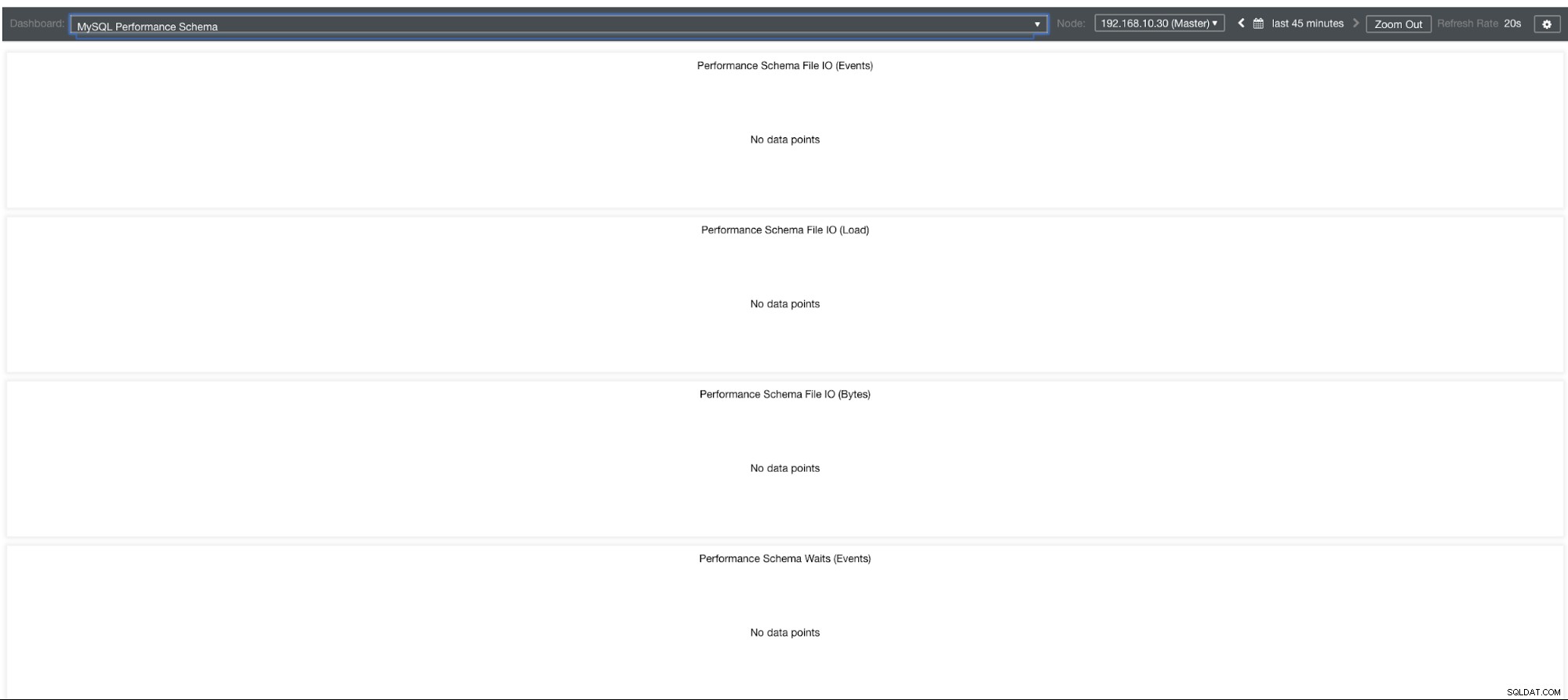
Proč tedy tyto grafy zobrazují „Žádné datové body“? Když vytvoříte cluster pomocí ClusterControl pomocí našich šablon, ve výchozím nastavení bude definovat proměnné performance_schema. Například tyto proměnné níže jsou nastaveny:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Pokud však performance_schema =OFF, pak je to důvod, proč by související grafy zobrazovaly „Žádné datové body“.
Ale mám povolené schéma performance, proč jsou další grafy stále problémem?
Stále existují grafy, které vyžadují nastavení více proměnných. To už jsme řešili v našem předchozím blogu. Musíte tedy nastavit innodb_monitor_enable =all a userstat=1. Výsledek by vypadal takto:
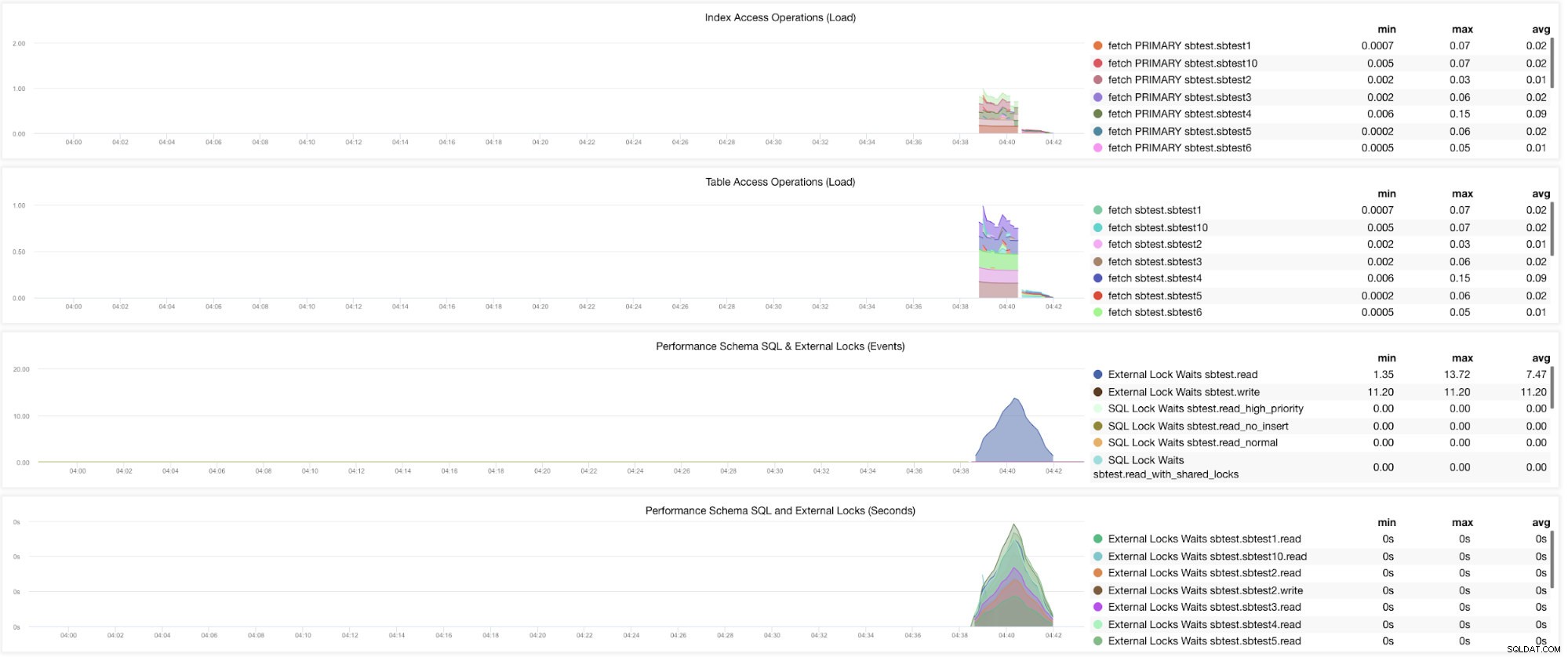
Všiml jsem si však, že ve verzi MariaDB 10.3 (zejména 10.3.11) nastavení performance_schema=ON vyplní metriky potřebné pro řídicí panel MySQL Performance Schema Dashboard. To je velká výhoda, protože se nemusí nastavovat innodb_monitor_enable=ON, což by zvýšilo režii databázového serveru navíc.
Pokročilé odstraňování problémů
Mohu doporučit nějaké pokročilé řešení problémů? Ano, tam je! Potřebujete však alespoň nějaké znalosti JavaScriptu. Vzhledem k tomu, že řídicí panely SCUMM používající Prometheus spoléhají na highcharts, způsob, jakým se metriky, které se používají pro požadavky PromQL, lze určit pomocí skriptu app.js, který je zobrazen níže:
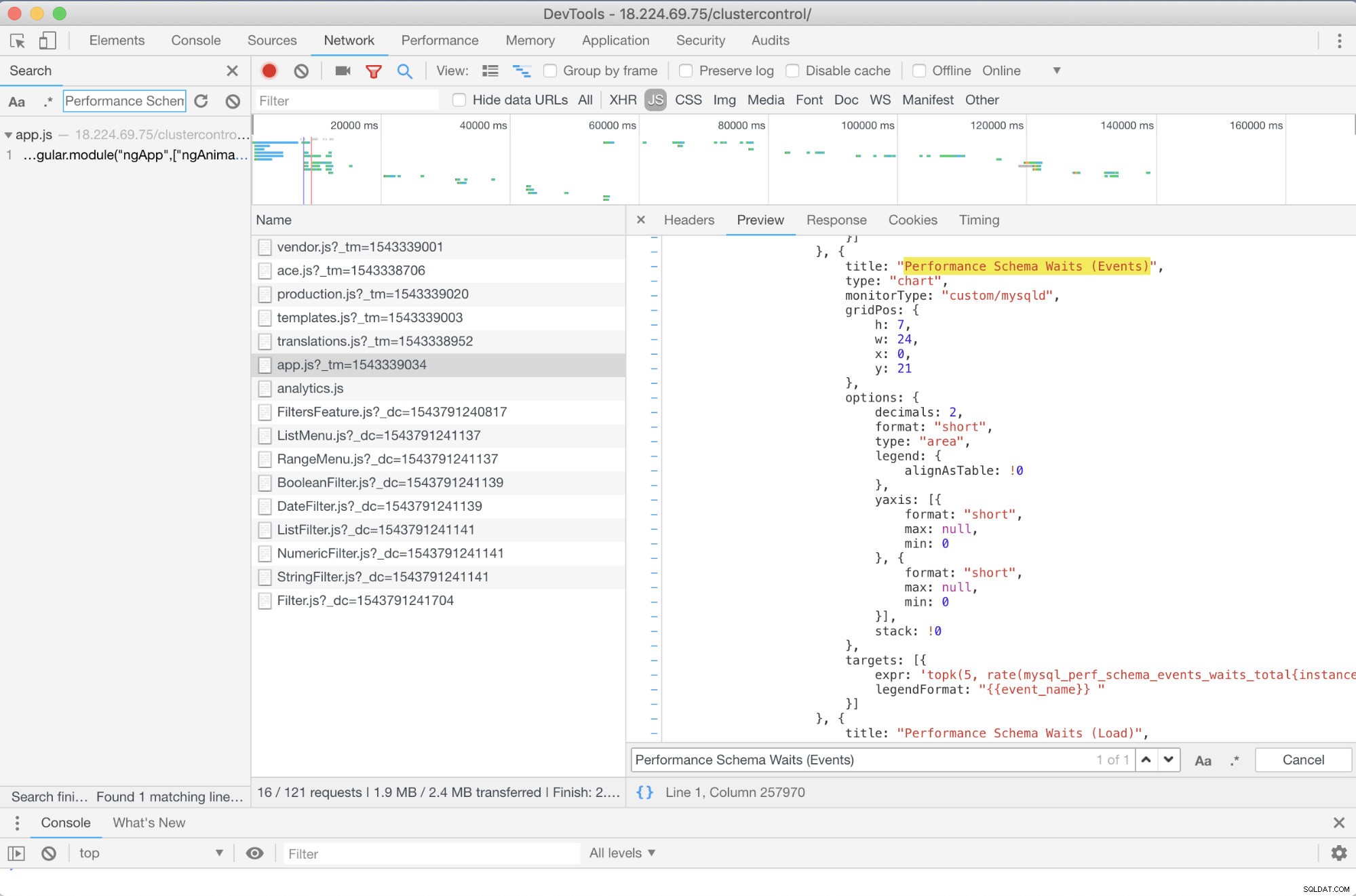
V tomto případě tedy používám DevTools Google Chrome a pokusil jsem se vyhledat Performance Schema Waits (Events) . Jak to může pomoci? Když se podíváte na cíle, uvidíte:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
Nyní můžete použít požadované metriky, což je mysql_perf_schema_events_waits_total. Můžete to zkontrolovat například tak, že projdete https://
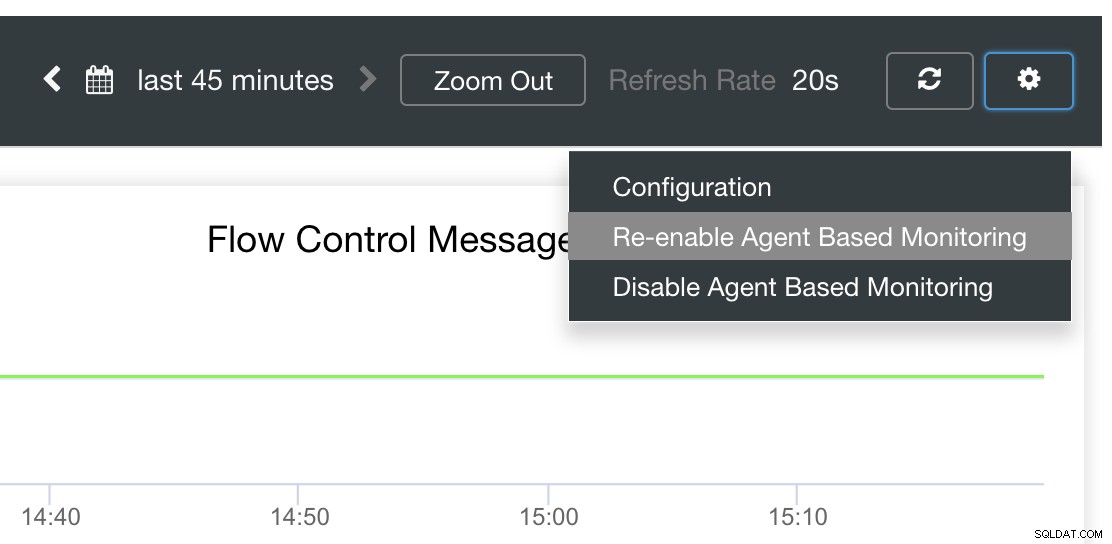
ClusterControl Auto-Recovery k záchraně!
A konečně, hlavní otázkou je, existuje snadný způsob, jak restartovat neúspěšné vývozce? Ano! Již dříve jsme zmínili, že ClusterControl sleduje stav exportů a v případě potřeby je restartuje. V případě, že si všimnete, že SCUMM Dashboards nenačítají grafy normálně, ujistěte se, že máte povolenou funkci Auto Recovery. Viz obrázek níže:

Když je toto povoleno, zajistí to, že
Je také možné znovu nainstalovat nebo nakonfigurovat exportéry.
Závěr
V tomto blogu jsme viděli, jak ClusterControl využívá Prometheus k nabízení SCUMM Dashboards. Poskytuje výkonnou sadu funkcí, od monitorovacích dat ve vysokém rozlišení a bohatých grafů. Zjistili jste, že pomocí PromQL můžete určovat a odstraňovat problémy s našimi řídicími panely SCUMM, které vám umožňují agregovat data časových řad v reálném čase. Můžete také generovat grafy nebo prohlížet pomocí konzole všechny shromážděné metriky.
Také jste se naučili, jak ladit naše řídicí panely SCUMM, zvláště když nejsou shromažďovány žádné datové body.
Máte-li dotazy, přidejte je do komentářů nebo nám dejte vědět prostřednictvím našich komunitních fór.