Možná jste slyšeli o termínu „failover“ v souvislosti s replikací MySQL. Možná vás napadlo, co to je, když začínáte své dobrodružství s databázemi. Možná víte, co to je, ale nejste si jisti potenciálními problémy s tím souvisejícími a jak je lze vyřešit?
V tomto příspěvku na blogu se vám pokusíme poskytnout úvod do zpracování převzetí služeb při selhání v MySQL a MariaDB.
Probereme, co je to failover, proč je nevyhnutelné, jaký je rozdíl mezi failover a switchover. Budeme diskutovat o procesu převzetí služeb při selhání v nejobecnější podobě. Také se trochu dotkneme různých problémů, které budete muset řešit v souvislosti s procesem převzetí služeb při selhání.
Co znamená „přepnutí při selhání“?
Replikace MySQL je soubor uzlů, z nichž každý může současně sloužit jedné roli. Může se stát mistrem nebo replikou. V daný čas existuje pouze jeden hlavní uzel. Tento uzel přijímá provoz zápisu a replikuje zápisy do svých replik.
Jak si dokážete představit, hlavní uzel je velmi důležitý, protože je jediným vstupním bodem pro data do replikačního clusteru. Co by se stalo, kdyby selhal a stal se nedostupným?
To je docela vážný stav pro replikační cluster. V daném okamžiku nemůže přijímat žádné zápisy. Jak můžete očekávat, jedna z replik bude muset převzít úkoly mistra a začít přijímat zápisy. Zbytek replikační topologie se může také změnit – zbývající repliky by měly změnit svůj hlavní uzel ze starého neúspěšného uzlu na nově vybraný. Tento proces „povýšení“ repliky, aby se stala předlohou poté, co stará předloha selhala, se nazývá „přepnutí při selhání“.
Na druhou stranu k „přepnutí“ dojde, když uživatel spustí propagaci repliky. Nová předloha je povýšena z repliky, na kterou poukázal uživatel, a stará předloha se obvykle stává replikou nové předlohy.
Nejdůležitější rozdíl mezi „failover“ a „přepnutím“ je stav starého masteru. Když je provedeno převzetí služeb při selhání, starý hlavní server je nějakým způsobem nedostupný. Možná došlo k havárii, možná došlo k rozdělení sítě. V danou chvíli jej nelze použít a jeho stav je obvykle neznámý.
Na druhou stranu, když dojde k přepnutí, starý mistr žije a má se dobře. To má vážné důsledky. Pokud je master nedostupný, může to znamenat, že některá data ještě nebyla odeslána podřízeným zařízením (pokud nebyla použita semisynchronní replikace). Některá data mohla být poškozena nebo odeslána částečně.
Existují mechanismy, které zabraňují šíření takového poškození na otrokech, ale jde o to, že některá data mohou být během procesu ztracena. Na druhou stranu, při provádění přepínání je k dispozici starý master a je zachována konzistence dat.
Proces převzetí služeb při selhání
Pojďme strávit nějaký čas diskusí o tom, jak přesně vypadá proces převzetí služeb při selhání.
Bylo zjištěno hlavní selhání
Pro začátečníky musí master havarovat, než bude provedeno převzetí služeb při selhání. Jakmile není k dispozici, spustí se převzetí služeb při selhání. Zatím to vypadá jednoduše, ale pravdou je, že už jsme na kluzké půdě.
Za prvé, jak se testuje zdraví mistra? Testuje se z jednoho místa nebo jsou testy distribuovány? Pokouší se software pro správu převzetí služeb při selhání pouze připojit k hlavnímu serveru, nebo implementuje pokročilejší ověření před vyhlášením selhání hlavního serveru?
Představme si následující topologii:
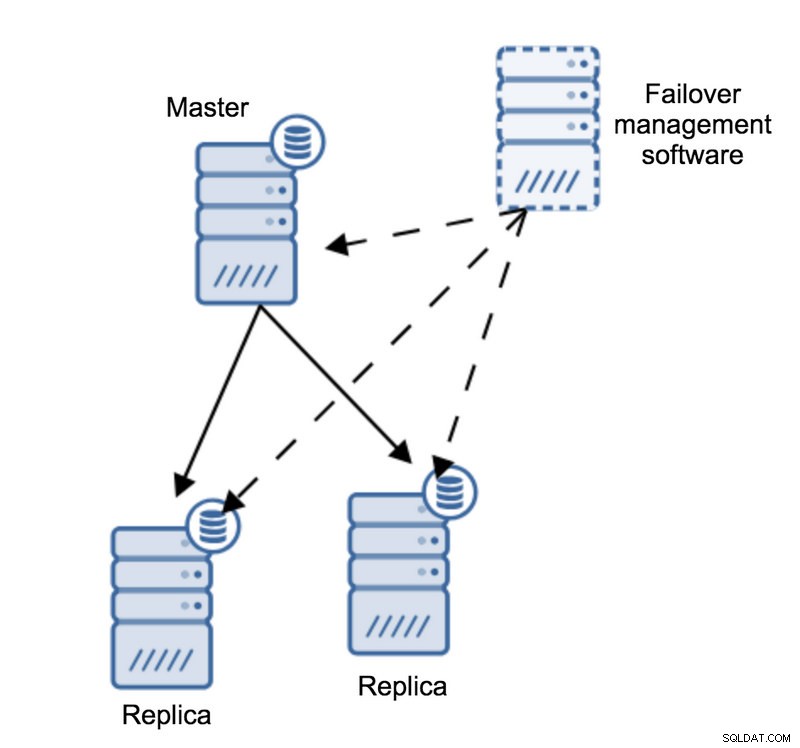
Máme předlohu a dvě repliky. Máme také software pro správu převzetí služeb při selhání umístěný na nějakém externím hostiteli. Co by se stalo, kdyby selhalo síťové připojení mezi hostitelem se softwarem pro přepnutí při selhání a hlavním serverem?
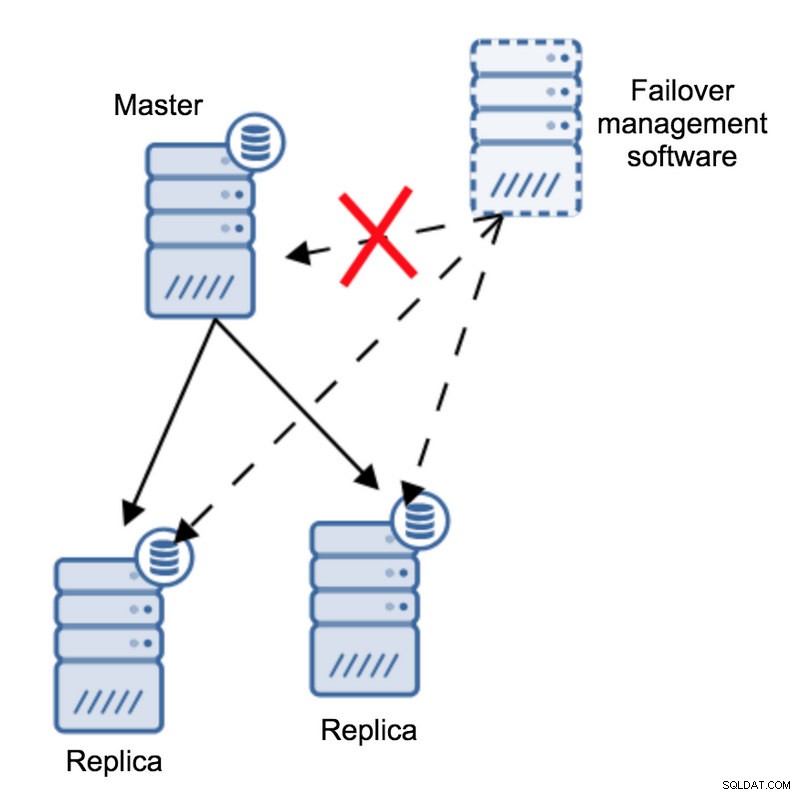
Podle softwaru pro správu převzetí služeb při selhání se hlavní server zhroutil – není k němu žádné připojení. Přesto samotná replikace funguje dobře. Zde by se mělo stát, že se software pro správu převzetí služeb při selhání pokusí připojit k replikám a uvidí, jaký je jejich úhel pohledu.
Stěžují si na nefunkční replikaci nebo se šťastně replikují?
Věci mohou být ještě složitější. Co kdybychom přidali proxy (nebo sadu proxy)? Bude se používat ke směrování provozu – zapisuje do masteru a čte do replik. Co když proxy nemá přístup k masteru? Co když žádný z proxy nemá přístup k hlavnímu serveru?
To znamená, že aplikace za těchto podmínek nemůže fungovat. Mělo by se spustit převzetí služeb při selhání (ve skutečnosti by šlo spíše o přepnutí, protože master je technicky naživu)?
Technicky je master naživu, ale nemůže být použit aplikací. Zde musí vstoupit obchodní logika a musí být učiněno rozhodnutí.
Zabránění spuštění Old Master
Bez ohledu na to, jak a proč, pokud dojde k rozhodnutí povýšit jednu z replik, aby se stala novou předlohou, starou předlohu je třeba zastavit a v ideálním případě by nemělo být možné znovu začít.
Jak toho lze dosáhnout, závisí na detailech konkrétního prostředí; proto je tato část procesu převzetí služeb při selhání obvykle posílena externími skripty integrovanými do procesu převzetí služeb při selhání prostřednictvím různých háčků.
Tyto skripty mohou být navrženy tak, aby využívaly nástroje dostupné v konkrétním prostředí k zastavení staré předlohy. Může to být volání CLI nebo API, které zastaví virtuální počítač; může to být kód shellu, který spouští příkazy prostřednictvím nějakého zařízení pro „správu zhasnutí světla“; může to být skript, který posílá SNMP trapy do Power Distribution Unit, které deaktivují elektrické zásuvky, které starý master používá (bez elektrické energie si můžeme být jisti, že se znovu nespustí).
Pokud je software pro správu převzetí služeb při selhání součástí složitějšího produktu, který také zpracovává obnovu uzlů (jako je tomu v případě ClusterControl), může být starý hlavní server označen jako vyloučený z rutin obnovy.
Možná se divíte, proč je tak důležité zabránit tomu, aby byl starý mistr znovu dostupný?
Hlavním problémem je, že v nastaveních replikace lze pro zápisy použít pouze jeden uzel. Obvykle to zajistíte povolením proměnné read_only (a super_read_only, pokud je to možné) u všech replik a ponecháním této proměnné deaktivované pouze na hlavní.
Jakmile bude nový hlavní server povýšen, bude mít zakázáno pouze pro čtení. Problém je v tom, že pokud starý master není dostupný, nemůžeme ho přepnout zpět na read_only=1. Pokud dojde k havárii MySQL nebo hostitele, není to příliš velký problém, protože osvědčeným postupem je mít my.cnf nakonfigurováno s tímto nastavením, takže jakmile se MySQL spustí, vždy se spustí v režimu pouze pro čtení.
Problém se ukáže, když nejde o selhání, ale o problém se sítí. Starý master stále běží s zakázaným read_only, prostě není k dispozici. Když se sítě sblíží, skončíte se dvěma zapisovatelnými uzly. To může a nemusí být problém. Některé z proxy používají nastavení read_only jako indikátor toho, zda je uzel hlavní nebo replika. Dva hlavní servery, které se objeví v danou chvíli, mohou způsobit velký problém, protože data jsou zapisována na oba hostitele, ale repliky získávají pouze polovinu provozu zápisu (část, která zasáhla nový master).
Někdy jde o pevně zakódovaná nastavení v některých skriptech, které jsou nakonfigurovány pro připojení pouze k danému hostiteli. Normálně by selhaly a někdo by si všiml, že se mistr změnil.
S dostupným starým masterem se k němu vesele připojí a vznikne nesoulad dat. Jak vidíte, zajištění toho, že se starý master nespustí, je poměrně vysoká priorita.
Rozhodněte se pro hlavního kandidáta
Starý mistr je na dně a nevrátí se z hrobu, nyní je čas rozhodnout, kterého hostitele bychom měli použít jako nového mistra. Obvykle je na výběr více než jedna replika, takže je třeba učinit rozhodnutí. Existuje mnoho důvodů, proč může být jedna replika vybrána před druhou, a proto je třeba provádět kontroly.
Bílé a černé listiny
Pro začátek může mít tým spravující databáze své důvody, aby při rozhodování o hlavním kandidátovi upřednostnil jednu repliku před druhou. Možná používá slabší hardware nebo má přiřazenou nějakou konkrétní úlohu (tato replika spouští zálohování, analytické dotazy, vývojáři k ní mají přístup a spouštějí vlastní, ručně vyrobené dotazy). Možná je to testovací replika, kde nová verze prochází akceptačními testy před pokračováním v upgradu. Většina softwaru pro správu převzetí služeb při selhání podporuje bílé a černé listiny, které lze využít k přesnému definování, které repliky by měly nebo neměly být použity jako hlavní kandidáti.
Semisynchronní replikace
Nastavení replikace může být kombinací asynchronních a semisynchronních replik. Je mezi nimi obrovský rozdíl – semisynchronní replika zaručeně obsahuje všechny události z masteru. Asynchronní replika možná neobdržela všechna data, takže její selhání může vést ke ztrátě dat. Raději bychom viděli podporu semisynchronních replik.
Prodleva replikace
Přestože semisynchronní replika bude obsahovat všechny události, tyto události mohou být stále umístěny pouze v protokolech přenosu. Při silném provozu se mohou všechny repliky, bez ohledu na to, zda jsou polosynchronizované nebo asynchronní, zpožďovat.
Problém se zpožděním replikace spočívá v tom, že když povýšíte repliku, měli byste resetovat nastavení replikace, aby se nepokusila připojit ke starému předlohu. Tím se také odstraní všechny protokoly přenosu, i když ještě nebyly použity – což vede ke ztrátě dat.
I když neresetujete nastavení replikace, stále nemůžete otevřít nový hlavní server pro připojení, pokud neaplikoval všechny události ze svého protokolu přenosu. Jinak riskujete, že nové dotazy ovlivní transakce z předávacího protokolu a způsobí nejrůznější problémy (např. aplikace může odstranit některé řádky, ke kterým přistupují transakce z předávacího protokolu).
Vezmeme-li toto vše v úvahu, jedinou bezpečnou možností je počkat na aplikaci protokolu přenosu. Přesto to může chvíli trvat, pokud replika silně zaostává. Je třeba rozhodnout, která replika by byla lepší master – asynchronní, ale s malým zpožděním nebo semisynchronní, ale se zpožděním, které by vyžadovalo značné množství času, než se použije.
Chybné transakce
I když by se do replik nemělo zapisovat, stále se může stát, že do nich někdo (nebo něco) napsal.
V minulosti to mohl být jen způsob jedné transakce, ale stále to může mít vážný dopad na schopnost provést převzetí služeb při selhání. Tento problém úzce souvisí s Global Transaction ID (GTID), což je funkce, která přiřazuje odlišné ID každé transakci provedené na daném MySQL uzlu.
V současné době je to docela populární nastavení, protože přináší vysokou úroveň flexibility a umožňuje lepší výkon (s vícevláknovými replikami).
Problém je v tom, že při přeřazení na nový hlavní server vyžaduje replikace GTID všechny události z tohoto hlavního serveru (které nebyly provedeny na replice) replikovány do repliky.
Uvažujme následující scénář:v určitém okamžiku v minulosti došlo k zápisu na repliku. Bylo to už dávno a tato událost byla vymazána z binárních protokolů repliky. V určitém okamžiku předloha selhala a replika byla jmenována novou předlohou. Všechny zbývající repliky budou podřízeny nové předloze. Budou se ptát na transakce provedené na novém masteru. Odpoví seznamem GTID pocházejících ze starého hlavního serveru a jediným GTID souvisejícím s tímto starým zápisem. GTID ze starého hlavního serveru nepředstavují problém, protože všechny zbývající repliky obsahují alespoň většinu z nich (pokud ne všechny) a všechny chybějící události by měly být dostatečně aktuální, aby byly dostupné v binárních protokolech nového hlavního serveru.
V nejhorším případě budou některé chybějící události načteny z binárních protokolů a přeneseny do replik. Problém je s tím starým zápisem - stalo se to pouze na novém masteru, zatímco to bylo ještě replika, takže na zbývajících hostitelích neexistuje. Je to stará událost, takže neexistuje způsob, jak ji získat z binárních protokolů. V důsledku toho žádná z replik nebude moci otročit nového mistra. Jediným řešením je provést ruční akci a vložit prázdnou událost s tímto problematickým GTID do všech replik. Bude to také znamenat, že v závislosti na tom, co se stalo, repliky nemusí být synchronizované s novou předlohou.
Jak vidíte, je docela důležité sledovat chybné transakce a určit, zda je bezpečné povýšit danou repliku na novou předlohu. Pokud obsahuje chybné transakce, nemusí to být nejlepší volba.
Ovládání převzetí služeb při selhání pro aplikaci
Je důležité mít na paměti, že hlavní přepínač, vynucený nebo ne, má vliv na celou topologii. Zápisy musí být přesměrovány do nového uzlu. To lze provést několika způsoby a je důležité zajistit, aby tato změna byla pro aplikaci co nejtransparentnější. V této části se podíváme na některé příklady toho, jak může být převzetí služeb při selhání pro aplikaci transparentní.
DNS
Jedním ze způsobů, jak lze aplikaci nasměrovat na master, je využití záznamů DNS. S nízkým TTL je možné změnit IP adresu, na kterou odkazuje záznam DNS, jako je „master.dc1.example.com“. Takovou změnu lze provést pomocí externích skriptů spouštěných během procesu převzetí služeb při selhání.
Zjištění služby
Nástroje jako Consul nebo etc.d lze také použít pro nasměrování provozu na správné místo. Takové nástroje mohou obsahovat informaci, že IP aktuálního mastera je nastavena na nějakou hodnotu. Některé z nich také umožňují používat vyhledávání názvu hostitele k ukázání správné IP adresy. Opět platí, že položky v nástrojích pro zjišťování služeb je třeba udržovat a jedním ze způsobů, jak toho dosáhnout, je provést tyto změny během procesu převzetí služeb při selhání pomocí háčků spouštěných v různých fázích převzetí služeb při selhání.
Proxy
Proxy mohou být také použity jako zdroj pravdy o topologii. Obecně řečeno, bez ohledu na to, jak zjistí topologii (může to být buď automatický proces nebo musí být proxy překonfigurován, když se topologie změní), měly by obsahovat aktuální stav replikačního řetězce, protože jinak by nebyli schopni správně směrovat dotazy.
Přístup k použití proxy jako zdroje pravdy může být docela běžný ve spojení s přístupem k umístění proxy na hostitele aplikace. Kolokace proxy a webových serverů má řadu výhod:rychlá a bezpečná komunikace pomocí Unixového soketu, udržování cachovací vrstvy (protože některé proxy, jako je ProxySQL také umí cachování) v blízkosti aplikace. V takovém případě má smysl, aby se aplikace pouze připojila k proxy a předpokládala, že bude směrovat dotazy správně.
Failover v ClusterControl
ClusterControl používá osvědčené postupy v oboru, aby se ujistil, že proces převzetí služeb při selhání je proveden správně. Zajišťuje také, že proces bude bezpečný – výchozí nastavení je určeno k přerušení převzetí služeb při selhání, pokud jsou zjištěny možné problémy. Tato nastavení může uživatel přepsat, pokud chce upřednostnit převzetí služeb při selhání před bezpečností dat.
Jakmile ClusterControl detekuje selhání hlavního serveru, zahájí se proces převzetí služeb při selhání a okamžitě se spustí první připojení při selhání:

Dále je testována hlavní dostupnost.

ClusterControl provádí rozsáhlé testy, aby se ujistil, že master je skutečně nedostupný. Toto chování je ve výchozím nastavení povoleno a je spravováno následující proměnnou:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.V následujícím kroku ClusterControl zajistí, že starý master je mimo provoz, a pokud ne, ClusterControl se ho nepokusí obnovit:

Dalším krokem je určit, který hostitel může být použit jako hlavní kandidát. ClusterControl kontroluje, zda je definován whitelist nebo blacklist.
Můžete to udělat pomocí následujících proměnných v konfiguračním souboru cmon:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Je také možné nakonfigurovat ClusterControl tak, aby hledal rozdíly ve filtrech binárních protokolů ve všech replikách. To lze provést pomocí proměnné replikace_check_binlog_filtration_bf_failover. Ve výchozím nastavení jsou tyto kontroly zakázány. ClusterControl také ověřuje, že neexistují žádné chybné transakce, které by mohly způsobit problémy.

Můžete také požádat ClusterControl, aby automaticky znovu sestavil repliky, které se nemohou replikovat z nového hlavního serveru pomocí následujícího nastavení v konfiguračním souboru cmon:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Poté se provede druhý skript:je definován v nastavení skriptu replikace_pre_failover_script. Dále kandidát prochází přípravným procesem.


ClusterControl čeká na použití redo logs (zajištění minimální ztráty dat). Také kontroluje, zda jsou na zbývajících replikách k dispozici další transakce, které nebyly aplikovány na hlavního kandidáta. Obě chování může uživatel ovládat pomocí následujících nastavení v konfiguračním souboru cmon:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Jak vidíte, můžete vynutit převzetí služeb při selhání, i když nebyly použity všechny události redo logu – umožňuje uživateli rozhodnout, co má vyšší prioritu – konzistenci dat nebo rychlost převzetí služeb při selhání.


Nakonec je zvolen hlavní a provede se poslední skript (skript, který lze definovat jako replikační_post_failover_script.
Pokud jste ClusterControl ještě nevyzkoušeli, doporučuji vám jej stáhnout (je zdarma) a vyzkoušet.
Hlavní detekce v ClusterControl
ClusterControl vám dává možnost nasadit plnou sadu High Availability včetně databázových a proxy vrstev. Hlavní objev je vždy jedním z problémů, které je třeba řešit.
Jak to funguje v ClusterControl?
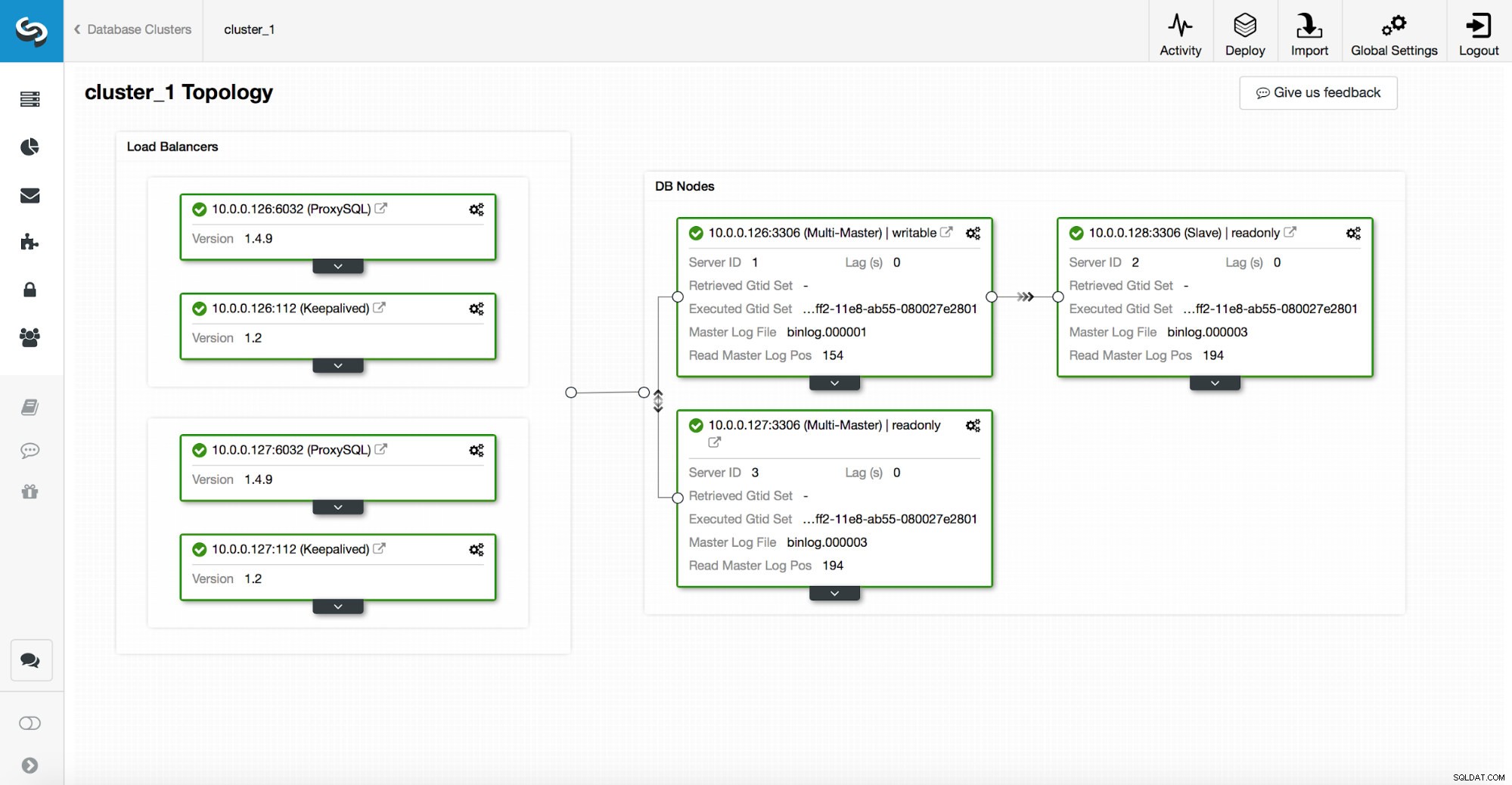
Zásobník vysoké dostupnosti nasazený prostřednictvím ClusterControl se skládá ze tří částí:
- databázová vrstva
- vrstva proxy, kterou může být HAProxy nebo ProxySQL
- keepalived vrstva, která s využitím virtuální IP zajišťuje vysokou dostupnost proxy vrstvy
Proxy se spoléhají na proměnné pouze pro čtení na uzlech.
Jak můžete vidět na obrázku výše, pouze jeden uzel v topologii je označen jako „zapisovatelný“. Toto je hlavní uzel a toto je jediný uzel, který bude přijímat zápisy.
Proxy (v tomto příkladu ProxySQL) bude tuto proměnnou sledovat a automaticky se překonfiguruje.
Na druhé straně této rovnice se ClusterControl stará o změny topologie:přepnutí při selhání a přepnutí. Provede nezbytné změny v hodnotě read_only, aby odrážely stav topologie po změně. Pokud je povýšen nový master, stane se jediným zapisovatelným uzlem. Pokud je po převzetí služeb při selhání zvolen hlavní server, bude mít zakázáno pouze čtení.
Nad vrstvou proxy je nasazena funkce keepalived. Nasazuje VIP a monitoruje stav podkladových proxy uzlů. VIP body na jeden proxy uzel v daný čas. Pokud tento uzel selže, virtuální IP je přesměrována na jiný uzel, což zajistí, že provoz směřovaný do VIP dosáhne zdravého proxy uzlu.
Abych to shrnul, aplikace se připojuje k databázi pomocí virtuální IP adresy. Tato IP ukazuje na jeden z proxy. Proxy přesměrovávají provoz podle topologické struktury. Informace o topologii jsou odvozeny ze stavu pouze pro čtení. Tuto proměnnou spravuje ClusterControl a nastavuje se na základě změn topologie požadovaných uživatelem nebo automaticky prováděných ClusterControl.