Všichni jste slyšeli o škálování – vaše architektura by měla být škálovatelná, měli byste být schopni škálovat, abyste uspokojili poptávku, a tak dále. Co to znamená, když mluvíme o databázích? Jak vypadá škálování v zákulisí? Toto téma je rozsáhlé a neexistuje způsob, jak pokrýt všechny aspekty. Tato série příspěvků o dvou blozích je pokusem poskytnout vám vhled do tématu škálovatelnosti databáze.
Proč provádíme škálování?
Nejprve se podívejme na to, co je škálovatelnost. Stručně řečeno, mluvíme o schopnosti zvládnout vyšší zátěž vašich databázových systémů. Může jít o vypořádání se s krátkodobými výkyvy v činnosti, může se jednat o řešení postupně se zvyšující zátěže ve vašem databázovém prostředí. Důvodů, proč zvážit škálování, může být celá řada. Většina z nich přichází s vlastními výzvami. Můžeme strávit nějaký čas procházením příkladů situace, kdy bychom mohli chtít škálovat.
Nárůst spotřeby zdrojů
Toto je nejobecnější – vaše zatížení se zvýšilo do bodu, kdy vaše stávající zdroje již nejsou schopny se s ním vypořádat. Může to být cokoliv. Zatížení CPU se zvýšilo a váš databázový cluster již není schopen dodávat data s přiměřenou a stabilní dobou provádění dotazu. Využití paměti vzrostlo do té míry, že databáze již není vázána na CPU, ale stala se I/O vázána, a jako takový se výkon databázových uzlů výrazně snížil. Síť může být také podvodná. Možná vás překvapí, jaká omezení související se sítí mají vaše cloudové instance přiřazeny. Ve skutečnosti se to může stát nejběžnějším limitem, se kterým se musíte vypořádat, protože síť je všechno v cloudu – nejen data odesílaná mezi aplikací a databází, ale také úložiště je připojeno přes síť. Může to být i vytížením disku - právě vám dochází místo na disku nebo pravděpodobněji, vzhledem k tomu, že v dnešní době můžeme mít poměrně velké disky, velikost databáze přerostla nad „spravovatelnou“ velikost. Údržba, jako je změna schématu, se stává výzvou, výkon se snižuje kvůli velikosti dat, dokončení zálohování trvá věky. Všechny tyto případy mohou být pádným důvodem pro potřebu rozšíření.
Náhlé zvýšení pracovní zátěže
Dalším příkladem, kdy je vyžadováno škálování, je náhlé zvýšení pracovní zátěže. Z nějakého důvodu (ať už jde o marketingové úsilí, virový obsah, nouzovou situaci nebo podobnou situaci) vaše infrastruktura zažívá výrazné zvýšení zatížení databázového clusteru. Zatížení CPU převyšuje střechu, diskový I/O zpomaluje dotazy atd. Téměř každý zdroj, který jsme zmínili v předchozí části, může být přetížen a může začít způsobovat problémy.
Plánovaná operace
Třetím důvodem, který bychom rádi zdůraznili, je ten obecnější – nějaký druh plánované operace. Může to být plánovaná marketingová aktivita, od které očekáváte větší návštěvnost, Black Friday, zátěžové testování nebo v podstatě cokoli, co víte předem.
Každý z těchto důvodů má své vlastní charakteristiky. Pokud můžete plánovat předem, můžete si proces detailně připravit, otestovat a spustit, kdykoli budete chtít. S největší pravděpodobností to budete chtít dělat v období „nízkého provozu“, pokud něco takového existuje ve vaší pracovní zátěži (nemusí existovat). Na druhou stranu náhlé skoky v zátěži, zvláště pokud jsou dostatečně významné na to, aby ovlivnily produkci, si vynutí okamžitou reakci, bez ohledu na to, jak jste připraveni a jak je to bezpečné – pokud jsou vaše služby již ovlivněny, můžete jděte do toho místo čekání.
Typy škálování databáze
Existují dva hlavní typy změny měřítka:vertikální a horizontální. Oba mají klady a zápory, oba jsou užitečné v různých situacích. Pojďme se na ně podívat a probrat případy použití pro oba scénáře.
Vertikální měřítko
Tato metoda škálování je pravděpodobně nejstarší:pokud váš hardware není dostatečně výkonný, aby se vypořádal s pracovní zátěží, zvyšte ji. Hovoříme zde jednoduše o přidávání zdrojů ke stávajícím uzlům se záměrem, aby byly dostatečně schopné zvládnout dané úkoly. To má některé důsledky, které bychom rádi probrali.
Výhody vertikálního škálování
Nejdůležitější je, aby vše zůstalo při starém. Měli jste tři uzly v databázovém clusteru, stále máte tři uzly, jen schopnější. Není třeba předělávat prostředí, měnit způsob, jakým má aplikace přistupovat k databázi – vše zůstává přesně stejné, protože z hlediska konfigurace se vlastně nic nezměnilo.
Další významnou výhodou vertikálního škálování je, že může být velmi rychlé, zejména v cloudových prostředích. Celý proces je v podstatě zastavit existující uzel, provést změnu v hardwaru a znovu spustit uzel. U klasických, on-prem nastavení bez jakékoli virtualizace to může být složité – nemusíte mít k dispozici rychlejší CPU k výměně, upgrade disků na větší nebo rychlejší může být také časově náročný, ale pro cloudová prostředí, ať už veřejná nebo soukromá, to může být stejně snadné jako spuštění tří příkazů:zastavení instance, upgrade instance na větší velikost, spuštění instance. Virtuální IP a znovu připojitelné svazky usnadňují přesun dat mezi instancemi.
Nevýhody vertikálního škálování
Hlavní nevýhodou vertikálního škálování je to, že prostě má své limity. Pokud používáte největší dostupnou velikost instance s nejrychlejšími objemy disku, nic jiného nemůžete dělat. Také není tak snadné výrazně zvýšit výkon vašeho databázového clusteru. Většinou to závisí na velikosti počáteční instance, ale pokud již provozujete poměrně výkonné uzly, možná nebudete schopni dosáhnout 10x škálování pomocí vertikálního škálování. Uzly, které by byly 10x rychlejší, jednoduše nemusí existovat.
Horizontální měřítko
Horizontální škálování je jiné zvíře. Namísto zvyšování velikosti instance zůstáváme na stejné úrovni, ale rozšiřujeme se horizontálně přidáním dalších uzlů. Opět existují výhody a nevýhody této metody.
Výhody horizontálního škálování
Hlavní výhodou horizontálního škálování je, že teoreticky je limitem nebe. Neexistuje žádný umělý pevný limit škálování, i když limity existují, hlavně kvůli komunikaci v rámci klastru, která je stále větší a větší s každým novým uzlem přidaným do klastru.
Další významnou výhodou by bylo, že můžete škálovat cluster bez nutnosti prostojů. Pokud chcete upgradovat hardware, musíte zastavit instanci, upgradovat ji a pak začít znovu. Chcete-li do clusteru přidat další uzly, vše, co musíte udělat, je zajistit tyto uzly, nainstalovat jakýkoli software, který potřebujete, včetně databáze, a nechat jej připojit se ke clusteru. Volitelně (v závislosti na tom, zda má klastr interní metody pro poskytování dat novým uzlům), možná mu budete muset poskytnout data sami. Obvykle se však jedná o automatizovaný proces.
Nevýhody horizontálního škálování
Hlavním problémem, se kterým se musíte vypořádat, je to, že přidávání dalších a dalších uzlů ztěžuje správu celého prostředí. Musíte být schopni říct, které uzly jsou k dispozici, takový seznam musí být udržován a aktualizován s každým novým vytvořeným uzlem. Možná budete potřebovat externí řešení, jako je adresářová služba (Consul nebo Etcd), abyste mohli sledovat uzly a jejich stav. To samozřejmě zvyšuje složitost celého prostředí.
Dalším potenciálním problémem je, že proces škálování trvá dlouho. Přidávání nových uzlů a jejich poskytování softwarem a zejména daty vyžaduje čas. Jak moc, to záleží na hardwaru (hlavně I/O a propustnost sítě) a velikosti dat. U velkých nastavení to může být značné množství času a to může být překážkou v situacích, kdy musí ke zvětšení dojít okamžitě. Hodiny čekání na přidání nových uzlů nemusí být přijatelné, pokud je databázový cluster ovlivněn do té míry, že operace nejsou prováděny správně.
Předpoklady pro změnu měřítka
Replikace dat
Než bude možné provést jakýkoli pokus o škálování, musí vaše prostředí splňovat několik požadavků. Pro začátek musí být vaše aplikace schopna využívat více než jeden uzel. Pokud může používat pouze jeden uzel, jsou vaše možnosti do značné míry omezeny na vertikální škálování. Můžete zvětšit velikost takového uzlu nebo přidat nějaké hardwarové prostředky k holému kovovému serveru a zvýšit jeho výkon, ale to je to nejlepší, co můžete udělat:vždy budete omezeni dostupností výkonnějšího hardwaru a nakonec zjistíte, sami bez možnosti dalšího rozšiřování.
Na druhou stranu, pokud máte prostředky k využití více databázových uzlů vaší aplikací, můžete těžit z horizontálního škálování. Zastavme se zde a proberme, co je to, co potřebujete, abyste skutečně využili více uzlů k jejich plnému potenciálu.
Pro začátečníky možnost oddělit čtení od zápisu. Tradičně se aplikace připojuje pouze k jednomu uzlu. Tento uzel se používá ke zpracování všech zápisů a všech čtení prováděných aplikací.

Přidání druhého uzlu do clusteru z hlediska škálování nic nemění . Musíte mít na paměti, že pokud jeden uzel selže, druhý bude muset provoz zvládnout, takže v žádném okamžiku by součet zatížení v obou uzlech neměl být příliš vysoký, aby se s ním vypořádal jeden uzel.

Se třemi dostupnými uzly můžete plně využít dva uzly. To nám umožňuje škálovat část čteného provozu:pokud má jeden uzel kapacitu 100 % (a raději bychom běželi maximálně na 70 %), pak dva uzly představují 200 %. Tři uzly:300 %. Pokud je jeden uzel mimo provoz a pokud budeme tlačit zbývající uzly téměř na limit, můžeme říci, že jsme schopni pracovat se 170 - 180 % kapacity jednoho uzlu, pokud je cluster degradován. To nám dává pěkné 60% zatížení každého uzlu, pokud jsou dostupné všechny tři uzly.
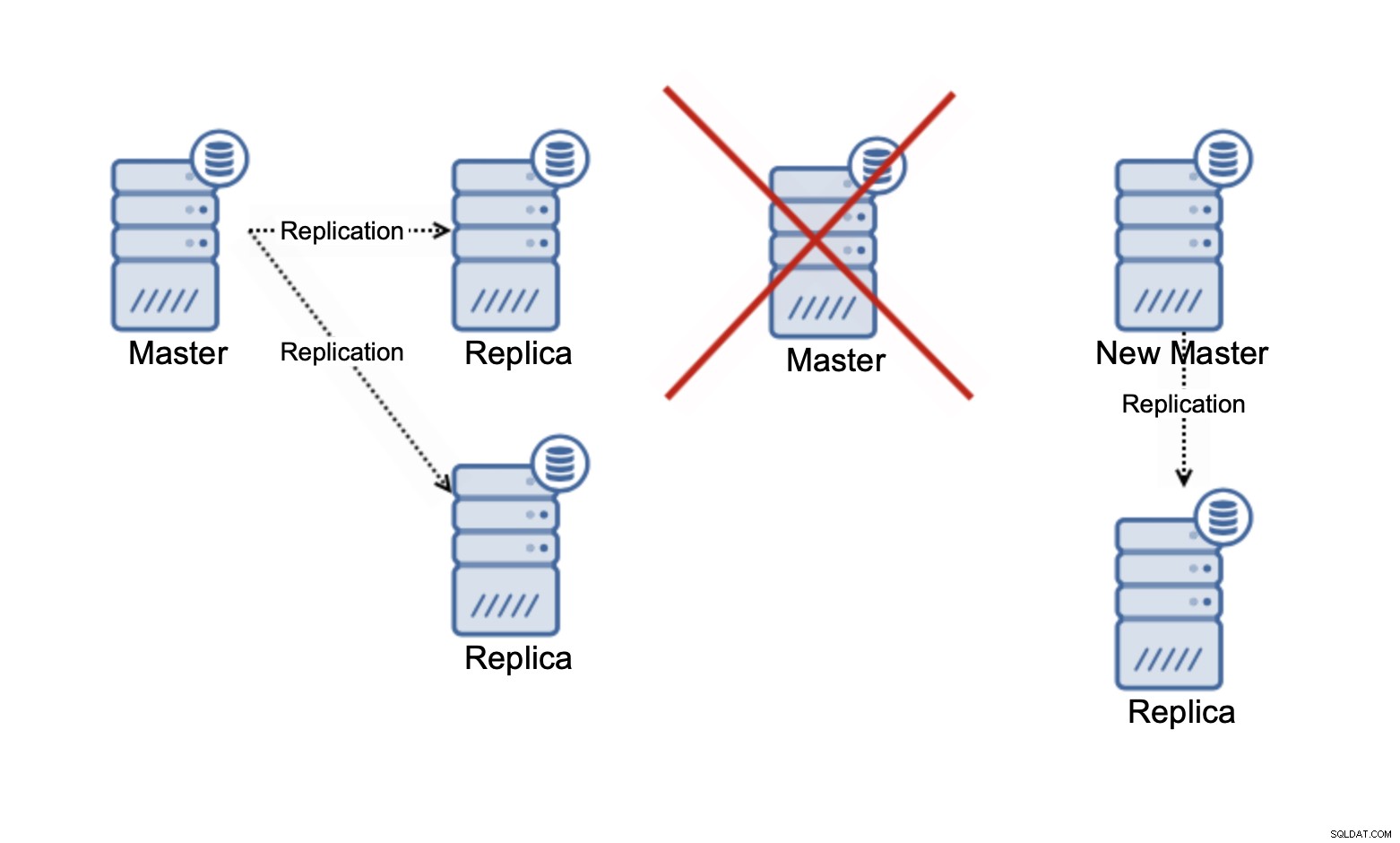
Mějte prosím na paměti, že v tuto chvíli mluvíme pouze o škálování čtení . Replikace nemůže v žádném okamžiku zlepšit vaši kapacitu zápisu. V asynchronní replikaci máte pouze jeden zapisovač (master) a pro synchronní replikaci, jako je Galera, kde je datová sada sdílena napříč všemi uzly, bude muset být každý zápis, ke kterému dochází na jednom uzlu, proveden na zbývajících uzlech shluk.
Pokud v clusteru Galera se třemi uzly napíšete jeden řádek, ve skutečnosti zapíšete tři řádky, jeden pro každý uzel. Přidání dalších uzlů nebo replik nebude mít žádný vliv. Namísto psaní stejného řádku na tři uzly jej napíšete na pět. To je důvod, proč rozdělení vašich zápisů do multi-master clusteru, kde je datová sada sdílena napříč všemi uzly (existují multi-master clustery, kde jsou data shardována, například MySQL NDB Cluster – zde je příběh škálovatelnosti zápisu úplně jiný), nedává příliš smysl. Přidává režii na řešení potenciálních konfliktů zápisu napříč všemi uzly, přičemž ve skutečnosti nemění nic, co se týče celkové kapacity zápisu.
Rozdělení zátěže a čtení/zápis
Možnost oddělit čtení od zápisů je nutností, pokud chcete škálovat svá čtení v nastaveních asynchronní replikace. Musíte být schopni posílat zápisový provoz do jednoho uzlu a poté odeslat čtení všem uzlům v topologii replikace. Jak jsme zmínili dříve, tato funkce je také docela užitečná v clusterech s více mastery, protože nám umožňuje odstranit konflikty zápisu, ke kterým může dojít, pokud se pokusíte distribuovat zápisy mezi více uzlů v clusteru. Jak můžeme provést rozdělení čtení/zápisu? K tomu můžete použít několik metod. Pojďme se trochu ponořit do tohoto tématu.
Rozdělení R/W na úrovni aplikace
Nejjednodušší scénář, také nejméně častý:vaše aplikace může být konfigurována, které uzly by měly přijímat zápisy a které uzly by měly přijímat čtení. Tuto funkci lze konfigurovat několika způsoby, z nichž nejjednodušší je pevně zakódovaný seznam uzlů, ale také to může být něco v duchu dynamického inventáře uzlů aktualizovaného vlákny na pozadí. Hlavním problémem tohoto přístupu je, že celá logika musí být napsána jako součást aplikace. S pevně zakódovaným seznamem uzlů by nejjednodušší scénář vyžadoval změny kódu aplikace pro každou změnu v topologii replikace. Na druhou stranu, pokročilejší řešení, jako je implementace zjišťování služeb, by bylo z dlouhodobého hlediska složitější.
R/W dělený konektor
Další možností by bylo použití konektoru k provedení rozdělení čtení/zápisu. Ne všichni mají tuto možnost, ale někteří ano. Příkladem může být php-mysqlnd nebo Connector/J. Způsob integrace do aplikace se může lišit v závislosti na samotném konektoru. V některých případech musí být konfigurace provedena v aplikaci, v některých případech musí být provedena v samostatném konfiguračním souboru pro konektor. Výhodou tohoto přístupu je, že i když musíte aplikaci rozšířit, většina nového kódu je připravena k použití a spravována externími zdroji. Usnadňuje to takové nastavení a musíte psát méně kódu (pokud existuje).
Rozdělení R/W v loadbalanceru
Konečně jedno z nejlepších řešení:loadbalancery. Myšlenka je jednoduchá – předejte svá data přes loadbalancer, který bude schopen rozlišovat mezi čtením a zápisem a odeslat je na správné místo. To je velké zlepšení z hlediska použitelnosti, protože můžeme oddělit zjišťování databáze a směrování dotazů od aplikace. Jediná věc, kterou musí aplikace udělat, je odeslat databázový provoz do jednoho koncového bodu, který se skládá z názvu hostitele a portu. Zbytek se děje na pozadí. Loadbalancers pracují na směrování dotazů do uzlů backendové databáze. Loadbalancery mohou také provádět zjišťování topologie replikace nebo můžete implementovat řádný inventář služeb pomocí etcd nebo consul a aktualizovat jej pomocí nástrojů pro orchestraci infrastruktury, jako je Ansible.
Tímto končí první část tohoto blogu. Ve druhém budeme diskutovat o výzvách, kterým čelíme při škálování databázové vrstvy. Probereme také některé způsoby, jak můžeme škálovat naše databázové clustery.