Při práci se jmény osob a při jejich fuzzy vyhledávání se mi osvědčilo vytvořit druhou tabulku slov. Vytvořte také třetí tabulku, která je průsečíkovou tabulkou pro vztah mnoho k mnoha mezi tabulkou obsahující text a tabulkou slov. Když do textové tabulky přidáte řádek, rozdělíte text na slova a vhodně vyplníte průsečíkovou tabulku a v případě potřeby přidáte nová slova do tabulky slov. Jakmile je tato struktura na svém místě, můžete provádět vyhledávání o něco rychleji, protože svou funkci damlev musíte provést pouze nad tabulkou jedinečných slov. Jednoduchým spojením získáte text obsahující odpovídající slova. 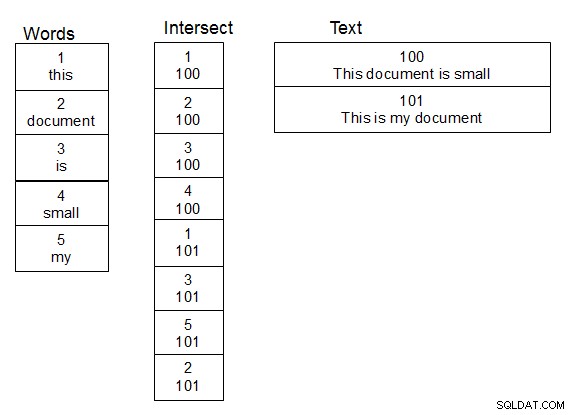
Dotaz na shodu jednoho slova by vypadal asi takto:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
a dvě slova by vypadala takto (z hlavy, takže nemusí být úplně správná):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Zde je výhoda, za cenu určitého databázového prostoru, v tom, že časově náročnou funkci damlev musíte aplikovat pouze na jedinečná slova, která se pravděpodobně budou počítat pouze v desítkách tisíc bez ohledu na velikost vaší tabulky textu. To je důležité, protože damlev UDF nebude používat indexy - prohledá celou tabulku, na kterou je použit, aby vypočítal hodnotu pro každý řádek. Skenování pouze jedinečných slov by mělo být mnohem rychlejší. Další výhodou je, že damlev je aplikován na úrovni slova, což se zdá být to, co požadujete. Další výhodou je, že můžete rozšířit dotaz tak, aby podporoval vyhledávání podle více slov, a výsledky můžete seřadit seskupením odpovídajících protínajících se řádků v TextId a seřazením podle počtu shod.