Dal jsem dohromady ukázku transformace (klikněte pravým tlačítkem a vyberte odkaz uložit) na základě toho, co jste poskytli. Jediný krok, na kterém se cítím trochu nejistý, jsou poslední vstupy do tabulky. V podstatě zapisuji data spojení do tabulky a nechávám je selhat, pokud již existuje konkrétní vztah.
poznámka:
Toto řešení ve skutečnosti nesplňuje požadavek "Všechny přístupy by měly zahrnovat některé z validace a strategie vrácení zpět, pokud by vložení selhalo nebo selhalo při zachování referenční integrity." kritérií, i když to pravděpodobně neprojde. Pokud opravdu chcete nastavit něco složitého, můžeme, ale toto by vám s těmito transformacemi rozhodně mělo pomoci.

Datový tok za krokem
1. Začneme čtením ve vašem souboru. V mém případě jsem to převedl na CSV, ale karta je také v pořádku. 
2. Nyní vložíme jména zaměstnanců do tabulky Zaměstnanci pomocí combination lookup/update .Po vložení připojíme zaměstnanec_id k našemu datovému proudu jako id a odeberte EmployeeName z datového toku.

3. Zde pouze používáme krok Vybrat hodnoty k přejmenování id pole na zaměstnanec_id 
4. Vkládejte názvy pracovních míst stejně jako my zaměstnanci a připojte ID názvu k našemu datovému proudu, čímž také odstraníte JobLevelHistory z datového toku.

5. Jednoduché přejmenování id názvu na id_názvu (viz krok 3) 
6. Vložte kanceláře, získejte ID, odstraňte OfficeHistory ze streamu.

7. Jednoduché přejmenování id kanceláře na office_id (viz krok 3)

8. Zkopírujte data z posledního kroku do dvou streamů s hodnotami employee_id,office_id a employee_id,title_id respektive.

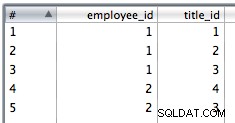
9. K vložení dat spojení použijte vložku tabulky. Vybral jsem to tak, aby se ignorovaly chyby vložení, protože mohou existovat duplikáty a omezení PK způsobí, že některé řádky selžou.
Výstupní tabulky




