Vaše otázka je opravdu nepřesný. Postupujte prosím podle návrhů @RiggsFolly a přečtěte si odkazy na to, jak položit dobrou otázku.
Také, jak navrhuje @DuduMarkovitz, měli byste začít zjednodušením problému a vyčištěním dat. Několik zdrojů pro začátek:
- Výukový program pro základní zpracování textu od Matta Denyho
- Zpracování a zpracování řetězců v R od Gastona Sancheze
Jakmile budete s výsledky spokojeni, můžete přistoupit k identifikaci skupiny pro každý Var1 vstup (to vám pomůže na cestě provádět další analýzy/manipulace s podobnými záznamy) To by se dalo udělat mnoha různými způsoby, ale jak uvádí @GordonLinoff, jedním z nich je Levenshtein Distance.
Poznámka :u 50 000 záznamů nebude výsledek 100% přesný, protože nebude vždy kategorizovat termíny do příslušné skupiny, ale to by mělo výrazně snížit manuální úsilí.
V R to můžete udělat pomocí adist()
Pomocí vašich příkladů dat:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
U tohoto malého vzorku můžete vidět 3 odlišné skupiny (shluky nízkých hodnot Leventheinovy vzdálenosti) a můžete je snadno přiřadit ručně, ale pro větší sady budete pravděpodobně potřebovat shlukovací algoritmus.
Již jsem vás v komentářích upozornil na jeden z mých předchozí odpověď
ukazuje, jak to udělat pomocí hclust() a Wardova metoda minimálního rozptylu, ale myslím, že zde by bylo lepší použít jiné techniky (jeden z mých oblíbených zdrojů na toto téma pro rychlý přehled některých nejpoužívanějších metod v R je tento podrobná odpověď
)
Zde je příklad použití shlukování šíření afinity:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
V objektu APResult najdete d_ap prvky spojené s každým shlukem a optimální počet shluků, v tomto případě:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Můžete také vidět vizuální znázornění:
> heatmap(d_ap, margins = c(10, 10))
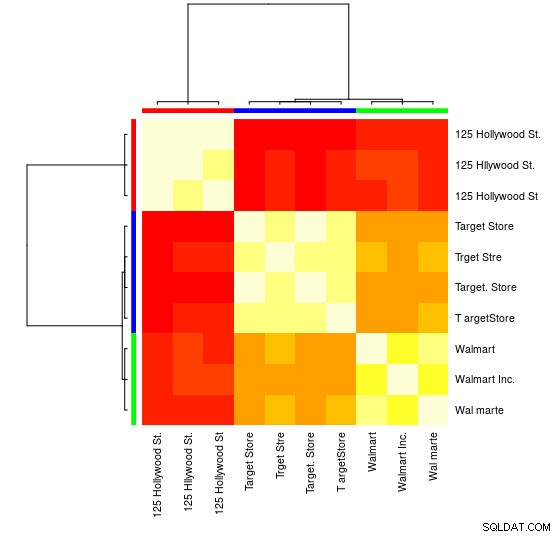
Poté můžete pro každou skupinu provádět další manipulace. Jako příklad zde používám hunspell k vyhledání jednotlivých slov z Var1 v en_US slovníku pro pravopisné chyby a pokuste se najít v každé group , které id neobsahuje žádné pravopisné chyby (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Což dává:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Poznámka :Protože jsme neprovedli žádné zpracování textu, výsledky nejsou příliš průkazné, ale máte představu.
Data
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)