Ptáte se najak vypočítat, která města jsou nejblíže související? Například. Pokud bych se díval na město 1 (Paříž), výsledky by měly být:Londýn (2), New York (3) a na základě vámi poskytnutého souboru dat existuje pouze jedna věc, kterou je třeba spojit, a to společné značky mezi městy, takže města, která sdílejí společné značky, by byla nejblíže níže uvedenému dílčímu dotazu, který najde města (jiná než která je poskytnuta najít jeho nejbližší města), která sdílí společné značky
SELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Pracuje
Předpokládám, že zadáte jedno z id města nebo jména, abyste našli jejich nejbližší v mém případě „Paříž“ má id
SELECT tag_id FROM `cities_tags` WHERE city_id=1
Najde všechny značky id, které má paříž, pak
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Načte všechna města kromě Paříže, která má stejné značky jako Paříž
Zde je vaše Fiddle
Při čtení o Jaccard podobnosti/indexu našli jsme nějaké věci k pochopení toho, co vlastně termíny jsou, vezměme si tento příklad, máme dvě sady A a B
Nyní přejděte ke svému scénáři
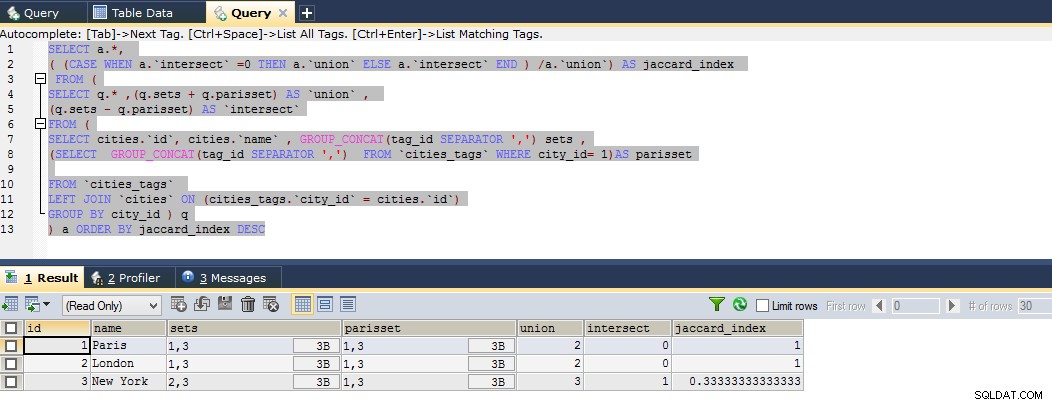
Zde je zatím dotaz, který vypočítává dokonalý index jackardů, můžete vidět níže uvedený příklad houslí
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Ve výše uvedeném dotazu jsem odvodil sadu výsledků na dva dílčí výběry, abych získal vlastní vypočítané aliasy
Filtr můžete přidat do výše uvedeného dotazu, aby se nepočítala podobnost sama se sebou
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Výsledek tedy ukazuje, že Paříž je úzce spjata s Londýnem a následně s New Yorkem