Správa paměti v PostgreSQL je důležitá pro zlepšení výkonu databázového serveru. Konfigurační soubor PostgreSQL (postgres.conf) spravuje konfiguraci databázového serveru. Používá výchozí hodnoty parametrů, ale tyto hodnoty můžeme změnit, aby lépe odrážely pracovní zátěž a operační prostředí.
V tomto blogu se budeme zabývat těmito parametry souvisejícími s pamětí. Ale než začneme, podívejme se na architekturu paměti v PostgreSQL.
Architektura paměti
Paměť v PostgreSQL lze rozdělit do dvou kategorií:
- Oblast místní paměti:Je přidělena každým procesem backendu pro jeho vlastní použití.
- Oblast sdílené paměti:Je využívána všemi procesy serveru PostgreSQL.
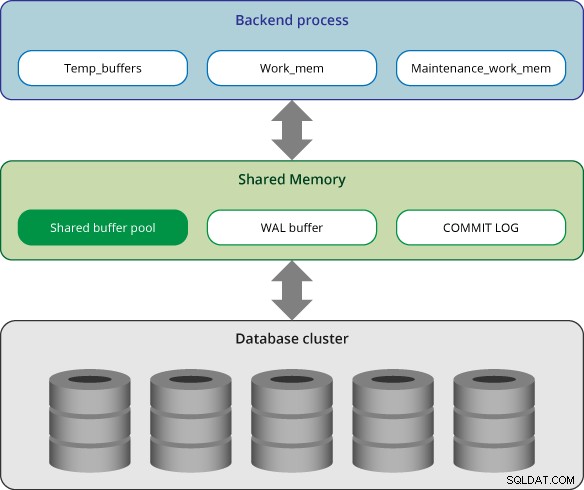
Místní paměť
V PostgreSQL každý backendový proces alokuje místní paměť pro zpracování dotazů; každá oblast je rozdělena na podoblasti, jejichž velikosti jsou buď pevné, nebo proměnlivé.
Dílčí oblasti jsou následující.
Work_mem
Exekutor tuto oblast využívá pro řazení n-tic podle operací ORDER BY a DISTINCT. Používá jej také pro spojování tabulek operacemi merge-join a hash-join.
Maintenance_work_mem
Tento parametr se používá pro některé druhy operací údržby (VACUUM, REINDEX).
Temp_buffers
Exekutor používá tuto oblast pro ukládání dočasných tabulek.
Sdílená oblast paměti
Oblast sdílené paměti je alokována serverem PostgreSQL při spuštění. Tyto oblasti jsou rozděleny do několika podoblastí s pevnou velikostí.
Sdílený fond vyrovnávacích pamětí
PostgreSQL načítá stránky v tabulkách a indexech z trvalého úložiště do sdílené vyrovnávací paměti a poté s nimi přímo pracuje.
Vyrovnávací paměť WAL
PostgreSQL podporuje mechanismus WAL (Write advance log), který zajišťuje, že po selhání serveru nebudou ztracena žádná data. Data WAL jsou ve skutečnosti transakční protokol v PostgreSQL a vyrovnávací paměť WAL je oblast vyrovnávací paměti dat WAL před jejich zapsáním do trvalého úložiště.
Protokol potvrzení
Protokol potvrzení (CLOG) uchovává stavy všech transakcí a je součástí mechanismu kontroly souběžnosti. Záznam odevzdání je přidělen sdílené paměti a používán během zpracování transakce.
PostgreSQL definuje následující čtyři stavy transakcí.
- PROBÍHÁ
- ODPOVĚDĚNO
- ZRUŠENO
- SUB-ODPOVĚDĚNÍ
Ladění parametrů paměti PostgreSQL
Existuje několik důležitých parametrů, které jsou doporučeny pro správu paměti v PostgreSQL. Měli byste vzít v úvahu následující.
Shared_buffers
Tento parametr určuje množství paměti použité pro vyrovnávací paměti sdílené paměti. Parametr shared_buffers určuje, kolik paměti je vyhrazeno serveru pro ukládání dat do mezipaměti. Výchozí hodnota shared_buffers je obvykle 128 megabajtů (128 MB).
Výchozí hodnota tohoto parametru je velmi nízká, protože na některých platformách, jako jsou starší verze Solaris a SGI, vyžadují velké hodnoty invazivní akci, jako je rekompilace jádra. Dokonce ani na moderních systémech Linux jádro pravděpodobně neumožní nastavení sdílených_bufferů na více než 32 MB, aniž by bylo nutné nejprve upravit nastavení jádra.
Mechanismus se změnil v PostgreSQL 9.4 a novějších, takže zde nebude nutné upravovat nastavení jádra.
Pokud je databázový server vysoce zatížen, pak nastavení vysoké hodnoty zlepší výkon.
Pokud máte vyhrazený DB server s 1 GB nebo více paměti RAM, rozumná počáteční hodnota konfiguračního parametru shared_buffer je 25 % paměti ve vašem systému.
Výchozí hodnota sdílených_bufferů =128 MB. Změna vyžaduje restart PostgreSQL serveru.
Obecné doporučení pro nastavení shared_buffers je následující.
- Na méně než 2 GB paměti nastavte hodnotu shared_buffers na 20 % celkové systémové paměti.
- Na méně než 32 GB nastavte hodnotu shared_buffers na 25 % celkové systémové paměti.
- Nad 32 GB paměti nastavte hodnotu shared_buffers na 8 GB
Work_mem
Tento parametr určuje množství paměti, které má být použito interními operacemi řazení a hashovacími tabulkami před zápisem do dočasných diskových souborů. Pokud se děje mnoho složitých řazení a máte dostatek paměti, pak zvýšení parametru work_mem umožňuje PostgreSQL provádět větší řazení v paměti, které bude rychlejší než ekvivalenty založené na disku.
Všimněte si, že u složitého dotazu může paralelně běžet mnoho operací řazení nebo hašování. Každá operace bude mít povoleno použít tolik paměti, kolik určuje tato hodnota, než začne zapisovat data do dočasných souborů. Existuje jedna možnost, že by takové operace mohlo provádět několik relací současně. Celková použitá paměť tedy může být mnohonásobkem hodnoty parametru work_mem.
Pamatujte na to při výběru správné hodnoty. Operace řazení se používají pro spojení ORDER BY, DISTINCT a merge. Hashovací tabulky se používají v hašovacích spojeních, hašovacím zpracování IN poddotazů a hašovací agregaci.
Parametr log_temp_files lze použít k protokolování řazení, hash a dočasných souborů, což může být užitečné při zjišťování, zda se řazení přelévá na disk místo toho, aby se vešlo do paměti. Pomocí plánů EXPLAIN ANALYZE můžete zkontrolovat, jak se řazení přelévají na disk. Pokud například ve výstupu EXPLAIN ANALYZE uvidíte řádek jako:„Metoda řazení:externí slučovací disk:7528 kB “, work_mem o velikosti alespoň 8 MB by uchovala mezilehlá data v paměti a zkrátila by dobu odezvy na dotaz.
Výchozí hodnota work_mem =4 MB.
Obecné doporučení pro nastavení work_mem je následující.
- Začněte s nízkou hodnotou:32–64 MB
- Potom vyhledejte v protokolech řádky „dočasný soubor“
- Nastavit na 2–3násobek největšího dočasného souboru
údržba _work_mem
Tento parametr určuje maximální množství paměti používané operacemi údržby, jako je VACUUM, CREATE INDEX a ALTER TABLE ADD FOREIGN KEY. Vzhledem k tomu, že databázovou relací může být současně provedena pouze jedna z těchto operací a instalace PostgreSQL jich nemá příliš spuštěných souběžně, je bezpečné nastavit hodnotu maintenance_work_mem výrazně větší než work_mem.
Nastavení vyšší hodnoty může zlepšit výkon při vysávání a obnově výpisů databáze.
Je nutné pamatovat na to, že při spuštění autovacuum může být tato paměť přidělena až autovacuum_max_workers krát, takže dávejte pozor, abyste výchozí hodnotu nenastavili příliš vysoko.
Výchozí hodnota maintenance_work_mem =64 MB.
Obecné doporučení pro nastavení maintenance_work_mem je následující.
- Nastavte hodnotu 10 % systémové paměti, až 1 GB
- Možná můžete nastavit ještě vyšší hodnotu, pokud máte problémy s VAKUEM
Effective_cache_size
Efektivní_velikost_cache by měla být nastavena na odhad toho, kolik paměti je k dispozici pro ukládání do mezipaměti disku operačním systémem a v rámci samotné databáze. Toto je vodítko pro to, kolik paměti očekáváte, že bude k dispozici v operačním systému a mezipaměti PostgreSQL, nikoli alokace.
Plánovač dotazů PostgreSQL používá tuto hodnotu k tomu, aby zjistil, zda se očekává, že se plány, o kterých uvažuje, vejdou do RAM nebo ne. Pokud je nastavena příliš nízko, indexy nemusí být použity pro provádění dotazů tak, jak byste očekávali. Protože většina unixových systémů je při ukládání do mezipaměti poměrně agresivní, nejméně 50 % dostupné paměti RAM na vyhrazeném databázovém serveru bude plných dat uložených v mezipaměti.
Obecné doporučení pro efektivní_cache_size je následující.
- Nastavte hodnotu na velikost dostupné mezipaměti systému souborů
- Pokud nevíte, nastavte hodnotu na 50 % celkové systémové paměti
Výchozí hodnota efektivní_cache_size =4 GB.
Temp_buffers
Tento parametr nastavuje maximální počet dočasných vyrovnávacích pamětí používaných každou relací databáze. Lokální vyrovnávací paměti relace se používají pouze pro přístup k dočasným tabulkám. Nastavení tohoto parametru lze změnit v rámci jednotlivých relací, ale pouze před prvním použitím dočasných tabulek v rámci relace.
Databáze PostgreSQL využívá tuto paměťovou oblast pro uchovávání dočasných tabulek každé relace, ty budou vymazány, když se spojení ukončí.
Výchozí hodnota temp_buffer =8 MB.
Závěr
Pro zlepšení výkonu je důležité porozumět architektuře paměti a vyladit příslušné parametry. To je nutné zejména u systémů s vysokou zátěží. Více obecných tipů pro ladění výkonu naleznete v tomto cheat sheetu pro výkon PostgreSQL.