Úvod
V dnešní době je vysoká dostupnost požadavkem mnoha systémů bez ohledu na to, jakou technologii používáte. To je důležité zejména pro databáze, protože ukládají data, na která spoléhají kritické aplikace a systémy. Nejběžnější strategií pro dosažení vysoké dostupnosti je replikace. Existují různé způsoby, jak replikovat data na více serverech a provoz při selhání, když například primární server přestane reagovat.
Architektura vysoké dostupnosti pro PostgreSQL
Existuje několik architektur pro implementaci vysoké dostupnosti v PostgreSQL, ale ty základní jsou architektury Primary-Standby a Primary-Primary.
Architektury primárního pohotovostního režimu
Primary-Standby může být nejzákladnější architekturou HA, kterou můžete nastavit, a často je nejjednodušší implementovat a udržovat. Je založen na jedné primární databázi s jedním nebo více pohotovostními servery. Tyto pohotovostní databáze zůstanou synchronizované (nebo téměř synchronizované) s primárním uzlem v závislosti na tom, zda je replikace synchronní nebo asynchronní. Pokud primární server selže, pohotovostní server obsahuje téměř všechna data primárního serveru a lze jej rychle změnit na nový primární databázový server.
Můžete implementovat dva typy pohotovostních databází v závislosti na povaze replikace:
- Logické pohotovostní režimy – replikace mezi primárním a pohotovostním režimem se provádí pomocí příkazů SQL.
- Fyzické pohotovostní režimy – replikace mezi primárním a pohotovostním režimem se provádí prostřednictvím úprav interní datové struktury.
V případě PostgreSQL se k udržení synchronizace pohotovostních databází používá proud záznamů protokolu WAL (write-ahead). To může být synchronní nebo asynchronní a celý databázový server je replikován.
Počínaje verzí 10 obsahuje PostgreSQL vestavěnou možnost nastavení logické replikace, která vytváří proud logických úprav dat z informací v protokolu pro zápis napřed. Tato metoda replikace umožňuje replikaci změn dat z jednotlivých tabulek, aniž by bylo nutné určit primární server. Umožňuje také tok dat v několika směrech.
Nastavení primárního pohotovostního režimu bohužel nestačí k efektivnímu zajištění vysoké dostupnosti, protože musíte také řešit selhání. Abyste zvládli selhání, musíte je umět odhalit. Jakmile zjistíte, že došlo k poruše, například chyby na primárním uzlu nebo uzel neodpovídá, můžete vybrat pohotovostní uzel, který poruchový uzel nahradí s co nejmenším zpožděním. Tento proces musí být co nejúčinnější pro obnovení plné funkčnosti aplikací. PostgreSQL sám o sobě nezahrnuje mechanismus automatického převzetí služeb při selhání, takže to bude vyžadovat nějaký vlastní skript nebo nástroje třetích stran pro tuto automatizaci.
Jakmile dojde k převzetí služeb při selhání, musí být vaše aplikace příslušným způsobem upozorněna, aby mohla začít používat nové primární. Musíte také vyhodnotit stav vaší architektury po převzetí služeb při selhání, protože se můžete dostat do situace, kdy běží pouze nový primární uzel (např. před problémem jste měli primární uzel a pouze jeden pohotovostní režim). V takovém případě budete muset přidat uzel pohotovostního režimu, abyste znovu vytvořili nastavení primárního pohotovostního režimu, které jste původně měli pro vysokou dostupnost.
Primární-primární architektury
Primární-primární architektura poskytuje způsob, jak minimalizovat dopad chyby na jeden z uzlů, protože ostatní uzel(y) se může postarat o veškerý provoz, pouze potenciálně mírně ovlivňuje výkon ale nikdy neztratí funkčnost. Primární-primární architektura se často používá s dvojím účelem:vytvoření prostředí s vysokou dostupností a horizontální škálování (ve srovnání s konceptem vertikální škálovatelnosti, kdy na server přidáváte více prostředků).
PostgreSQL zatím tuto architekturu "nativně" nepodporuje, takže se budete muset obrátit na nástroje a implementace třetích stran. Při výběru řešení musíte mít na paměti, že existuje mnoho projektů/nástrojů, ale některé z nich již nejsou podporovány, zatímco jiné jsou nové a nemusí být otestovány ve výrobě.
Vyrovnávání zátěže
Nástroje pro vyrovnávání zatížení jsou nástroje, které lze použít ke správě provozu z vaší aplikace, abyste z architektury své databáze vytěžili maximum.
Tyto nástroje jsou užitečné nejen při vyrovnávání zatížení vašich databází, ale také pomáhají aplikacím přesměrovat se na dostupné/zdravé uzly a dokonce určit porty s různými rolemi.
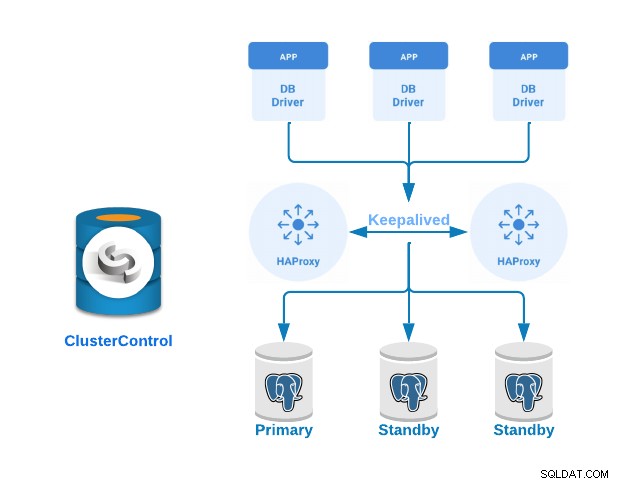
HAProxy je nástroj pro vyrovnávání zatížení, který distribuuje provoz z jednoho zdroje do jednoho nebo více cílů a může pro tento úkol definovat specifická pravidla a/nebo protokoly. Pokud některý z cílů přestane reagovat, bude označen jako offline a provoz je odeslán do zbývajících dostupných cílů.
Keepalived je služba, která vám umožňuje konfigurovat virtuální IP adresu v rámci aktivní/pasivní skupiny serverů. Tato virtuální IP adresa je přiřazena aktivnímu serveru. Pokud tento server selže, IP adresa je automaticky migrována na „sekundární“ pasivní server, což mu umožňuje pokračovat v práci se stejnou IP adresou transparentním způsobem pro systémy.
Pojďme se nyní podívat, jak implementovat Primární pohotovostní PostgreSQL cluster se servery pro vyrovnávání zátěže a mezi nimi nakonfigurovanými keepalived. To předvedeme pomocí snadno použitelného rozhraní ClusterControl.
Pro tento příklad vytvoříme:
- 3 PostgreSQL servery (jeden primární a dva pohotovostní).
- 2 HAProxy Load Balancery.
- Zachováno nakonfigurováno mezi servery pro vyrovnávání zatížení.
Nasazení databáze
Chcete-li nasadit databázi pomocí ClusterControl, jednoduše vyberte možnost „Deploy“ a postupujte podle zobrazených pokynů.
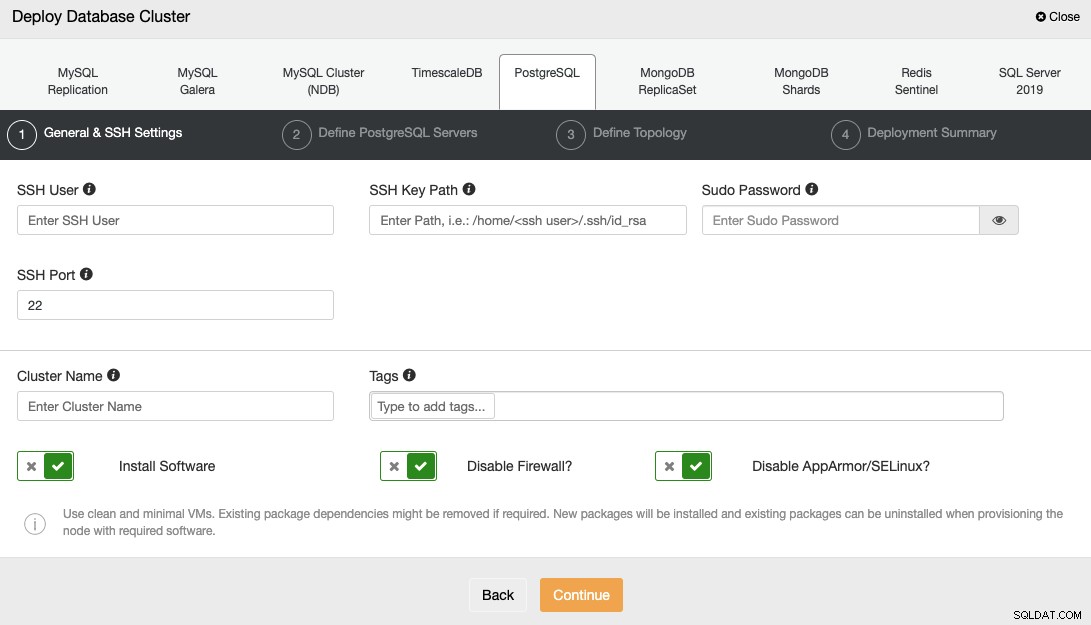
Při výběru PostgreSQL musíte zadat uživatele, klíč nebo heslo a Port pro připojení pomocí SSH k vašim serverům. Potřebujete také název svého nového clusteru a zvolit, zda chcete, aby ClusterControl nainstaloval odpovídající software a konfigurace za vás.
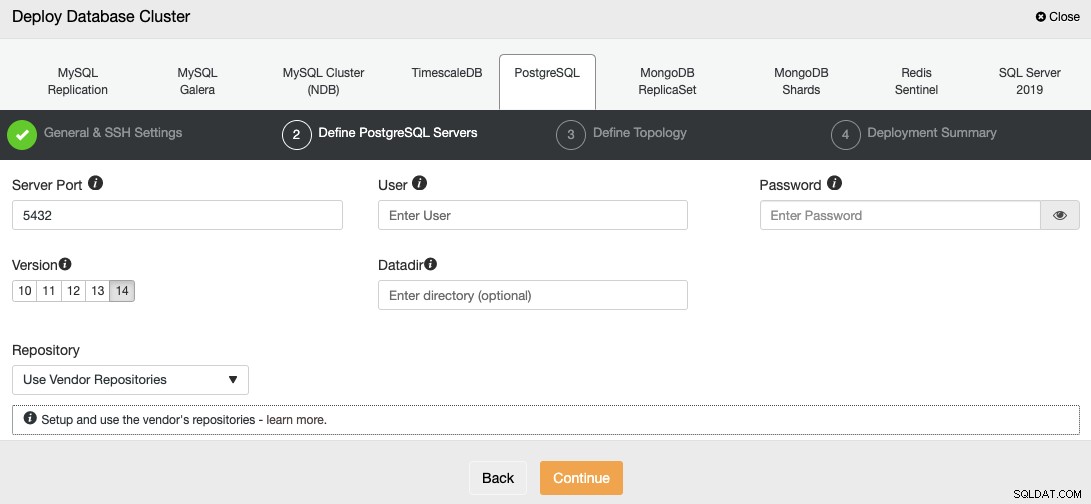
Po nastavení přístupových informací SSH musíte definovat uživatele databáze, verze a datadir (volitelné). Můžete také určit, které úložiště použít; ve výchozím nastavení se použije oficiální úložiště dodavatele.
V dalším kroku musíte přidat své servery do clusteru, který vytvoříte.
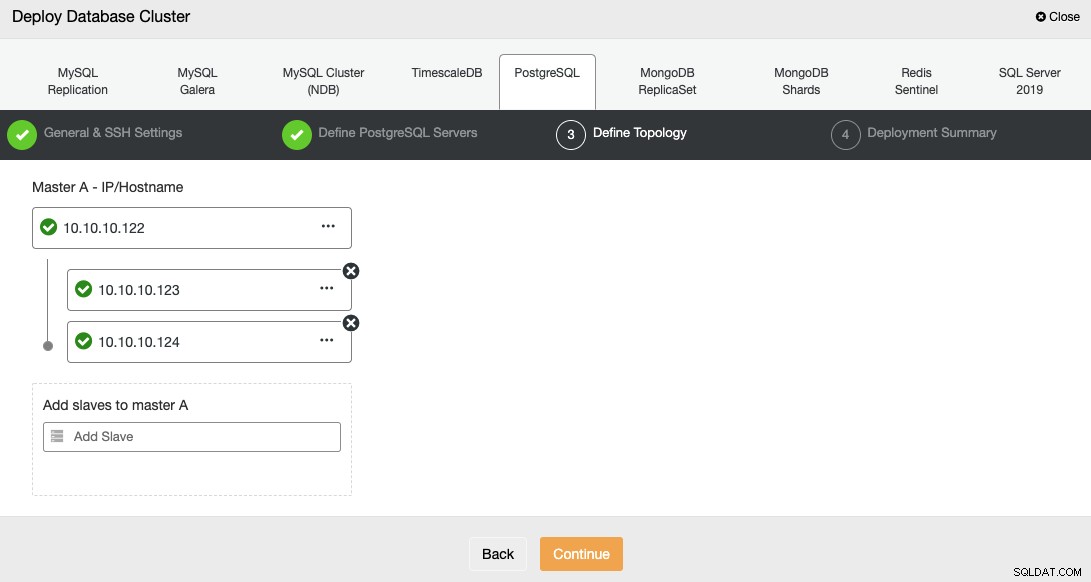
Při přidávání serverů můžete zadat IP nebo název hostitele.
V posledním kroku si můžete vybrat, zda bude vaše replikace synchronní nebo asynchronní.
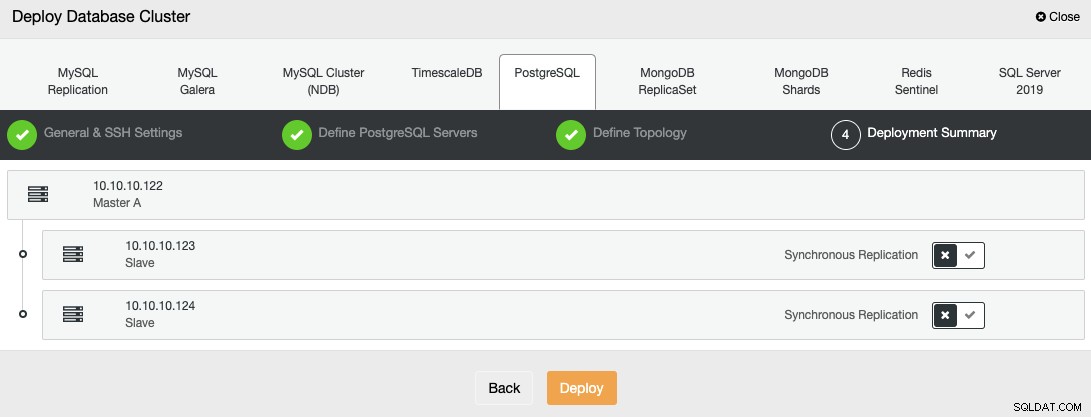
Stav vytváření nového clusteru můžete sledovat z ClusterControl monitor aktivity.
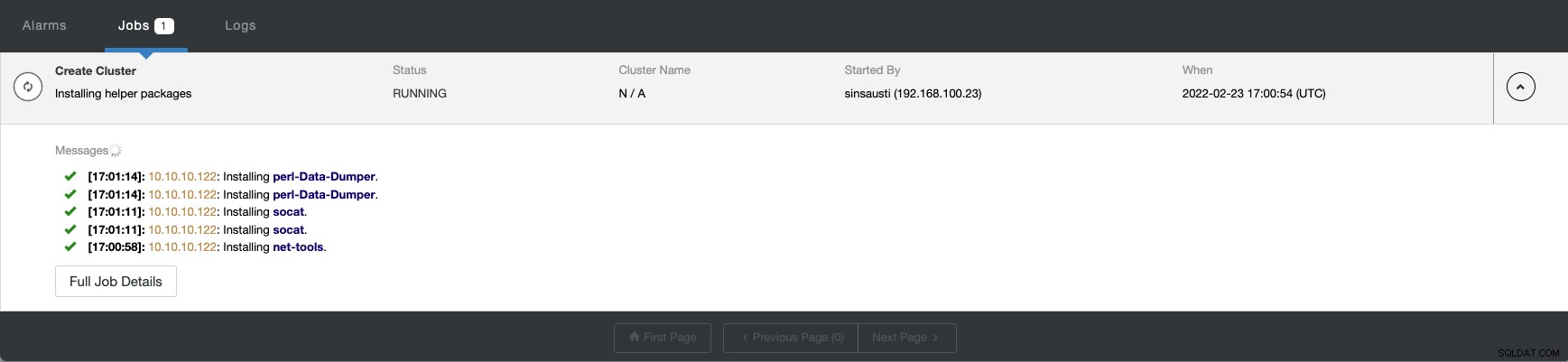
Po dokončení úlohy uvidíte svůj cluster v hlavním ClusterControl obrazovka.
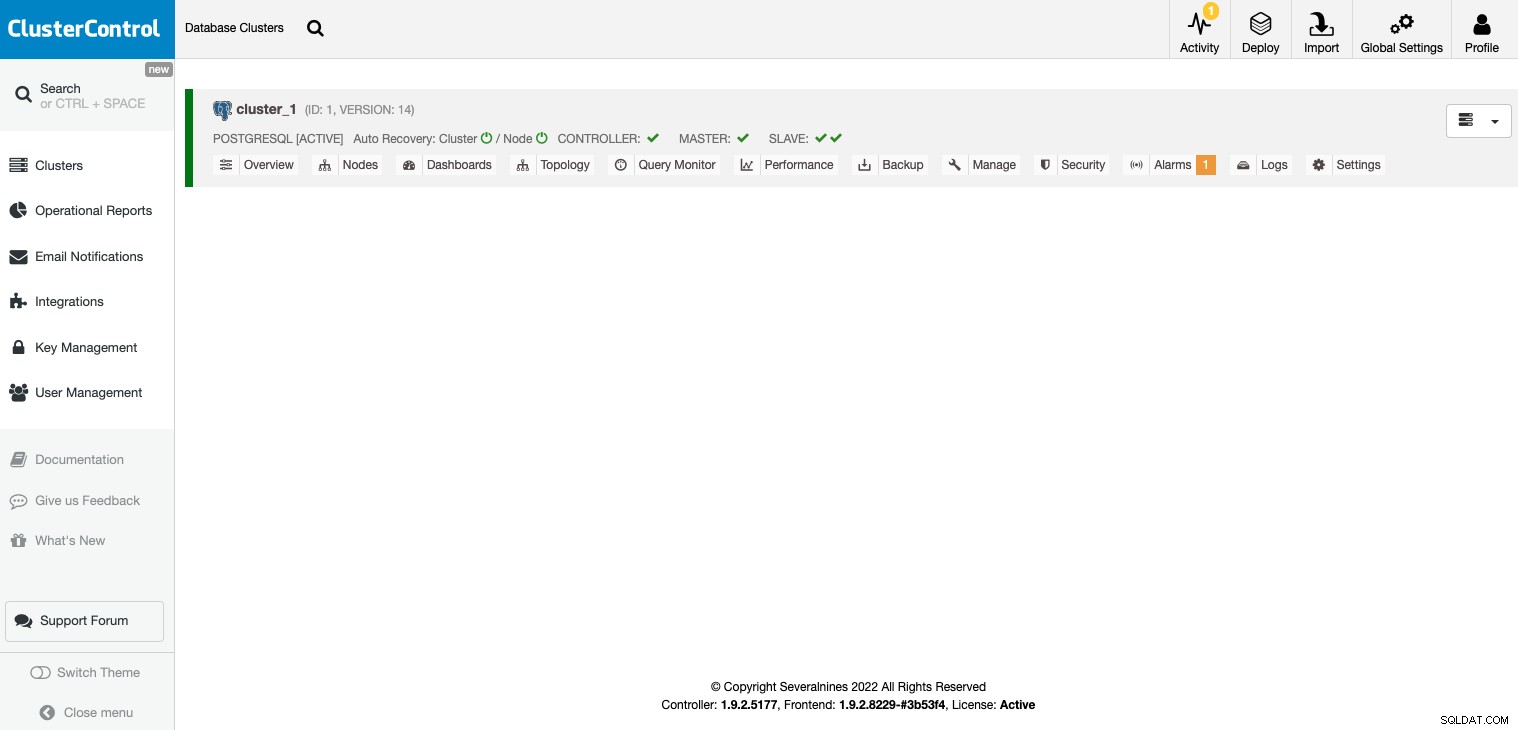
Jakmile je cluster vytvořen, můžete provádět několik úkolů, jako je přidání load balancer (HAProxy) nebo novou repliku.
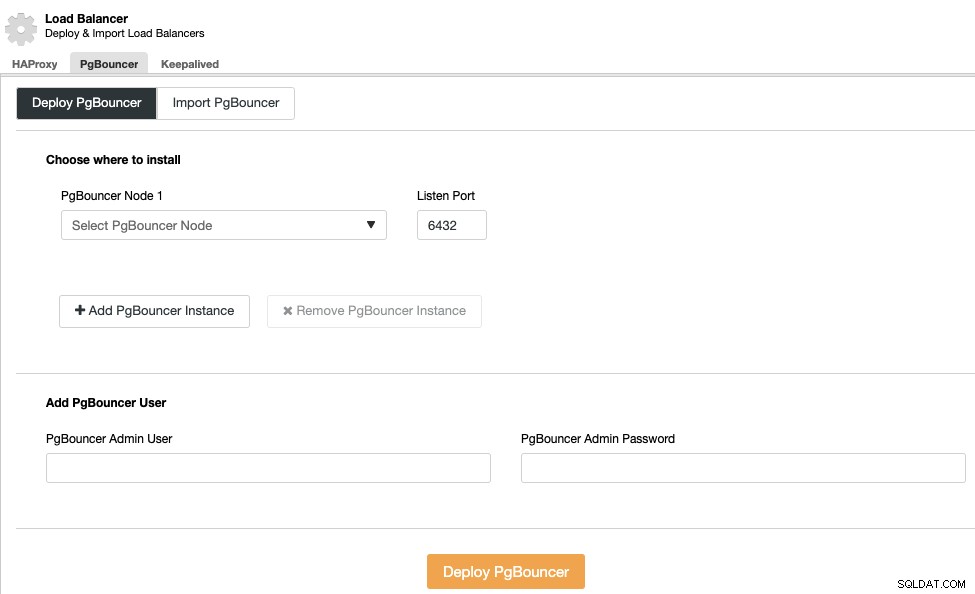
Nasazení nástroje Load Balancer
Chcete-li provést nasazení nástroje pro vyrovnávání zatížení, vyberte v akcích clusteru možnost „Přidat nástroj pro vyrovnávání zatížení“ a vyplňte požadované informace.
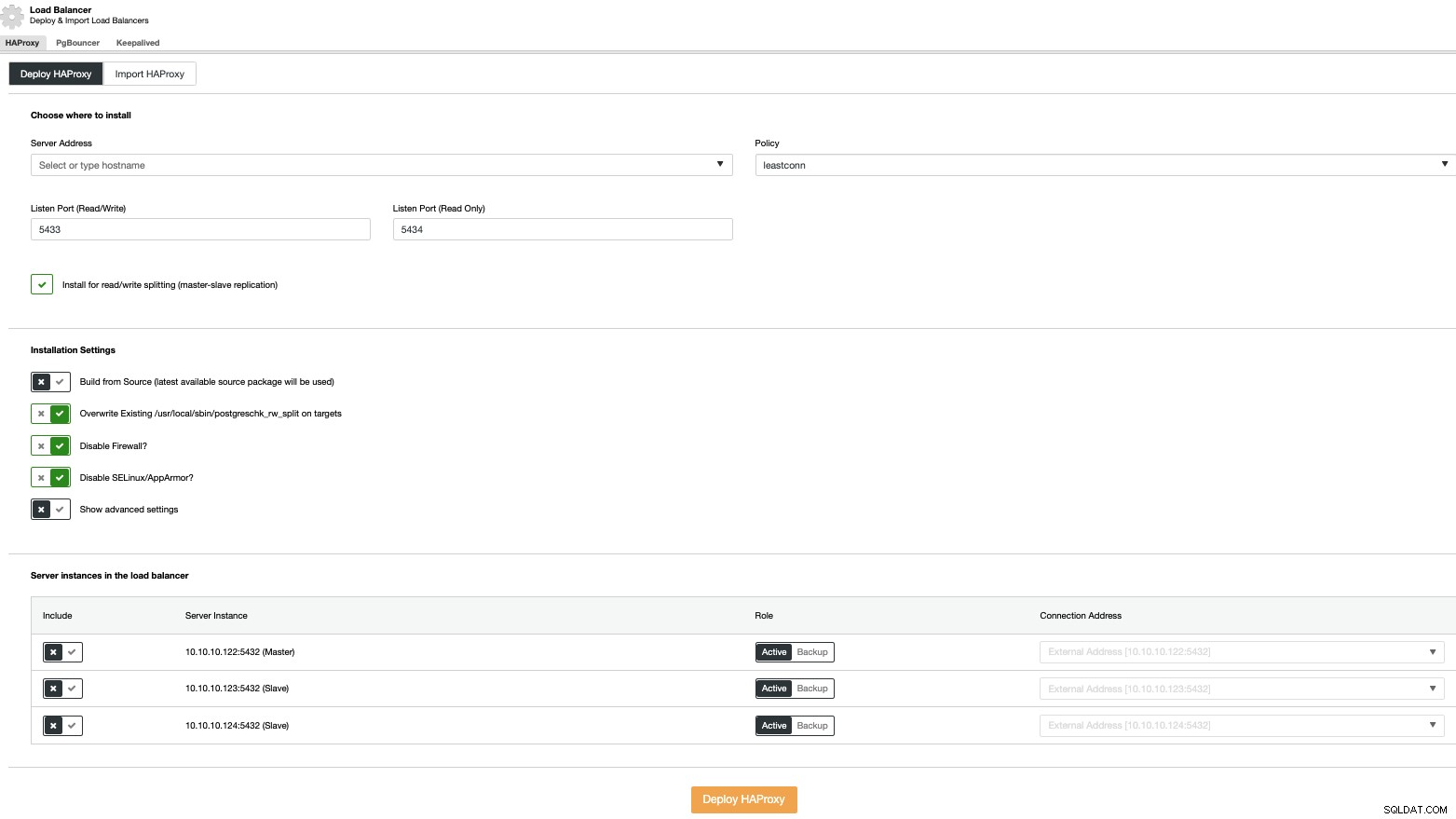
Stačí přidat IP adresu nebo název hostitele, port, zásady, a uzly, které nakonfigurujete ve svých nástrojích pro vyrovnávání zatížení.
Keepalived Deployment
Chcete-li provést nasazení keepalived, vyberte cluster, přejděte do nabídky „Spravovat“ a část „Load Balancer“ a poté vyberte možnost „Keepalived“.
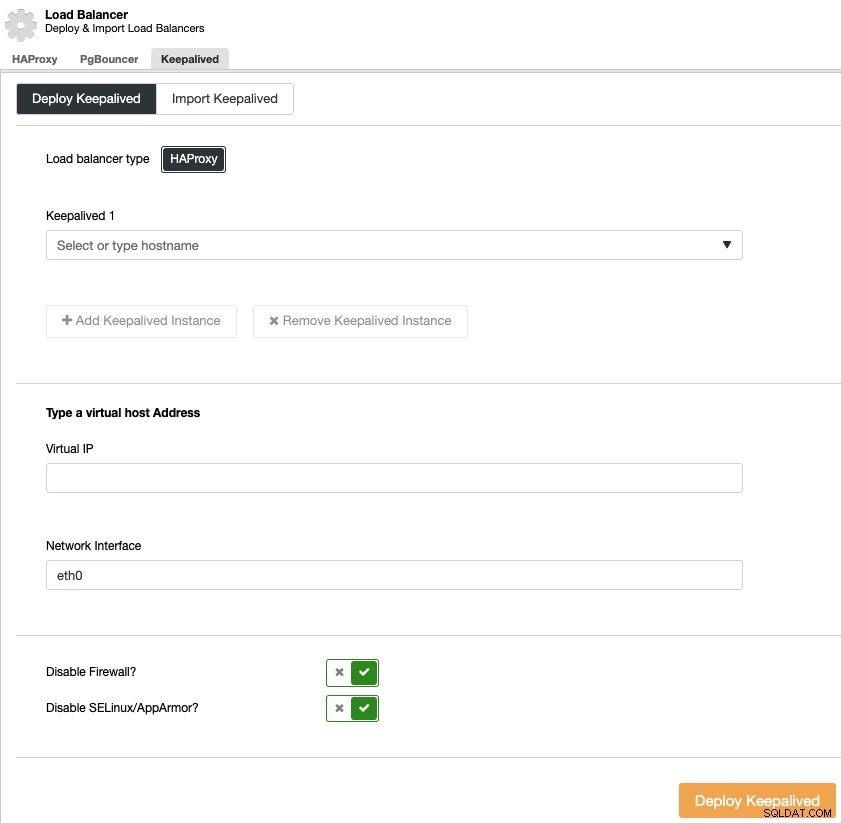
Musíte vybrat servery pro vyrovnávání zatížení a virtuální IP adresu prostředí dostupnosti.
Keepalived používá virtuální IP adresu a v případě selhání ji migruje z jednoho nástroje pro vyrovnávání zatížení do druhého, takže vaše systémy mohou nadále normálně fungovat.
Pokud jste postupovali podle předchozích kroků, měli byste mít následující topologii:
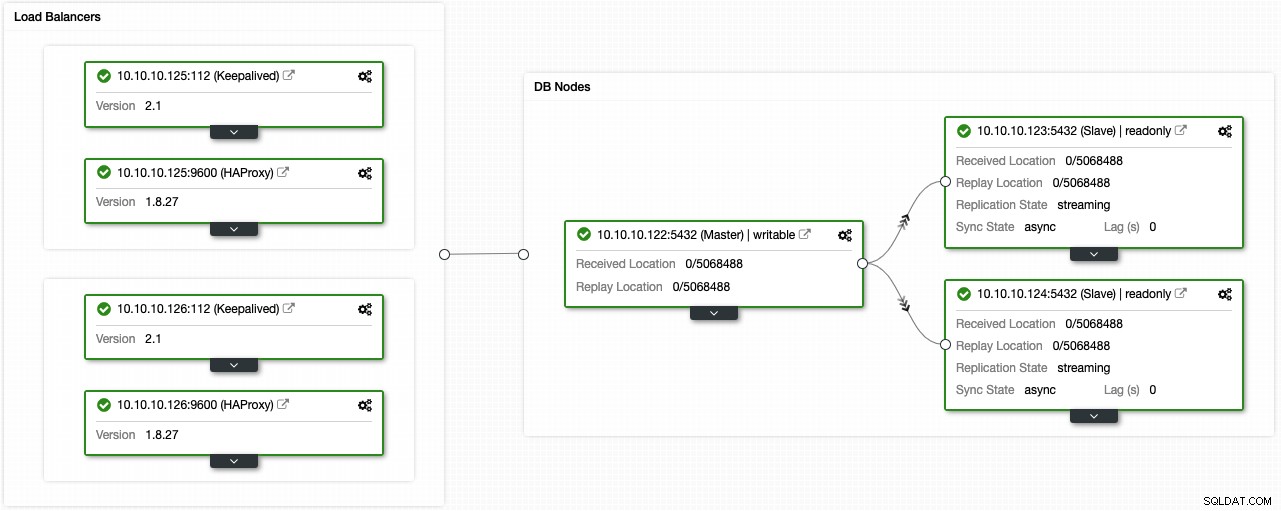
Toto prostředí s vysokou dostupností můžete vylepšit přidáním fondu připojení, jako je PgBouncer. Není to nutnost, ale mohlo by to být užitečné pro zlepšení výkonu a zpracování aktivních připojení v případě selhání, a nejlepší na tom je, že jej můžete nasadit také pomocí ClusterControl.
ClusterControl Failover
Předpokládejme, že na vašem serveru ClusterControl je zapnutá možnost „Autorecovery“. V případě primárního selhání ClusterControl povýší nejpokročilejší pohotovostní režim (pokud není na černé listině) na Primární a také vás upozorní na problém. Převezme také selhání zbývajících uzlů pohotovostního režimu, které se mají replikovat z nového primárního.
HAProxy je standardně nakonfigurován se dvěma různými porty; porty pro čtení, zápis a pouze pro čtení.
V portu pro čtení a zápis máte primární server online a ostatní uzly offline a na portu pouze pro čtení máte primární i pohotovostní režim online.
Když HAProxy zjistí, že některý z vašich uzlů, ať už primární nebo pohotovostní, není dostupný, automaticky jej označí jako offline. Nebere to v úvahu při odesílání provozu na něj. Detekce se provádí pomocí skriptů kontroly stavu, které ClusterControl konfiguruje v době nasazení. Tyto kontrolují, zda jsou instance aktivní, zda procházejí obnovením nebo jsou pouze pro čtení.
Když ClusterControl povýší pohotovostní režim na primární, vaše HAProxy označí starý primární uzel jako offline pro oba porty a přepne povýšený uzel online do portu pro čtení a zápis.
Pokud vaše aktivní HAProxy, která má přiřazenou virtuální IP adresu, ke které se vaše systémy připojují, selže, Keepalived automaticky migruje tuto IP adresu na pasivní HAProxy. To znamená, že vaše systémy jsou poté schopny normálně fungovat.
Tímto způsobem budou vaše systémy nadále fungovat podle očekávání a bez vašeho ručního zásahu.
Úvahy
Pokud se vám podaří obnovit starý neúspěšný primární uzel, NEBUDE ve výchozím nastavení automaticky znovu zaveden do clusteru. Musíte to udělat ručně. Jedním z důvodů je, že pokud by se vaše replika v době selhání zpozdila a ClusterControl přidá do clusteru starý Primární, znamenalo by to ztrátu informací nebo nekonzistenci dat napříč uzly. Možná budete chtít problém podrobně analyzovat. Pokud by ClusterControl právě znovu zavedl neúspěšný uzel do clusteru, možná byste přišli o diagnostické informace.
Pokud se převzetí služeb při selhání nezdaří, nebudou provedeny žádné další pokusy. K analýze problému a provedení odpovídajících akcí je nutný manuální zásah. Je to proto, aby se zabránilo situaci, kdy se ClusterControl jako správce vysoké dostupnosti pokusí propagovat další pohotovostní režim a další. Může nastat problém a budete to muset zkontrolovat.
Zabezpečení
Jedna důležitá věc, na kterou nesmíte zapomenout, než se pustíte do produkčního prostředí s vysokou dostupností, je zajistit jeho bezpečnost.
Několik bezpečnostních aspektů, které je třeba zvážit, zahrnuje šifrování, správu rolí a omezení přístupu podle IP adresy, kterým jsme se podrobně věnovali v předchozím blogu.
V databázi PostgreSQL máte soubor pg_hba.conf, který se stará o autentizaci klienta. Můžete omezit typ připojení, zdrojovou IP adresu nebo síť, ke které databázi se můžete připojit a ke kterým uživatelům. Proto je tento soubor kritickou součástí zabezpečení PostgreSQL.
Svou databázi PostgreSQL můžete nakonfigurovat ze souboru postgresql.conf, takže naslouchá pouze na konkrétním síťovém rozhraní a jiném portu, než je výchozí (5432), čímž se vyhnete základním pokusům o připojení z nechtěných zdrojů .
Správná správa uživatelů, ať už pomocí bezpečných hesel nebo omezení přístupu a oprávnění, je další důležitou součástí vašeho nastavení zabezpečení. Doporučuje se, abyste všem uživatelům přidělili co nejmenší počet oprávnění a pokud možno uvedli zdroj připojení.
Můžete také povolit šifrování dat, ať už při přenosu, nebo v klidu, abyste zabránili přístupu k informacím neoprávněným osobám.
Protokol auditu je užitečný pro pochopení toho, co se děje nebo stalo ve vaší databázi. PostgreSQL vám umožňuje nakonfigurovat několik parametrů pro protokolování nebo dokonce pro tento úkol použít rozšíření pgAudit.
V neposlední řadě se doporučuje udržovat databázi a servery aktuální pomocí nejnovějších oprav, abyste se vyhnuli bezpečnostním rizikům. Za tímto účelem vám ClusterControl umožňuje generovat provozní zprávy, abyste ověřili, zda máte dostupné aktualizace, a dokonce vám pomohou aktualizovat vaše databázové servery.
Závěr
Nasazení vysoké dostupnosti se může zdát obtížné dosáhnout, zejména pokud jde o pochopení různých architektur a komponent nezbytných pro jejich správnou konfiguraci.
Pokud spravujete HA ručně, nezapomeňte se podívat na Provádění změn topologie replikace pro PostgreSQL. Mnozí budou hledat nástroje jako ClusterControl, které jim pomohou spravovat nasazení, nástroje pro vyrovnávání zátěže, převzetí služeb při selhání, zabezpečení a další pro kompletní prostředí s vysokou dostupností. ClusterControl si můžete zdarma stáhnout na 30 dní, abyste viděli, jak může snížit zátěž související se správou infrastruktury databáze s vysokou dostupností.
Ať už se rozhodnete spravovat své databáze PostgreSQL s vysokou dostupností, nezapomeňte nás sledovat na Twitteru nebo LinkedIn nebo se přihlaste k odběru našeho newsletteru, kde získáte nejnovější aktualizace a osvědčené postupy pro správu nastavení databáze.