V kterémkoli z motorů relačních databází je vyžadováno vygenerování nejlepšího možného plánu, který odpovídá provedení dotazu s co nejmenším časem a prostředky. Obecně všechny databáze generují plány ve formátu stromové struktury, kde listový uzel každého plánovacího stromu se nazývá uzel skenování tabulky. Tento konkrétní uzel plánu odpovídá algoritmu, který se má použít k načtení dat ze základní tabulky.
Uvažujme například jednoduchý příklad dotazu jako SELECT * FROM TBL1, TBL2 kde TBL2.ID>1000; a předpokládejme, že vygenerovaný plán je následující:
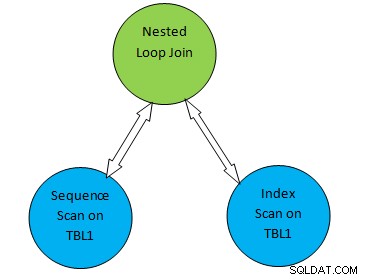
Takže ve výše uvedeném stromu plánu „Sekvenční skenování na TBL1“ a „ Index Scan on TBL2” odpovídá metodě prohledávání tabulky na stole TBL1 a TBL2. Takže podle tohoto plánu bude TBL1 načten postupně z odpovídajících stránek a TBL2 bude přístupný pomocí INDEX Scan.
Výběr správné metody skenování jako součást plánu je velmi důležitý z hlediska celkového výkonu dotazů.
Než se pustíme do všech typů metod skenování podporovaných PostgreSQL, zrevidujeme některé z hlavních klíčových bodů, které budeme často používat, když procházíme blog.
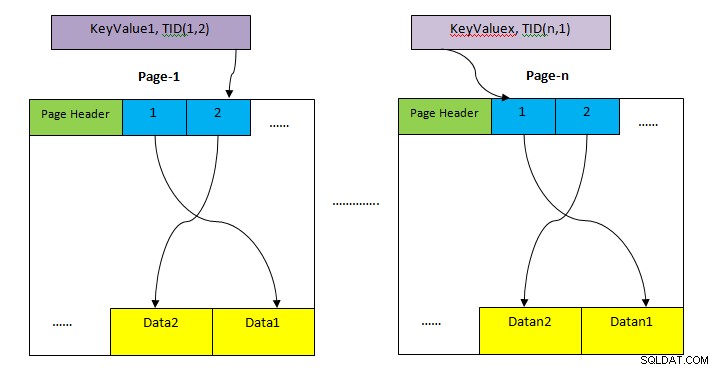
- HEAP: Odkládací plocha pro uložení celé řady stolu. Ta je rozdělena na více stránek (jak je znázorněno na obrázku výše) a každá velikost stránky je standardně 8 kB. Na každé stránce ukazuje každý ukazatel položky (např. 1, 2, ….) na data na stránce.
- Indexové úložiště: Toto úložiště ukládá pouze hodnoty klíčů, tj. hodnoty sloupců obsažené v indexu. Toto je také rozděleno na více stránek a každá velikost stránky je ve výchozím nastavení 8 kB.
- Identifikátor n-tice (TID): TID je 6bajtové číslo, které se skládá ze dvou částí. První částí je 4bajtové číslo stránky a zbývající 2bajtový index n-tice uvnitř stránky. Kombinace těchto dvou čísel jednoznačně ukazuje na umístění úložiště pro konkrétní n-tici.
V současné době PostgreSQL podporuje níže uvedené metody skenování, pomocí kterých lze všechna požadovaná data načíst z tabulky:
- Sekvenční skenování
- Skenování indexu
- Prohledávání pouze indexu
- Skenování bitmap
- Skenování TID
Každá z těchto metod skenování je stejně užitečná v závislosti na dotazu a dalších parametrech, např. mohutnost tabulky, selektivita tabulky, náklady na diskové I/O, náhodné I/O náklady, sekvenční I/O náklady atd. Vytvořme nějakou přednastavenou tabulku a naplňte ji daty, která budou často používána pro lepší vysvětlení těchto metod skenování .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEV tomto příkladu je tedy vložen jeden milion záznamů a poté je tabulka analyzována, aby byly všechny statistiky aktuální.
Sekvenční skenování
Jak název napovídá, sekvenční skenování tabulky se provádí postupným skenováním všech ukazatelů položek na všech stránkách odpovídajících tabulek. Pokud tedy existuje 100 stránek pro konkrétní tabulku a pak je na každé stránce 1000 záznamů, v rámci sekvenčního skenování načte 100*1000 záznamů a zkontroluje, zda se shodují podle úrovně izolace a také podle predikátové klauzule. Takže i když je v rámci skenování celé tabulky vybrán pouze 1 záznam, bude muset prohledat 100 000 záznamů, aby našel kvalifikovaný záznam podle podmínky.
Podle výše uvedené tabulky a údajů povede následující dotaz k sekvenčnímu skenování, protože se vybírá většina dat.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)POZNÁMKA
Přestože bez výpočtu a porovnání nákladů plánu je téměř nemožné určit, jaký druh skenování bude použit. Aby však bylo možné použít sekvenční skenování, měla by se alespoň níže uvedená kritéria shodovat:
- Pro klíč, který je součástí predikátu, není k dispozici žádný index.
- Většina řádků se načítá jako součást dotazu SQL.
TIPY
V případě, že se načítá jen velmi málo % řádků a predikát je v jednom (nebo více) sloupcích, zkuste vyhodnotit výkon s indexem nebo bez něj.
Skenování indexu
Na rozdíl od sekvenčního prohledávání nenačítá indexové prohledávání všechny záznamy sekvenčně. Spíše používá jinou datovou strukturu (v závislosti na typu indexu) odpovídající indexu zahrnutému v dotazu a vyhledá požadovaná data (podle predikátu) s minimálním prohledáváním. Poté záznam nalezený pomocí skenování indexu ukazuje přímo na data v oblasti haldy (jak je znázorněno na obrázku výše), která se pak načtou pro kontrolu viditelnosti podle úrovně izolace. Takže pro skenování indexu existují dva kroky:
- Načítání dat z datové struktury související s indexem. Vrací TID odpovídajících dat v haldě.
- Poté je přímo otevřena odpovídající stránka haldy, kde lze získat celá data. Tento dodatečný krok je vyžadován z následujících důvodů:
- Dotaz mohl požadovat načtení více sloupců, než kolik bylo dostupné v odpovídajícím indexu.
- Informace o viditelnosti nejsou udržovány spolu s daty indexu. Aby tedy bylo možné zkontrolovat viditelnost dat podle úrovně izolace, potřebuje přístup k datům haldy.
Nyní se můžeme divit, proč nepoužít indexové skenování vždy, když je tak efektivní. Takže jak víme, všechno něco stojí. Zde související náklady souvisí s typem I/O, který provádíme. V případě indexového skenování se jedná o náhodné I/O, protože pro každý záznam nalezený v indexovém úložišti musí načíst odpovídající data z úložiště HEAP, zatímco v případě sekvenčního skenování se jedná o sekvenční I/O, které zabere zhruba jen 25 % náhodného časování I/O.
Prohledávání indexu by tedy mělo být zvoleno pouze v případě, že celkový zisk převyšuje režijní náklady vzniklé v důsledku nákladů na náhodné I/O.
Podle výše uvedené tabulky a dat bude mít následující dotaz za následek skenování indexu, protože se vybírá pouze jeden záznam. Náhodné I/O je tedy méně a vyhledávání odpovídajícího záznamu je rychlé.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Skenování pouze indexu
Skenování pouze indexu je podobné skenování indexu s výjimkou druhého kroku, tj. jak název napovídá, prohledává pouze strukturu dat indexu. Existují dva další předpoklady pro volbu Index Only Scan ve srovnání s Index Scan:
- Dotaz by měl načítat pouze klíčové sloupce, které jsou součástí indexu.
- Všechny n-tice (záznamy) na vybrané stránce haldy by měly být viditelné. Jak bylo uvedeno v předchozí části, struktura dat indexu neuchovává informace o viditelnosti, takže abychom mohli vybrat data pouze z indexu, měli bychom se vyhnout kontrole viditelnosti, k čemuž by mohlo dojít, pokud jsou všechna data na dané stránce považována za viditelná.
Následující dotaz bude mít za následek pouze prohledání indexu. I když je tento dotaz téměř podobný, pokud jde o výběr počtu záznamů, ale protože se vybírá pouze klíčové pole (tj. „počet“), vybere možnost Index Only Scan.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Skenování bitmap
Skenování bitmap je kombinací skenování indexu a sekvenčního skenování. Snaží se vyřešit nevýhodu indexového skenování, ale stále si zachovává jeho plnou výhodu. Jak bylo diskutováno výše pro všechna data nalezená v datové struktuře indexu, potřebuje najít odpovídající data na stránce haldy. Alternativně tedy potřebuje jednou načíst indexovou stránku a poté následovat haldovou stránku, což způsobuje mnoho náhodných I/O. Metoda skenování bitmap tedy využívá výhody indexového skenování bez náhodných I/O. Funguje to ve dvou úrovních, jak je uvedeno níže:
- Bitmap Index Scan:Nejprve načte všechna data indexu z datové struktury indexu a vytvoří bitovou mapu všech TID. Pro jednoduché pochopení můžete zvážit, že tato bitmapa obsahuje hash všech stránek (hashovaný podle čísla stránky) a každý záznam stránky obsahuje pole všech offsetů na této stránce.
- Bitmap Heap Scan:Jak název napovídá, čte bitmapu stránek a poté skenuje data z haldy odpovídající uložené stránce a offsetu. Na konci zkontroluje viditelnost a predikát atd. a vrátí n-tici na základě výsledku všech těchto kontrol.
Následující dotaz bude mít za následek skenování bitmapy, protože nevybírá velmi málo záznamů (tj. příliš mnoho pro skenování indexu) a zároveň nevybírá velké množství záznamů (tj. příliš málo pro sekvenční skenovat).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Nyní zvažte níže uvedený dotaz, který vybírá stejný počet záznamů, ale pouze klíčová pole (tj. pouze indexové sloupce). Vzhledem k tomu, že vybírá pouze klíč, nemusí odkazovat na stránky haldy pro jiné části dat, a proto nejsou zapojeny žádné náhodné I/O. Tento dotaz tedy vybere Index Only Scan namísto Bitmap Scan.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)Skenování TID
TID, jak je uvedeno výše, je 6 bajtové číslo, které se skládá ze 4bajtového čísla stránky a zbývajících 2 bajtů indexu n-tice uvnitř stránky. Skenování TID je velmi specifický druh skenování v PostgreSQL a je vybráno pouze v případě, že v predikátu dotazu je TID. Zvažte níže uvedený dotaz demonstrující skenování TID:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Takže zde v predikátu se místo přesné hodnoty sloupce jako podmínky uvádí TID. Je to něco podobného jako vyhledávání založené na ROWID v Oracle.
Bonus
Všechny metody skenování jsou široce používané a známé. Tyto metody skenování jsou také dostupné téměř ve všech relačních databázích. V komunitě PostgreSQL se však nedávno diskutuje o jiné metodě skenování a nedávno byla přidána i do jiných relačních databází. V MySQL se nazývá „Loose IndexScan“, v Oracle „Index Skip Scan“ a v DB2 „Jump Scan“.
Tato metoda skenování se používá pro konkrétní scénář, kde je vybrána odlišná hodnota sloupce úvodního klíče indexu B-Stromu. V rámci tohoto skenování se vyhýbá procházení všech stejných hodnot klíčového sloupce, spíše jen procházení první jedinečné hodnoty a potom skoku na další velkou.
Tato práce stále probíhá v PostgreSQL s předběžným názvem „Index Skip Scan“ a můžeme očekávat, že to uvidíme v budoucí verzi.