Problémy se zpožděním replikace v PostgreSQL nejsou rozšířeným problémem pro většinu nastavení. I když k tomu může dojít, a když k němu dojde, může to ovlivnit vaše nastavení produkce. PostgreSQL je navržen tak, aby zpracovával více vláken, jako je paralelismus dotazů nebo nasazení pracovních vláken pro zpracování konkrétních úloh na základě přiřazených hodnot v konfiguraci. PostgreSQL je navržen tak, aby zvládal velké a stresující zátěže, ale někdy (kvůli špatné konfiguraci) může váš server jít na jih.
Identifikace zpoždění replikace v PostgreSQL není složitý úkol, ale existuje několik různých přístupů, jak se na problém podívat. V tomto blogu se podíváme na to, na co si dát pozor, když vaše replikace PostgreSQL zaostává.
Typy replikace v PostgreSQL
Než se ponoříme do tématu, podívejme se nejprve, jak se replikace v PostgreSQL vyvíjí, protože existují různé přístupy a řešení při řešení replikace.
Teplý pohotovostní režim pro PostgreSQL byl implementován ve verzi 8.2 (v roce 2006) a byl založen na způsobu odesílání protokolu. To znamená, že záznamy WAL se přímo přesouvají z jednoho databázového serveru na druhý, aby byly použity, nebo jednoduše analogický přístup k PITR, nebo velmi podobný tomu, co děláte s rsync.
Tento přístup, i když starý, se používá dodnes a některé instituce tento starší přístup ve skutečnosti preferují. Tento přístup implementuje odesílání protokolu založeného na souborech přenosem záznamů WAL po jednom souboru (segmentu WAL). I když to má nevýhodu; Závažná chyba na primárních serverech, transakce, které ještě nebyly odeslány, budou ztraceny. Je zde okno pro ztrátu dat (můžete to vyladit pomocí parametru archive_timeout, který lze nastavit až na několik sekund, ale takto nízké nastavení podstatně zvýší šířku pásma potřebnou pro odesílání souborů).
V PostgreSQL verze 9.0 byla zavedena replikace streamování. Tato funkce nám umožnila zůstat aktuálnější ve srovnání s odesíláním protokolů založených na souborech. Jeho přístup spočívá v přenosu záznamů WAL (soubor WAL se skládá ze záznamů WAL) za běhu (pouze protokoly založené na záznamech), mezi hlavním serverem a jedním nebo několika záložními servery. Tento protokol nemusí čekat na vyplnění souboru WAL, na rozdíl od odesílání protokolu založeného na souborech. V praxi se proces zvaný přijímač WAL, který běží na pohotovostním serveru, připojí k primárnímu serveru pomocí připojení TCP/IP. Na primárním serveru existuje další proces s názvem odesílatel WAL. Jeho role je zodpovědná za odesílání registrů WAL na záložní server(y), jakmile k nim dojde.
Nastavení asynchronní replikace ve streamingové replikaci může způsobit problémy, jako je ztráta dat nebo zpoždění slave, takže verze 9.1 zavádí synchronní replikaci. Při synchronní replikaci bude každé potvrzení transakce zápisu čekat, dokud není přijato potvrzení, že potvrzení bylo zapsáno do protokolu pro zápis na disk primárního i záložního serveru. Tato metoda minimalizuje možnost ztráty dat, protože k tomu potřebujeme, aby selhaly oba, hlavní i záložní, současně.
Zjevnou nevýhodou této konfigurace je, že doba odezvy pro každou transakci zápisu se zvyšuje, protože musíme čekat, dokud všechny strany nezareagují. Na rozdíl od MySQL zde není žádná podpora, jako například v semisynchronním prostředí MySQL dojde k návratu k selhání na asynchronní, pokud dojde k vypršení časového limitu. Takže v PostgreSQL je doba pro potvrzení (minimálně) zpáteční cesta mezi primárním a pohotovostním režimem. Transakce pouze pro čtení tím nebudou ovlivněny.
Jak se PostgreSQL vyvíjí, neustále se zlepšuje, a přesto je jeho replikace různorodá. Můžete například použít asynchronní replikaci fyzického streamování nebo použít replikaci logického streamování. Oba jsou monitorovány odlišně, ačkoli používají stejný přístup při odesílání dat přes replikaci, což je stále streamovaná replikace. Další podrobnosti naleznete v příručce pro různé typy řešení v PostgreSQL při práci s replikací.
Příčiny zpoždění replikace PostgreSQL
Jak je definováno v našem předchozím blogu, zpoždění replikace je cena zpoždění transakce (transakcí) nebo operace (operací) vypočítaná na základě jejich časového rozdílu provedení mezi primárním/masterem a pohotovostním/podřízeným uzel.
Protože PostgreSQL používá streamingovou replikaci, je navržena tak, aby byla rychlá, protože změny jsou zaznamenávány jako sada posloupností záznamů protokolu (bajt po bajtu) zachycených přijímačem WAL a poté tyto záznamy zapisuje do souboru WAL. Poté spouštěcí proces PostgreSQL přehraje data z tohoto segmentu WAL a začne streamovaná replikace. V PostgreSQL může dojít ke zpoždění replikace v důsledku těchto faktorů:
- Problémy se sítí
- Nelze najít segment WAL z primárního. Obvykle je to způsobeno chováním kontrolních bodů, kdy jsou segmenty WAL rotovány nebo recyklovány
- Vytížené uzly (primární a pohotovostní). Může to být způsobeno externími procesy nebo některými špatnými dotazy, které jsou náročné na zdroje
- Špatný hardware nebo hardwarové problémy způsobující určité zpoždění
- Špatná konfigurace v PostgreSQL, jako je malý počet nastavených max_wal_senderů při zpracování tuny transakčních požadavků (nebo velký objem změn).
Co hledat u PostgreSQL Replication Lag
Replikace PostgreSQL je ještě rozmanitá, ale sledování stavu replikace je jemné, ale ne komplikované. V tomto přístupu ukážeme, že jsou založeny na primárním pohotovostním nastavení s asynchronní replikací streamování. Logická replikace nemůže být přínosem pro většinu případů, o kterých zde diskutujeme, ale pohled pg_stat_subscription vám může pomoci shromáždit informace. Na to se však v tomto blogu nezaměříme.
Použití zobrazení pg_stat_replication
Nejběžnějším přístupem je spuštění dotazu odkazujícího na toto zobrazení v primárním uzlu. Pamatujte, že pomocí tohoto zobrazení můžete sbírat informace pouze z primárního uzlu. Toto zobrazení obsahuje následující definici tabulky založenou na PostgreSQL 11, jak je uvedeno níže:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Kde jsou pole definována jako (včetně verze PG <10),
- pid :ID procesu walsender procesu
- usesysid :OID uživatele, který se používá pro replikaci streamování.
- uživatelské jméno :Jméno uživatele, který se používá pro replikaci streamování
- název_aplikace :Název aplikace připojený k hlavnímu serveru
- client_addr :Adresa pohotovostní/streamovací replikace
- název_hostitele_klienta :Název hostitele pohotovostního režimu.
- client_port :Číslo TCP portu, na kterém pohotovostní režim komunikuje s odesílatelem WAL
- backend_start :Čas zahájení, když se SR připojí k Master.
- backend_xmin :horizont xmin pohotovostního režimu hlášený službou hot_standby_feedback.
- stav :Aktuální stav odesílatele WAL, tj. streamování
- sent_lsn /umístění_odeslané :Místo poslední transakce odesláno do pohotovostního režimu.
- write_lsn /umístění_zápisu :Poslední transakce zapsaná na disk v pohotovostním režimu
- flush_lsn /flush_location :Poslední vyprázdnění transakce na disk v pohotovostním režimu.
- replay_lsn /umístění_přehrání :Poslední vyprázdnění transakce na disk v pohotovostním režimu.
- write_lag :Uplynulý čas během potvrzených WAL z primárního do pohotovostního režimu (ale ještě nesplněno v pohotovostním režimu)
- flush_lag :Uplynulý čas během potvrzených WAL z primárního do pohotovostního režimu (WAL již byly vyprázdněny, ale ještě nebyly použity)
- replay_lag :Uplynulý čas během potvrzených WAL z primárního do pohotovostního režimu (plně potvrzeno v pohotovostním uzlu)
- sync_priority :Priorita serveru v pohotovostním režimu, který je vybrán jako synchronní pohotovostní režim
- sync_state :Stav synchronizace v pohotovostním režimu (je asynchronní nebo synchronní).
Ukázkový dotaz by v PostgreSQL 9.6 vypadal následovně
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncTo vám v podstatě říká, jaké bloky umístění v segmentech WAL byly zapsány, vyprázdněny nebo použity. Poskytuje vám podrobný přehled o stavu replikace.
Dotazy k použití v pohotovostním uzlu
V pohotovostním uzlu jsou podporovány funkce, u kterých to můžete zmírnit na dotaz a poskytnout vám přehled o stavu replikace v pohotovostním režimu. Chcete-li to provést, můžete spustit následující dotaz níže (dotaz je založen na verzi PG> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Ve starších verzích můžete použít následující dotaz:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Co dotaz říká? Funkce jsou zde odpovídajícím způsobem definovány,
- pg_is_in_recovery ():(boolean) True, pokud obnova stále probíhá.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) Umístění protokolu pro předběžný zápis přijaté a synchronizované na disk pomocí streamované replikace.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) Poslední umístění protokolu napřed přehrání během obnovy. Pokud obnova stále probíhá, bude se monotónně zvyšovat.
- pg_last_xact_replay_timestamp (): (časové razítko s časovým pásmem) Získejte časové razítko poslední transakce přehráno během obnovy.
Pomocí základní matematiky můžete tyto funkce kombinovat. Nejčastěji používané funkce, které používají správci databází, jsou,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
nebo ve verzích PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;I když tento dotaz byl v praxi a používají ho správci databází. Přesto vám neposkytuje přesný pohled na zpoždění. Proč? Probereme to v další sekci.
Identifikace zpoždění způsobeného absencí segmentu WAL
Pohotovostní uzly PostgreSQL, které jsou v režimu obnovy, vám nehlásí přesný stav toho, co se děje s vaší replikací. Pokud si neprohlédnete PG log, můžete sbírat informace o tom, co se děje. Neexistuje žádný dotaz, který byste mohli spustit, abyste to zjistili. Ve většině případů organizace a dokonce i malé instituce přicházejí se softwarem třetích stran, který jim umožňuje upozornit na poplach.
Jednou z nich je ClusterControl, která vám nabízí pozorovatelnost, odesílá upozornění, když se spustí alarm, nebo obnoví váš uzel v případě katastrofy nebo katastrofy. Vezměme si tento scénář, můj primární záložní asynchronní replikační cluster selhal. Jak můžeš vědět, že je něco špatně? Zkombinujme následující:
Krok 1:Zjistěte, zda došlo ke zpoždění
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Krok 2:Určení segmentů WAL přijatých z primárního a porovnání s pohotovostním uzlem
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70U starších verzí PG <10 použijte pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Zdá se, že to vypadá špatně.
Krok 3:Určete, jak špatné by to mohlo být
Nyní smícháme vzorec z kroku č. 1 a v kroku č. 2 a získáme rozdíl. Jak to udělat, PostgreSQL má funkci nazvanou pg_wal_lsn_diff, která je definována jako,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (umístění pg_lsn, umístění pg_lsn): (numerické) Vypočítejte rozdíl mezi dvěma umístěními protokolu pro zápis napřed
Nyní jej použijme k určení zpoždění. Můžete jej spustit v libovolném uzlu PG, protože poskytneme pouze statické hodnoty:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Pojďme odhadnout, kolik je 1800913104, což se zdá být asi 1,6GiB, mohlo chybět v pohotovostním uzlu,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Nakonec můžete pokračovat nebo se ještě před dotazem podívat na protokoly, například pomocí tail -5f sledovat a zkontrolovat, co se děje. Udělejte to pro oba primární/pohotovostní uzly. V tomto příkladu uvidíme, že má problém,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Když se setkáte s tímto problémem, je lepší znovu vytvořit pohotovostní uzly. V ClusterControl je to snadné jedním kliknutím. Stačí přejít do sekce Nodes/Topology a znovu vytvořit uzel stejně jako níže:
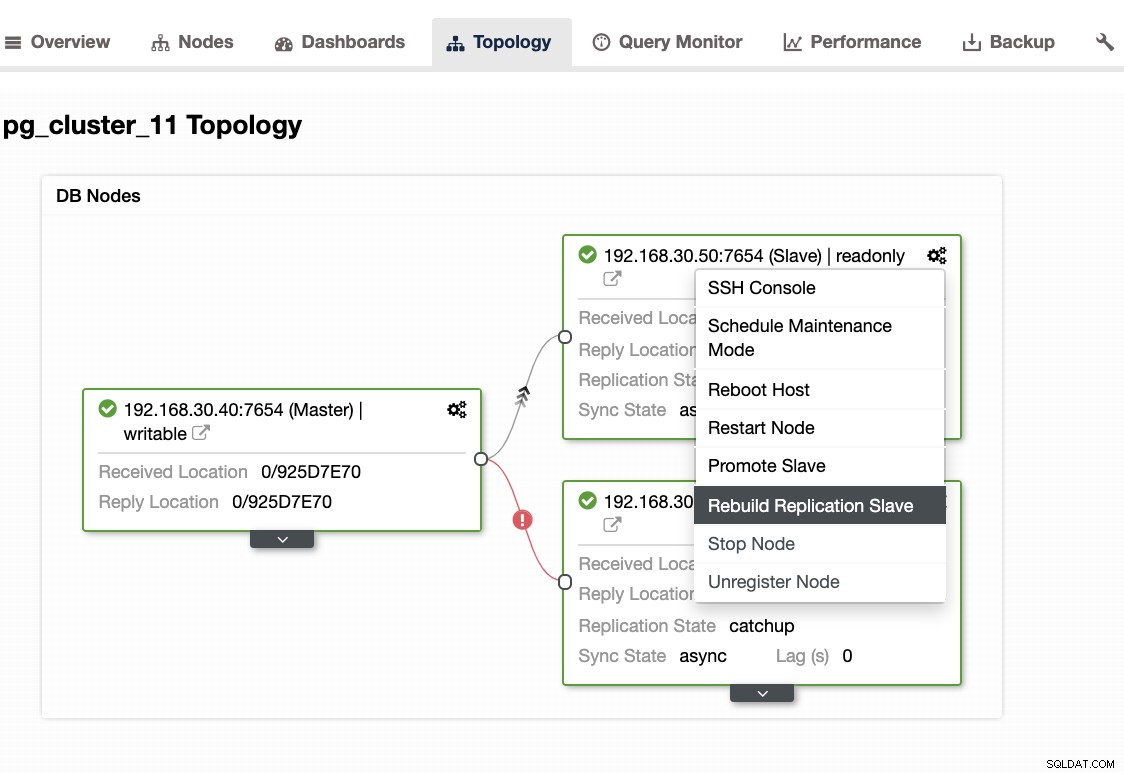
Další věci ke kontrole
Stejný přístup můžete použít v našem předchozím blogu (v MySQL) pomocí systémových nástrojů, jako je kombinace ps, top, iostat, netstat. Například můžete také získat aktuální obnovený segment WAL z pohotovostního uzlu
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Jak může ClusterControl pomoci?
ClusterControl nabízí efektivní způsob monitorování uzlů databáze od primárních po podřízené uzly. Při přechodu na kartu Přehled již máte zobrazení stavu replikace:
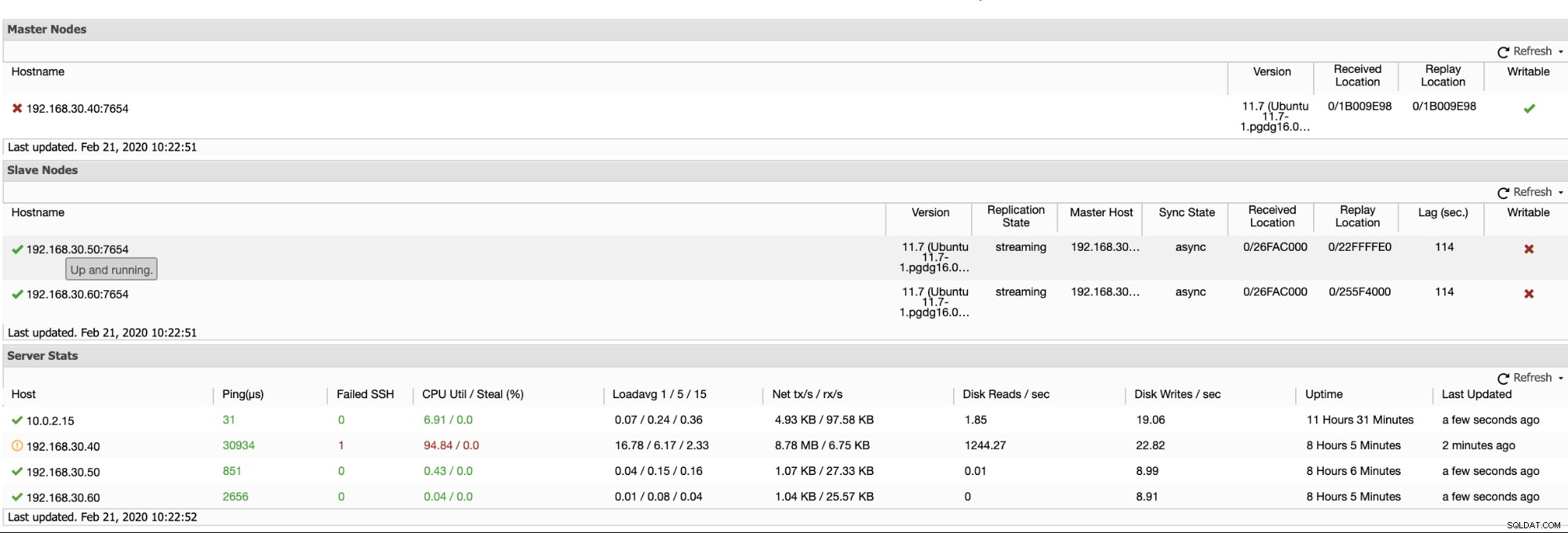
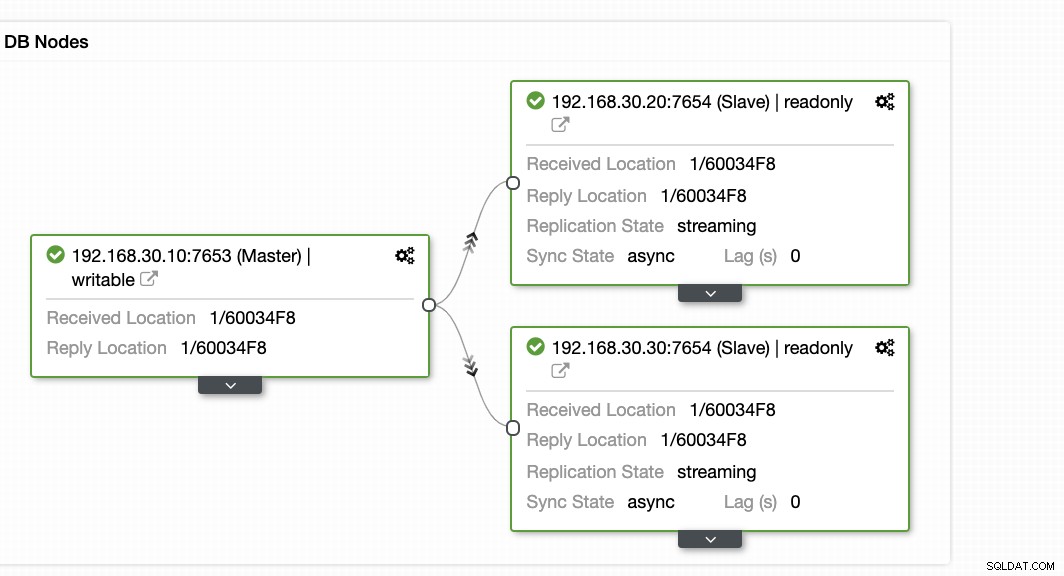
Oba výše uvedené snímky obrazovky v zásadě ukazují stav replikace a aktuální stav Segmenty WAL. To vůbec ne. ClusterControl také zobrazuje aktuální aktivitu toho, co se děje s vaším Clusterem.
Závěr
Monitorování stavu replikace v PostgreSQL může skončit jiným přístupem, pokud jste schopni vyhovět vašim potřebám. Použití nástrojů třetích stran s pozorovatelností, které vás mohou upozornit v případě katastrofy, je vaše perfektní cesta, ať už jde o open source nebo podnik. Nejdůležitější je, abyste měli plán obnovy po havárii a kontinuitu podnikání naplánovali ještě před podobnými problémy.